

![[Python] Python elasticsearch 模块入门](https://pic2.zhimg.com/v2-b89cfa4d53373e39dfe2a7cd4da0b94c_1440w.jpg?source=172ae18b)
[Python] Python elasticsearch 模块入门
前言
运维里很多操作都离不开日志,而ELK是现在企业里经常使用的日志收集和分析平台,开源,API完善,资源丰富,大家都爱它。elasticsearch,也就是ELK里的"E",是一个非常强大的搜索和分析引擎,并且提供了Python使用的模块,不过,略显遗憾的是,官方的文档中,很多API行为没有给出Python的代码示例,而且像很多Python库一样,这个模块的Python文档也是写的硬核无比,所以刚一上手,难免会有些摸不着头脑。
这篇旨在帮助那些和我一样刚上手用Python从elasticsearch获取数据的朋友。
安装及初始化
你已经不是Python菜鸟了,所以安装对你来说很容易
pip install elasticsearch在你的“游玩”代码中,导入最常使用的一个类,然后创建你的客户端实例
from elasticsearch import Elasticsearch
es = Elasticsearch(
{"host": "host1-ip-address", "port": port-number},
{"host": "host2-ip-address", "port": port-number},
{"host": "host3-ip-address", "port": port-number}
http_auth=("username", "secret"),
timeout=3600
)这里要小小吐槽的是,elasticsearch的客户端连接支持很多写法,非常的放飞自我,API文档的例子也是一团糟,我这里用了传入列表,然后列表里存了三个主机的字典的方法,我觉得这样看起来最清楚。你也可以 参考 这里 ,多试试,选一个你觉得舒服的写法。
到这里,实例就创建好了,接下来就是调用方法了。
作为使用者最常用的
search
方法
我作为一个使用者,用的最多的就是
search
方法,查数据。
search
方法接受的主要参数有——
-
index- 你要查询的索引 -
body- 查询的请求数据,DSL语法构成的json数据 -
filter_path- 返回过滤,避免返回一大堆不想要的
所以,例子——
res = es.search(index="test-inxex", filter_path="hits.hits._source.IPAddress", body=body)
这里的返回过滤就是json的层级结构,点号分开的4个都是
key
,最终我取出来的就是
IPAddress
这个
key
,这个
key
是个末节点,只有我需要的ip数据,没有别的了,看上去很舒服。
但是怎么才能知道你的数据的结构呢?最直接的办法就是借力ELK里面的K,Kibana,Kibana个很好的图形化平台,平常查日志,以及抄DSL语法,非常有用……
当然,直接先取出完整的数据,借助
pprint
这个模块打印一下,也能清楚看出结构(其实好像前两级一定是
hits
……)
再说
body
,这个东西是一个叫做DSL的语法,很讨厌,但是借力Kibana,可以直接抄……
比如我想要抓取特定时间段的所有日志,我可以在Kibana上先去查
然后在上图这个地方打开
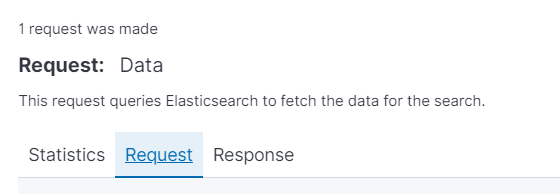

Request里就是它的请求数据
你可以抄其中最关键的部分,
主要就是
query
这个键值的的部分
,不过有个坑,就是
timestamp
,如果你输入的时间有问题,查出来的结果可能就不是想要的。
我 一般是查几分钟或者几小时之前 的数据,不太查具体的时间,对于这种,有个非常骚的操作,比如,我要查1小时之前的数据
{
"range": {
"@timestamp": {
"gte": "now-1h",
"lte": "now"
},
没错,
你可以传个字符串
"now"
进去,还可以做减法……
关于时间戳,可以 参考 这里
原文写的有点隐蔽,摘录如下
The expression starts with an anchor date, which can either benow, or a date string ending with||. This anchor date can optionally be followed by one or more maths expressions:
+1h: Add one hour
-1d: Subtract one day
/d: Round down to the nearest day
总而言之,我一般就抄Kibana的Request,然后timestamp注意一下。
关于时间戳的问题, 好好看 这里
过滤是有必要的,否则数据太多导致返回的数据被截断,你会发现查到的数据不准。除了过滤需要的数据外,设置
size
也可以。如下是查找所有,设置了
size
{
"size": 1000,
"query": {
"match_all": {}