

数据传输服务DTS(Data Transmission Service)支持将自建SQL Server同步至 云原生数据仓库AnalyticDB PostgreSQL版 ,帮助您轻松实现数据的传输,用于实时数据分析。
前提条件
- 自建SQL Server数据库支持的版本,请参见 同步方案概览 。
- 已创建目标 云原生数据仓库AnalyticDB PostgreSQL版 实例,如未创建请参见 创建实例 。
- 目标 云原生数据仓库AnalyticDB PostgreSQL版 实例的存储空间须大于自建SQL Server数据库占用的存储空间。
-
若源实例存在如下任一情况,建议使用RDS SQL Server数据库的备份功能进行同步,详情请参见
从自建数据库迁移至RDS
。
- 数据库超过10个。
- 单个数据库执行日志备份操作的频率超过1次/小时。
- 单个数据库执行DDL操作的频率超过100条/小时。
- 单个数据库的日志量超过20 MB/s。
- 需要开启CDC(Change Data Capture,变更数据捕获)的表超过1000个。
-
源库日志存在堆表、无主键表、压缩表、含计算列表等场景。可以执行如下SQL检查源库是否存在这些场景的表:
-
检查源库堆表信息:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id IN (SELECT object_id FROM sys.indexes WHERE index_id = 0); -
检查无主键表信息:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id NOT IN (SELECT parent_object_id FROM sys.objects WHERE type = 'PK'); -
检查源库聚集索引列包含的主键列信息:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id= t.schema_id WHERE t.type= 'U' AND s.name NOT IN('cdc', 'sys') AND t.name NOT IN('systranschemas') AND t.object_id IN (SELECT pk_columns.object_id AS object_id FROM (select sic.object_id object_id, sic.column_id FROM sys.index_columns sic, sys.indexes sis WHERE sic.object_id= sis.object_id AND sic.index_id= sis.index_id AND sis.is_primary_key= 'true') pk_columns LEFT JOIN (SELECT sic.object_id object_id, sic.column_id FROM sys.index_columns sic, sys.indexes sis WHERE sic.object_id= sis.object_id AND sic.index_id= sis.index_id AND sis.index_id= 1) cluster_colums ON pk_columns.object_id= cluster_colums.object_id WHERE pk_columns.column_id != cluster_colums.column_id); -
检查源库压缩表信息:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.objects t, sys.schemas s, sys.partitions p WHERE s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id = p.object_id AND p.data_compression != 0; -
检查包含计算列表信息:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id IN (SELECT object_id FROM sys.columns WHERE is_computed = 1);
-
检查源库堆表信息:
注意事项
- 在库表结构同步过程中,DTS会将源数据库中的外键同步到目标数据库。
- 在全量同步和增量同步过程中,DTS会以Session级别暂时禁用约束检查以及外键级联操作。若任务运行时源库存在级联更新、删除操作,可能会导致数据不一致。
| 类型 | 说明 |
|---|---|
| 源库限制 |
|
| 其他限制 |
|
费用说明
| 同步类型 | 链路配置费用 |
|---|---|
| 库表结构同步和全量数据同步 | 不收费。 |
| 增量数据同步 | 收费,详情请参见 计费概述 。 |
支持的同步架构
- 一对一单向同步
- 一对多单向同步
- 多对一单向同步
支持同步的SQL操作
| 操作类型 | SQL操作语句 |
|---|---|
| DML | INSERT、UPDATE、DELETE |
| DDL |
说明
|
数据库账号的权限要求
| 数据库 | 所需权限 | 账号创建及授权方法 |
|---|---|---|
| 自建SQL Server | sysadmin | CREATE USER 和 用户权限管理 |
| 云原生数据仓库AnalyticDB PostgreSQL版 实例 |
说明
您也可以使用
AnalyticDB PostgreSQL
的初始账号。
|
创建数据库账号 和 用户权限管理 |
准备工作
在正式配置数据同步任务之前,需要在自建SQL Server数据库上进行日志配置并创建聚集索引。-
在自建SQL Server数据库中执行如下命令,将待同步的数据库恢复模式修改为完整模式。也可通过SSMS客户端修改,具体请参见
修改数据库的recovery mode
。
参数说明:use master; ALTER DATABASE <database_name> SET RECOVERY FULL WITH ROLLBACK IMMEDIATE; GO<database_name>:待同步的数据库名。
示例:use master; ALTER DATABASE mytestdata SET RECOVERY FULL WITH ROLLBACK IMMEDIATE; GO
BACKUP DATABASE <database_name> TO DISK='<physical_backup_device_name>';
GO- <database_name>:待同步的数据库名。
- <physical_backup_device_name>:指定备份文件存储的路径和文件名。
BACKUP DATABASE mytestdata TO DISK='D:\backup\dbdata.bak';
GOBACKUP LOG <database_name> to DISK='<physical_backup_device_name>' WITH init;
GO- <database_name>:待同步的数据库名。
- <physical_backup_device_name>:指定备份文件存储的路径和文件名。
BACKUP LOG mytestdata TO DISK='D:\backup\dblog.bak' WITH init;
GO操作步骤
-
登录
新版DTS同步任务的列表页面
。
说明 您也可以登录 DMS数据管理服务 。在顶部菜单栏中,选择 集成与开发(DTS) ,在左侧导航栏选择 。
- 在页面左上角,选择同步实例所属地域。
-
单击
创建任务
,配置源库及目标库信息。
类别 配置 说明 无 任务名称 DTS会自动生成一个任务名称,建议配置具有业务意义的名称(无唯一性要求),便于后续识别。
源库信息 数据库类型 选择 SQL Server 。 接入方式 选择 ECS自建数据库 。 实例地区 选择自建SQL Server数据库所属地域。 ECS实例ID 选择自建SQL Server数据库所属ECS实例ID。 数据库账号 填入自建SQL Server数据库账号,所需权限,请参见 数据库账号的权限要求 。 数据库密码 填入该数据库账号对应的密码。
连接方式 根据需求选择 非加密连接 或 SSL安全连接 。
目标库信息 数据库类型 选择 AnalyticDB PostgreSQL 。 接入方式 选择 云实例 。 实例地区 选择目标 AnalyticDB PostgreSQL 实例所属地域。 实例ID 选择目标 AnalyticDB PostgreSQL 实例ID。 数据库名称 填入目标 AnalyticDB PostgreSQL 实例中同步对象所属数据库的名称。 数据库账号 填入目标 AnalyticDB PostgreSQL 实例的数据库账号,所需权限,请参见 数据库账号的权限要求 。 数据库密码 填入该数据库账号对应的密码。
-
配置完成后,单击页面下方的
测试连接以进行下一步
。
说明
- 如果源或目标数据库是阿里云数据库实例(例如 RDS MySQL 、 云数据库MongoDB版 等)或ECS上的自建数据库,DTS会自动将对应地区DTS服务的IP地址添加到阿里云数据库实例的白名单或ECS的安全规则中,您无需手动添加,请参见 DTS服务器的IP地址段 ;如果源或目标数据库是IDC自建数据库或其他云数据库,则需要您手动添加对应地区DTS服务的IP地址,以允许来自DTS服务器的访问。
-
DTS任务完成或释放后,建议您手动删除添加的DTS服务的IP地址。在阿里云数据库实例的白名单或ECS的安全规则中,您需要删除名称包含
dts的IP白名单分组;在IDC自建数据库或其他云数据库,您需要删除的DTS服务的IP地址,请参见 DTS服务器的IP地址段 。
-
配置任务对象及高级配置。
-
基础配置
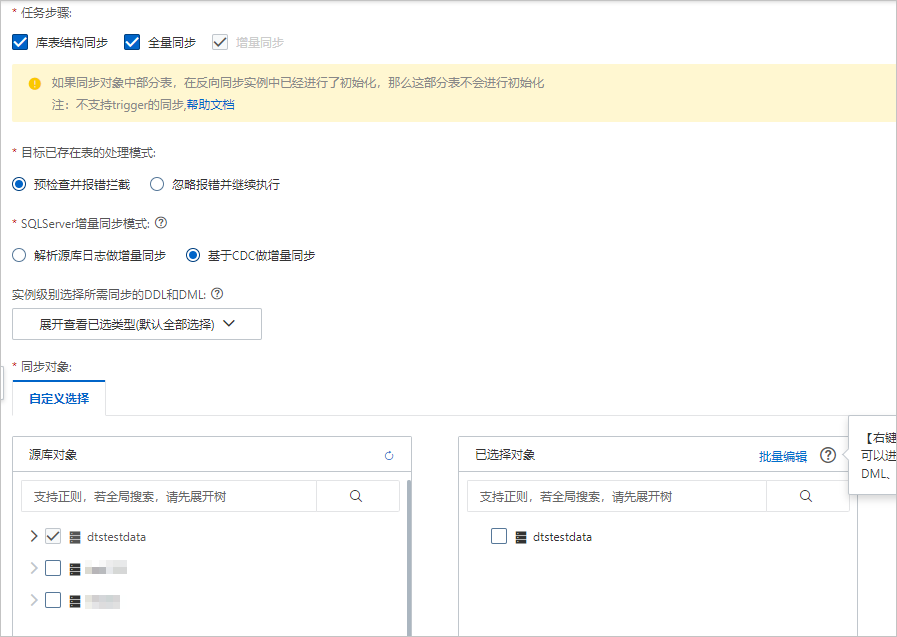
配置 说明 同步类型 固定选中 增量同步 。默认情况下,您还需要同时选中 库表结构同步 和 全量同步 。预检查完成后,DTS会将源实例中待同步对象的全量数据在目标集群中初始化,作为后续增量同步数据的基线数据。
目标已存在表的处理模式 -
预检查并报错拦截 :检查目标数据库中是否有同名的表。如果目标数据库中没有同名的表,则通过该检查项目;如果目标数据库中有同名的表,则在预检查阶段提示错误,数据同步任务不会被启动。
说明 如果目标库中同名的表不方便删除或重命名,您可以更改该表在目标库中的名称,请参见 库表列名映射 。 -
忽略报错并继续执行
:跳过目标数据库中是否有同名表的检查项。
警告 选择为 忽略报错并继续执行 ,可能导致数据不一致,给业务带来风险,例如:
-
表结构一致的情况下,如在目标库遇到与源库主键的值相同的记录:
- 全量期间,DTS会保留目标集群中的该条记录,即源库中的该条记录不会同步至目标数据库中。
- 增量期间,DTS不会保留目标集群中的该条记录,即源库中的该条记录会覆盖至目标数据库中。
- 表结构不一致的情况下,可能会导致无法初始化数据、只能同步部分列的数据或同步失败。
-
表结构一致的情况下,如在目标库遇到与源库主键的值相同的记录:
实例级别选择所需同步的DDL和DML 按实例级别选择同步的DDL或DML操作,支持的同步操作,请参见 支持同步的SQL操作 。 说明 如需按库或表级别选择同步的SQL操作,请在 已选择对象 中右击同步对象,在弹跳框中勾选所需同步的SQL操作。SQLServer增量同步模式 -
非堆表用日志解析增量同步,堆表用CDC增量同步
:
-
优点:
- 支持源库堆表、无主键表、压缩表、含计算列表等场景。
- 链路稳定性较高。能拿到完整的DDL语句,DDL场景支持丰富。
-
缺点:
DTS会在源库中创建触发器dts_cdc_sync_ddl、心跳表dts_sync_progress、DDL存储表dts_cdc_ddl_history以及会开启库级别CDC和部分表CDC。
-
优点:
-
解析源库日志做增量同步
:
-
优点:
对源库无侵入。
-
缺点:
不支持源库堆表、无主键表、压缩表、含计算列表等场景。
-
优点:
同步对象 在 源库对象 框中单击待同步对象,然后单击
 将其移动至
已选择对象
框。
说明 本场景为异构数据库间同步,因此同步对象选择的粒度为表,且其他对象(如视图、触发器、存储过程)不会被同步至目标库。
将其移动至
已选择对象
框。
说明 本场景为异构数据库间同步,因此同步对象选择的粒度为表,且其他对象(如视图、触发器、存储过程)不会被同步至目标库。映射名称更改 过滤待同步数据 支持设置WHERE条件过滤数据,请参见 通过SQL条件过滤任务数据 。
同步的SQL操作 请右击 已选择对象 中的同步对象,在弹跳框中选择所需同步的DML和DDL操作,支持的操作,请参见 支持同步的SQL操作 。 -
-
高级配置
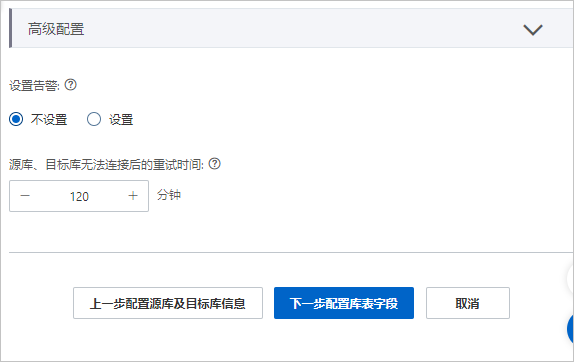
配置 说明 设置告警 是否设置告警,当同步失败或延迟超过阈值后,将通知告警联系人。- 不设置 :不设置告警。
- 设置 :设置告警,您还需要设置告警阈值和告警联系人。更多信息,请参见 在配置任务过程中配置监控报警 。
源库、目标库无法连接后的重试时间 在同步任务启动后,若源库或目标库连接失败则DTS会报错,并会立即进行持续的重试连接,默认持续重试时间为720分钟,您也可以在取值范围(10~1440分钟)内自定义重试时间,建议设置30分钟以上。如果DTS在设置的重试时间内重新连接上源库、目标库,同步任务将自动恢复。否则,同步任务将会失败。说明- 针对同源或者同目标的多个DTS实例,如DTS实例A和DTS实例B,设置网络重试时间时A设置30分钟,B设置60分钟,则重试时间以低的30分钟为准。
- 由于连接重试期间,DTS将收取任务运行费用,建议您根据业务需要自定义重试时间,或者在源和目标库实例释放后尽快释放DTS实例。
-
基础配置
-
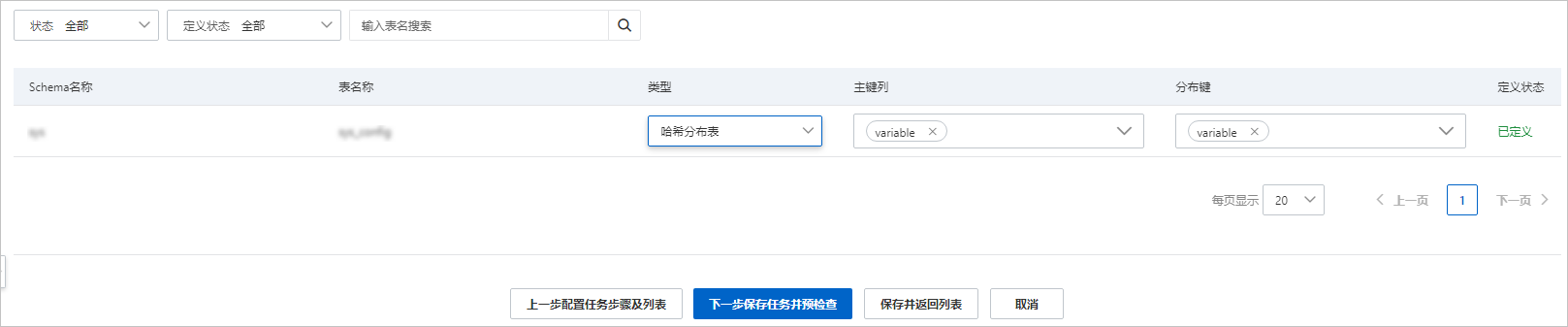
上述配置完成后,单击页面下方的
下一步配置库表字段
,设置待同步的表在目标
AnalyticDB PostgreSQL
中的主键列和分布列信息。
-
上述配置完成后,单击页面下方的
下一步保存任务并预检查
。
说明
- 在同步作业正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动同步作业。
- 如果预检查失败,请单击失败检查项后的 查看详情 ,并根据提示修复后重新进行预检查。
-
如果预检查产生警告:
- 对于不可以忽略的检查项,请单击失败检查项后的 查看详情 ,并根据提示修复后重新进行预检查。
- 对于可以忽略无需修复的检查项,您可以依次单击 点击确认告警详情 、 确认屏蔽 、 确定 、 重新进行预检查 ,跳过告警检查项重新进行预检查。如果选择屏蔽告警检查项,可能会导致数据不一致等问题,给业务带来风险。
- 预检查通过率 显示为 100% 时,单击 下一步购买 。
-
在
购买
页面,选择数据同步实例的计费方式、链路规格,详细说明请参见下表。
类别 参数 说明 信息配置 计费方式 - 预付费(包年包月):在新建实例时支付费用。适合长期需求,价格比按量付费更实惠,且购买时长越长,折扣越多。
- 后付费(按量付费):按小时扣费。适合短期需求,用完可立即释放实例,节省费用。
链路规格 DTS为您提供了不同性能的同步规格,同步链路规格的不同会影响同步速率,您可以根据业务场景进行选择,详情请参见 数据同步链路规格说明 。 订购时长 在预付费模式下,选择包年包月实例的时长和数量,包月可选择1~9个月,包年可选择1~3年。 说明 该选项仅在付费类型为 预付费 时出现。 - 配置完成后,阅读并勾选 《数据传输(按量付费)服务条款》 。
- 单击 购买并启动 ,同步任务正式开始,您可在数据同步界面查看具体任务进度。