


数据分析基本过程

一维数据

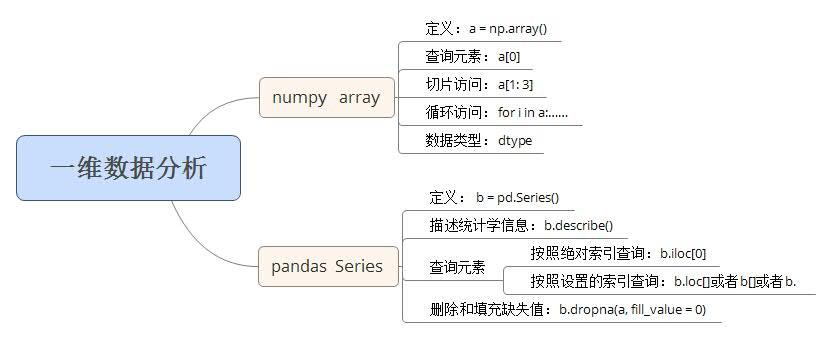
二维数据:

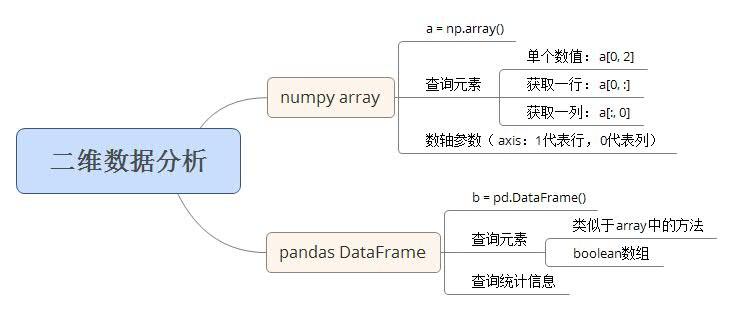
关于numpy和pandas的学习肯定是不止这些,目前位置,只做了 numpy学习笔记 ,pandas的功能太多,只留下一个学习的ipynb文件 学习记录 。
然后是通过一个医疗的实例来体验数据分析,并且在其中使用刚刚讲到的Python库的知识。
数据分析过程:


一 提出问题
月均消费次数、月均消费金额、客单价、消费趋势
二 理解数据
购药时间、社保卡号、商品编码、商品名称、销售数量、应收金额、实收金额
#导入excel文件
In [149]:
import xlrd
fileName = '/lovefat/第4关数据分析的基本过程/朝阳医院2018年销售数据.xlsx'
xls = pd.ExcelFile(fileName)
salesDf = xls.parse('Sheet1')
#DataFrame的形状(几行几列)
In [153]:salesDf.shape
Out[153]:(6578, 7)
#每一行的类型
In [162]:salesDf.dtypes
Out[162]:
购药时间 object
社保卡号 float64
商品编码 float64
商品名称 object
销售数量 float64
应收金额 float64
实收金额 float64
dtype: object
#对某一列的概率学分析
In [160]:col = salesDf['应收金额']
In [161]:col.describe()
Out[161]:
count 6577.000000
mean 50.473803
std 87.595925
min -374.000000
25% 14.000000
50% 28.000000
75% 59.600000
max 2950.000000
Name: 应收金额, dtype: float64三 数据清洗


1.选择子集(这个案例使用的是全部数据);
2.列名重命名
#将购药时间一列改为销售时间
colNameDict = {'购药时间':'销售时间'}
salesDf.rename(columns=colNameDict, inplace=True)
#inplace是直接改变原始数据,False则是重新创建一个新的数据框3.缺失数据处理
实际中的数据不会完全按照很标准的样子列举,这就需要我们对其进行初始化。
处理方法:
(1)直接删除(这里采用的方法)
(2)如果差值很多,可以通过机器学习中的方法,建立模型,进行差值的方法来进行计算。
#开始数据集的行数
print(salesDf.shape)
#只要一行中有缺失值就删除整行
salesDf = salesDf.dropna(subset=['销售时间', '社保卡号'], how='any')
#处理之后数据集的行数
print(salesDf.shape)
(6578, 7)
(6575, 7)如果想要添加值的话,可以使用fillna方法。
4.数据类型转化
因为传入的数据类型默认都是字符串类型,而字符串是不能进行计算的。同时一些列的数据明显就是数字类型,比如销售金额,销售数量等。所以进行数据类型转化是必不可少的。
(1)数据类型转化
#字符串转换为数值(浮点型)
salesDf['销售数量'] = salesDf['销售数量'].astype('float')
salesDf['应收金额'] = salesDf['应收金额'].astype('float')
salesDf['实收金额'] = salesDf['实收金额'].astype('float')
print('转换后的数据类型:\n',salesDf.dtypes)
转换后的数据类型:
销售时间 object
社保卡号 object
商品编码 object
商品名称 object
销售数量 float64
应收金额 float64
实收金额 float64
dtype: object(2)对时间格式的转化:
本来的时间格式是“2018-01-01 星期五”,星期对于我们是没有意义的,所以我们想要将日期格式转化为只有时间的格式。
转换的方法如下:
In [232]:salesDf['销售时间'][0].split(' ')[0]
Out[232]:'2018-01-01'通过定义方法将整列的数据都进行转化,函数如下:
def splitSalestime(timeColSer):
timeList = []
for i in testList:
value = i.split(' ')[0]
timeList.append(value)
spt = pd.Series(timeList)
return spt显示样式进行转化:
salesTimes = salesDf['销售时间']
spt = splitSalestime(salesTimes)
salesDf['销售时间'] = spt最后转换时间的格式:
#fomat是为了匹配数据的格式,errors是为了防止有时间的格式不符合规定的样式
salesDf['销售时间'] = pd.to_datetime(salesDf['销售时间'],
format='%Y-%m-%d',
errors='coerce')
#经过修改后的时间类型就是datetime类型
salesDf.dtypes
销售时间 datetime64[ns]
社保卡号 float64
商品编码 float64
商品名称 object
销售数量 float64
应收金额 float64
实收金额 float64
dtype: object5.排序
salesDf = salesDf.sort_values('销售时间', ascending=True)
salesDf.head()
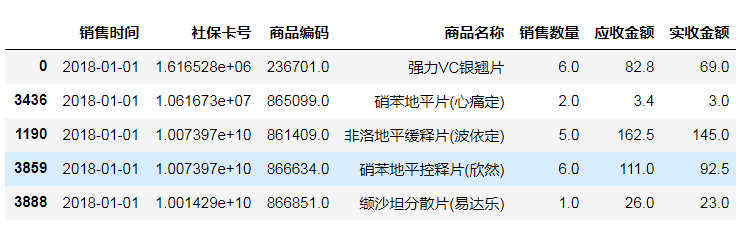
这时候所有的数据会按照时间先后顺序排列,但是可以看到索引并没有改变,还是排序前每一列的索引。
#重命名行名
salesDf = salesDf.reset_index(drop=True)
salesDf.head()
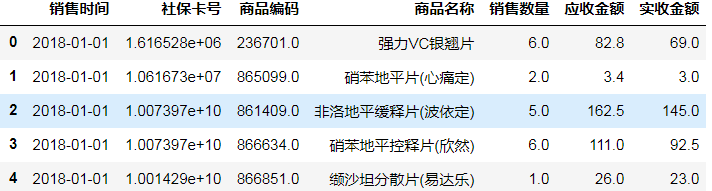
6.异常值处理
按照之前学习的内容,找到异常值。 概率相关知识
异常值的类型:
1.被错误记录的数据,如果是这样,进一步分析之前需要更正;
2.被错误包含在数据集的观测值,如果是这样,则可以把它删除;
3.反常的数据值,属于被正常记录并且属于数据集,应该被保留。

将所有销售数量小于零的异常值去除
boolSer = salesDf['销售数量']>=0
print(salesDf.shape)
salesDf =salesDf[boolSer]
print(salesDf.shape)特别的尝试:
以上是live中关于数据清洗的前三步,但是我想到之前讲到的关于异常值处理的四分位数相关方法,想要对数据再次进行一次异常值去除操作。
def removeOutlier(columns):
Q1 = columns.quantile(.25)
Q3 = columns.quantile(.75)
IQR = Q3 - Q1
topLimit = Q3 + IQR
bottomLimit = Q1 - IQR
colSer = []
columns = list(columns)
for value in columns:
bool = (value>bottomLimit) & (value<topLimit)
if bool:
colSer.append(True)
else:
colSer.append(False)
return colSer这个函数是为了得到判断某一列中是否每个数据都是在极值范围内,在的话返回True,反之返回False
df = salesDf
print(df.shape)
colSer = removeOutlier(df['应收金额'])
df = df[colSer]
#df['实收金额'] = removeOutlier(df['实收金额'])
print(df.shape)
(6506, 7)
(5848, 7)经过数据处理可以看到,处理前后的行数是有变化的。
虽然在这个例子中,四分位数判断异常值的方法,没有太大的实际意义,这里我只是想试试用python来实现的操作,可能以后会用得上。
四 构建模型
月均消费次数、月均消费金额、客单价、消费趋势是第一步中提出的问题
1.月均消费次数
月均消费次数=总消费次数 / 月份数
总消费次数:
kpi1_Df=salesDf.drop_duplicates(subset=['销售时间', '社保卡号'])
totalI=kpi1_Df.shape[0]
print('总消费次数=',totalI)
总消费次数= 5342月份数:
startTime=kpi1_Df.loc[0,'销售时间']
endTime=kpi1_Df.loc[totalI-1,'销售时间']
daysI=(endTime-startTime).days
monthsI=daysI//30
print('月份数:',monthsI)
月份数: 6月消费次数:
kpi1_I=totalI // monthsI
print('月均消费次数=',kpi1_I)
月均消费次数= 8902.月均消费金额 = 总消费金额 / 月份数
totalMoneyF=salesDf.loc[:,'实收金额'].sum()
monthMoneyF=totalMoneyF / monthsI