


Linux操作:正则表达式


我们已经知道,文本数据在类 UNIX 系统中(比如Linux)扮演着非常重要的角色。但是,在领略这些工具强大的功能前,我们还是先看一下经常与这些工具的复杂用法相关联的技术——正则表达式。
前面我们已经接触过命令行提供的许多特性和工具,并且也遇到过一些相当神秘的shell特性及命令,比如shell扩展和引用、键盘快捷键和命令历史记录等,更不用提vi编辑器了。正则表达式也延续了这种传统,而且可以说是众多特性中最神秘的一个(该说法应该会持有争议)。当然,并不是说这些特性不值得大家花时间去学习。恰恰相反,熟练掌握这些用法会给人意想不到的效果,尽管它们的全部价值可能不会立即体现出来。
1 什么是正则表达式
简单地说,正则表达式是一种符号表示法,用于识别文本模式。在某种程度上,它们类似于匹配文件和路径名时使用的shell通配符,但其用途更广泛。许多命令行工具和大多数编程语言都支持正则表达式,以此来解决文本操作方面的问题。然而,在不同的工具,以及不同的编程语言之间,正则表达式都会略有不同,这让事情进一步麻烦起来。方便起见,我们将正则表达式的讨论限定在POSIX标准中(它涵盖了大多数命令行工具),与许多编程语言(最著名的Perl)不同,这些编程语言使用的符号集要更多一些。
2 grep——文本搜索
我们用来处理正则表达式的主要程序是grep。grep名字源于 “global regular expression print”,由此也可以看到,grep与正则表达式有关。实际上,grep搜索文本文件中与指定正则表达式匹配的行,并将结果送至标准输出。
前为止,我们我们已经利用grep搜索了固定的字符串,如下所示:
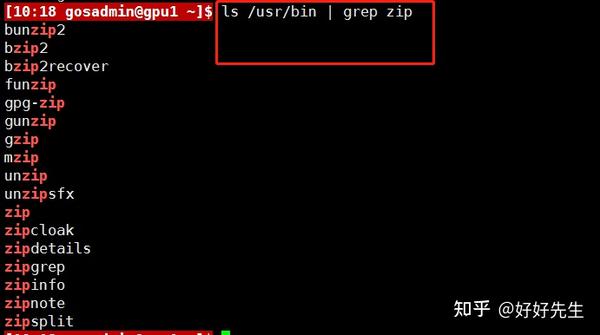

该命令行的作用是列出/usr/bin目录下文件名包含zip字符串的所有文件。
grep程序按照如下方式接受选项和参数。
grep [options] regex [file……]
其中字符串regex代表的是某个正则表达式。
表19-1列出了grep常用的选项。


为了更为全面地了解grep,我们创建几个文本文件来进行搜索。
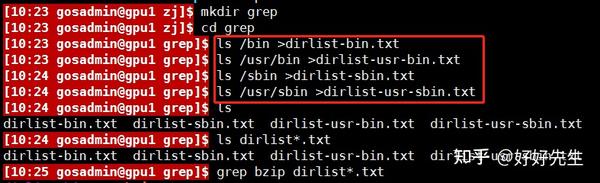

我们可以对文件列表执行简单搜索,如下所示。


本例中,grep命令会搜索所所有的文件,以查找字符串bzip,并找到了两个匹配项,而且这两个匹配项都在文件dirlist-bin.txt里。如果我们只对包含匹配项的文件感兴趣而不是对匹配项本身感兴趣,可以指定?l选项。


相反,如果那只想查看那些不包含匹配项的文件,则可以用如下命令行。


3 元字符和文字
虽然看起来不是很明显,但grep搜索一直都在使用正则表达式,尽管那些例子都很简单。 正则表达式bzip用于匹配文本中至少包含4个字符、存在连续的按b、z、i、p顺序组成的字符串的行。字符串bzip中的字符都是文字字符(literal character),即它们只能与自身进行匹配。 除了文字字符,正则表达式还可以包含用于指定更为复杂的匹配的元字符。正则表达式的元字符包括以下字符。
^ $ .[ ] { } -?* + ( ) | \
其他所有字符则被当作文字字符,但是在极少数的情况下,反斜杠字符用来创建元序列,以及用来对元字符进行转义,使其成为文字字符,而再被解释为元字符。
可以看到,当shell在执行扩展时,许多正则表达式的元字符在shell中具有特殊的含义。所以,在命令行中输入包含元字符的正则表达式时,应把这些元字符用引号括起来以避免不必要的shell扩展
4 任意字符
接下来讨论的第一个元字符是“点”字符或者句点字符,该字符用于匹配任意字符。如果将其加进某个正则表达式中,它将会在对应位置匹配任意字符。下面就是一个应用实例。
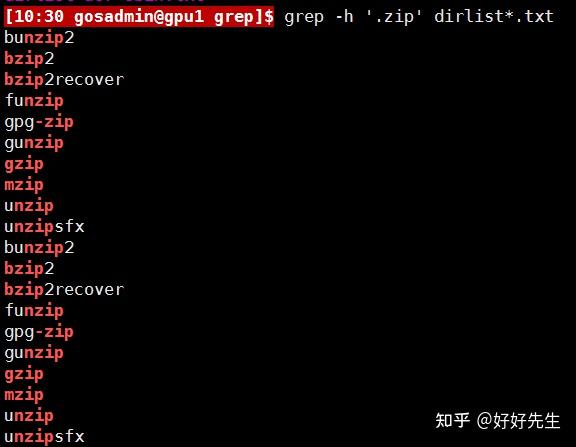

上述命令行,搜索到了所有匹配正则表达式.zip的命令行。但其输出结果有一些有趣的地方,比如说输出中并没有包上述命令行,搜索到了所有匹配正则表达式.zip的命令行。但其输出结果有一些有趣的地方,比如说输出中并没有包含zip程序, 这是因为正则表达式中的“·”元字符将匹配长度增加到了4个字符。而“zip”只包含了3个字符,所以不匹配。同样,如果列表中某个文件包含了文件扩展名“.zip”,那么该文件也会被认为是匹配文件,因为文件扩展名中的“.”符号也被当作“任意字符”处理了。
5 锚
插入符(^)和美元符号($)在正则表达式被当做锚,也就是说正则表达式只与行的开头(^)或是末尾($)的内容进行匹配比较。
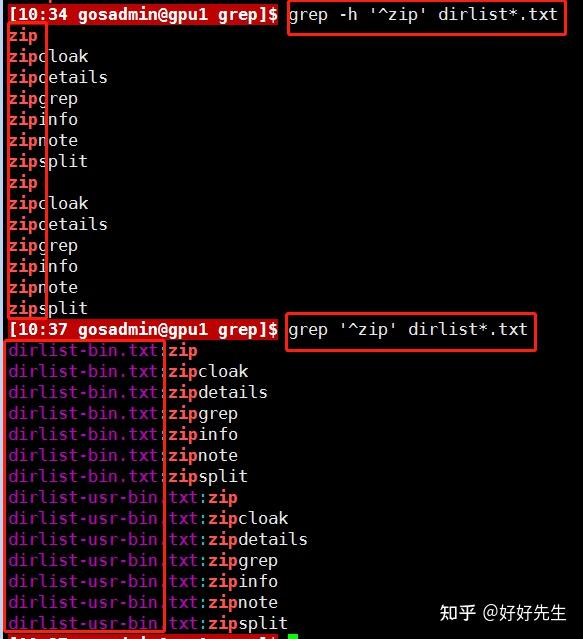

上例中搜索的是行开头、行末尾都有字符串“zip”(例如zip自成一行)的文件。请注意,正则表达式“^$”(行开头和行末尾之间没有字符)将会匹配空行。
纵横填字字谜助手
我的妻子很喜欢玩纵横填字字谜这个游戏,并且有时她会拿一个具体问题向我寻求帮助。诸如“有一个5个字母的单词,它的第三个字母是j,最后一个字母是r,请问这是什么单词?”等等,这类问题不得不让我思考。
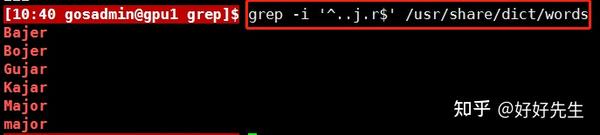
你们知道Linux系统本身自带一个字典吗?查看/usr/share/dict目录,就会发现一个或是多个这样的你们知道Linux系统本身自带一个字典吗?查看/usr/share/dict目录,就会发现一个或是多个这样的字典。字典中的文件包含的是一个常常的单词列表,每个单词占一行,以字母表的顺序排列。在我自己的系统上,单词文件中包含了超过98,500个单词。可以输入如下命令行,得到上述字谜问题的可能答案:

6 中括号表达式和字符类
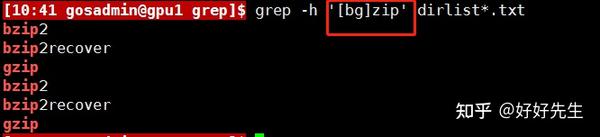
中括号除了可以用于匹配正则表达式中给定位置的任意字符外,还可以用于匹配指定字符集中的单个字符。借助于中括号,我们可以指定要匹配的字符集(也包括那些可能会被解释为元字符的字符)。如下命令行则利 用了一个两个字母组成的字符集 ,用于匹配包含bzip或gzip字符串的文本行。

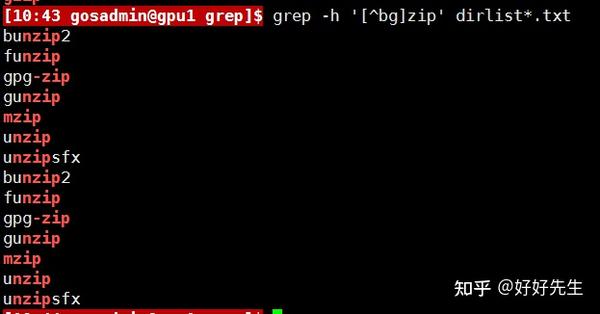
一个字符集可以包含任意数目的字符,并且当元字符放置到中括号中时,会失去它们的特殊含义。然而,在两种情况下,则会在中括号中使用元字符,并且会有不同的含义 。第一个就是插入符(^),它在中括号内使用表示否定;另外一个是连字符(-),它表示字符范围 。

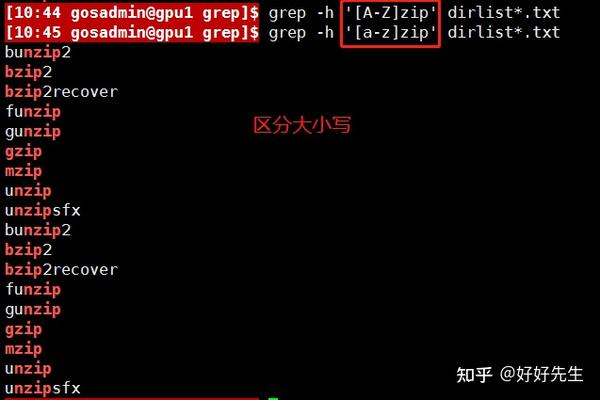

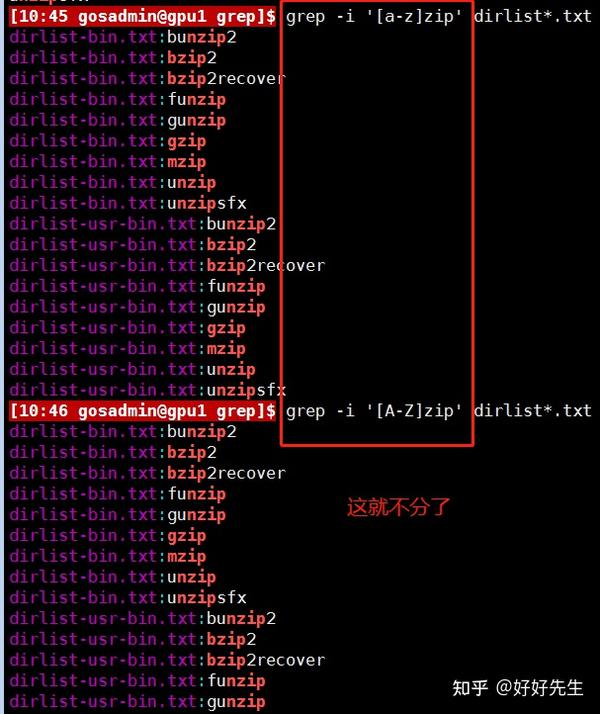

如果我们希望建立一个正则表达式,用于查找文件名以大写字母开头的文件,可以用下面的命令行。
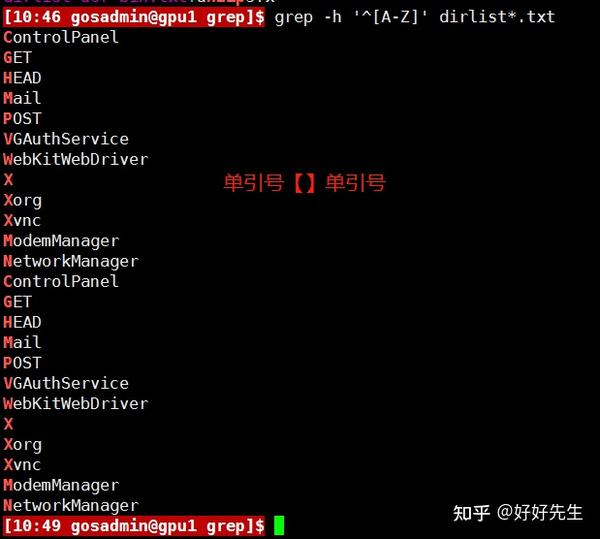

通过使用三个字符表示的字符范围,我们可以缩写这26个字母。能够按照这种方式表达的任何字符范围可以包含多个范围,比如下面这个表达式可以匹配以字母和数字开头的所有文件名。
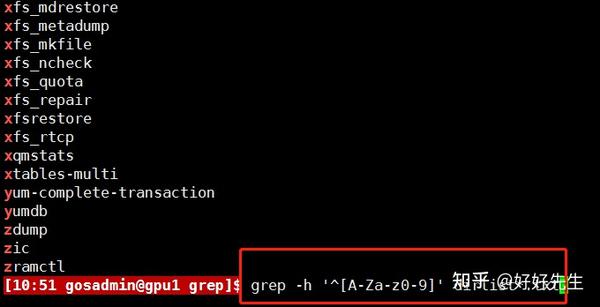

文件名包含连字符、大写字母A或大写字母Z的文件。
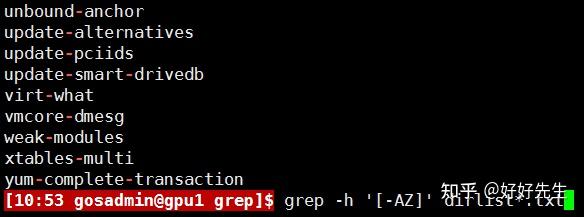

POSIX字符类


恢复为传统的排列顺序
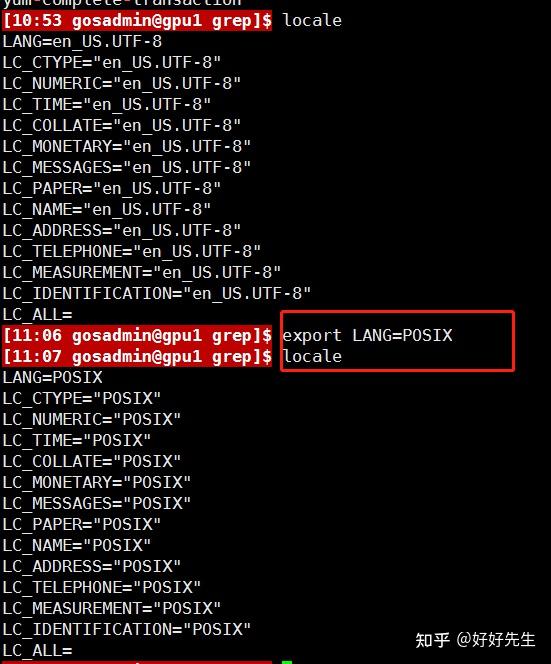
你可以设置自己的系统采用传统的(ASCII)字符顺序,方法就是改变LANG环境变量的值。LANG变量包含语言的名称以及该语言环境中使用的字符集,该参数值在安装Linux系统选择安装语言时就已经设定。
要查看环境设置,使用下面的locale命令。
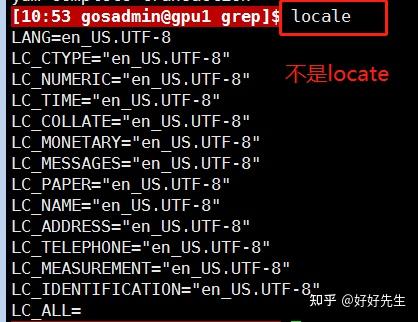
将环境设置为使用传统的UNIX行为,可将LANG变量值设为POSIX:
[me@linuxbox ~]$export LANG=POSIX
请注意,这样的改变将会导致系统使用美式英语(更精确地说,是ASCII码格式)的字符集,所以在进行此改变之前要三思。
如果想永久性维持该变化,可以在系统.bashrc文件中添加下面的命令行。

7 POSIX基本正则表达式和扩展正则表达式的比较
在读者正觉得正则表达式已经复杂得不能再复杂时,又会发现POSIX规范将正则表达式的实现方法分为了两种:基本正则表达式(BRE)和扩展正则表达式(ERE)。到目前为止,我们所讨论的正则表达式的所有特性,都得到了兼容POSIX的应用程序的支持,并且都是以BRE的方式实现。grep命令就是这样的一个例子。
BRE和ERE到底有什么区别?其实仅仅是元字符的不同!在BRE方式中,只承认^、$、.、[、]、*这些是元字符,所有其他的字符都被识别为文字字符。而ERE中,则添加了(、)、{、}、?、+ |、等元字符(及其相关功能)。
然而(也是有趣的部分),只有在用反斜杠进行转义的情况下,字符(、)、{、}才会在BRE被当作元字符处理,而ERE中,任何元符号前面加上反斜杠反而会使其被当作文字字符来处理。
由于下面要讨论的特性是ERE的一部分,所以需要使用不一样的grep。传统上,这是由egrep程序来执行的,但由于下面要讨论的特性是ERE的一部分,所以需要使用不一样的grep。传统上,这是由egrep程序来执行的,但是GNU版本的grep可以运用-E选项以支持ERE方式。
8 或选项
我们将要讨论的第一个扩展正则表达式的特性是或选项(alternation),它是用于匹配表达式集的工具。括号表达式可以从指定字符集中匹配单一字符,而或选项则用于从字符串集或正则表达式集中寻找匹配项。
以下便利用grep结合echo作为演示实例。首先,我们进行一个简单的字符串匹配。


这是一个非常直白的例子,将echo的输出结果送至grep进行匹配搜索。如果匹配成功,结果便输出打印出来;如无匹配项,则无结果输出。


这里出现了'AAA|BBB'正则表达式,此表达式的含义是“匹配字符串AAA或者匹配字符串BBB”。请注意,由于此处使用的是扩展特性,所以grep增加了-E选项(虽然可以使用egrep命令来代替),并且将正则表达式用引号引起来以防止shell将元字符“|”当作管道操作符来处理。另外,或选项并不局限于两种选择,还可以有更多的选择项。


为了将或选项可与其他正则表达式符号结合使用,我们可以用“()”将或选项的所有元素与其他符号隔开。
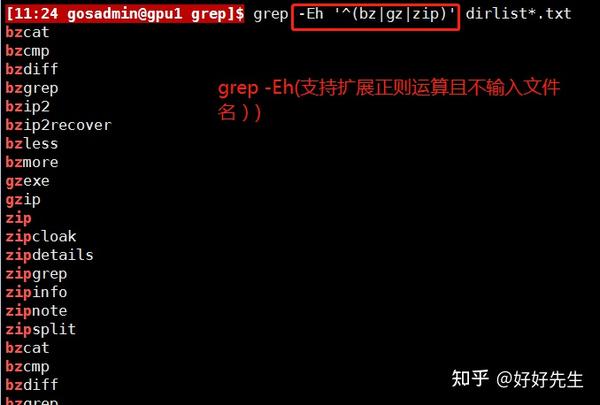

以上表达式的含义是匹配文件名以bz、gz或是zip开头的文件。如果不使用括号“()”,该正则表达式的含义就完全不同,其匹配的便是文件名以bz开头或者是包含gz和zip的文件。
9 限定符
扩展正则表达式(ERE)提供多种方法指定某元素匹配的次数。
- ?——匹配某元素0次或1次
该限定符实际上意味着“前面的元素可选”。比如,如果我们想检查某电话号码的有效性。所谓电话号码有效,指的是电话号码必须是下面两种形式(nnn)nnn-nnnn和nnn nnn-nnnn中的一种,其中n是数值。于是,我们可以构造如下所示的正则表达式。
^\(?[0-9][0-9][0-9]\)? [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$
此表达式中,括号字符的后面增加了“?”符号以表示括号字符只能匹配一次或零次。同样,由于括号字符在ERE中通常是元字符,所以其前面加上了反斜杠告诉shell此括号为文字字符。
- *——匹配某元素多次或零次
与“?”元字符类似,“*”用于表示一个可选择的条目。然而,与“?”不同,该条目可以多次出现,而不仅仅是一次。例如,如果我们想知道一串字符是否是一句话,也就是说,这串字符是否以大写字母开头而以句号结束,并且中间内容是任意数目的大小写字母和空格,那么要匹配这种非常粗糙的句子定义,可以用如下正则表达式。
[[:upper:]][[:upper:][:lower:] ]*\.
- +——匹配某元素一次或多次
“+”元字符与“*”非常类似,只是“+”要求置于其前面的元素至少出现一次。示例如下,该正则表达式用于匹配由单个空格分隔的一个或者多个字母字符组成的行。
- {}——以指定次数匹配某元素
本章介绍了正则表达式的很多用法。当然,如果用它们进行一些额外的应用搜索,你会发现正则表达式有更多的用途。我们可以通过查看man手册页获取更详细的内容。

[me@linuxbox ~]$cd /usr/share/man/man1
[me@linuxbox man1]$zgrep -El 'regex|regular expression' *.gz
zgrep程序比grep在前端多了一个字母z,由此便可以对压缩文件进行搜索。本例中,我们在man文件通常存放的目录下对压缩的第一部分man手册页进行了搜索。该命令行的输出结果是一列包含字符串regex或regular expression的文件。可以看到,正则表达式可用于大量应用程序中。
