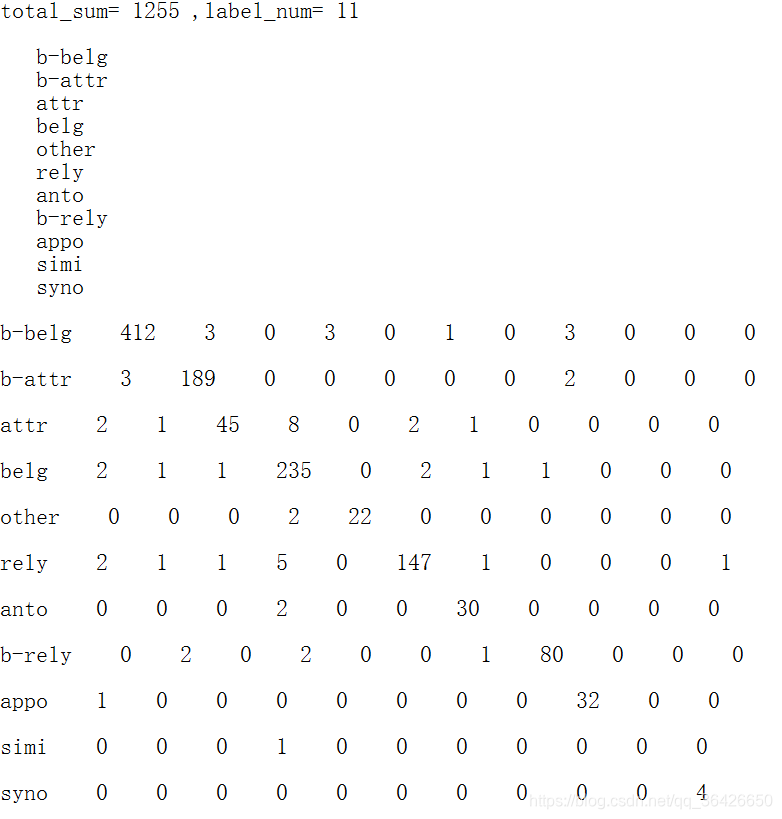
博主将该脚本用在自己的实验中,做关于中文学科知识点关系抽取实验中,输出效果如图:

博客记录着学习的脚步,分享着最新的技术,非常感谢您的阅读,本博客将不断进行更新,希望能够给您在技术上带来帮助。欢迎转载,转载请注明出处
python实现计算精度、召回率和F1值 摘要:在深度学习的分类任务中,对模型的评估或测试时需要计算其在验证集或测试集上的预测精度(prediction/accuracy)、召回率(recall)和F1值。本文首先简要介绍如何计算精度、召回率和F1值,其次给出python编写的模块,可直接将该模块导入在自己的项目中,最后给出这个模块的实际使用效果。一、混淆矩阵及P、R、F1计算原理1、混淆...
获取训练集总的预判正确个数
train_acc += train_correct.data[0] #用来计算正确率
准确率 : train_acc / (len(train_data))
2.误判率
举例:当你是二分类时,你需要计算 原标签为1,但预测为 0 ,以及 原标签
https://blog.csdn.net/kan2281123066/article/details/103237273 代码:利用sklearn 计算 precision、recall、F1 score
https://blog.csdn.net/blythe0107/article/details/75003890代码:sklearn的precision_score, recall_score, f1_score使用
https://blog.csdn.net/Urbanea...
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。在二分类场景里是一个2x2的矩阵。如下图。
TP(True Positive):真正例,实际上和预测中都是正例;
FP(False Positive):假正例,实际上是负例,但是被预测为正例了;
FN(False Negative):假负例,实际上是正例,但是被预测为负例了;
TN(True Negative):真负例,实际上和预测中都是负例。
import numpy as np
# 计算混淆矩阵
def compute_
python - sklearn 计算F1
因为最近写的分类模型需要性能评价 ,常用的分类性能评价有 查准率、召回率、准确率、F1
分类问题的常用的包 sklearn ,下面对F1所用的方法进行介绍
查准率 请看另外一篇文章: sklearn 计算查准率
召回率 请看另外一篇文章: sklearn 计算召回率
对于我们的二分类问题,会有以下情况:
真正例(True Positive,TP):真实类别为正例,预测类别为正例。
假正例(False Positive,FP):真实类别为负例,预测类别
混淆矩阵见:https://blog.csdn.net/qq_36895331/article/details/115271792?spm=1001.2014.3001.5501
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
print(accuracy_score(y_true, y_pred))
print(acc
# 读取实验结果中的精度和损失
def data_plot(path):
# path = r'./model_png\5gcn_128_node_pos_floor_2000.log'
# path = r'./[6, 6]_Standard_taz.csv'
with open(path, mode="r", encoding="utf-8") as f:
目录混淆矩阵准确率精确率召回率
分类是机器学习中比较常见的任务,对于分类任务常见的评价指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 score、ROC曲线(Receiver Operating Characteristic Curve)等。
这篇文章将结合sklearn对准确率、精确率、召回率、F1 score进行讲解,ROC曲线可以参考我的这篇文章...
sklearn.metrics.classification_report
分类报告:sklearn.metrics.classification_report(y_true, y_pred, labels=None, target_names=None,sample_weight=None, digits=2),显示主要的分类指标,返回每个类标签的精确、召回率及F1值
主要参数说明:
labels:分类报告中显示的类标签的索引列表
target_names:显示与labels对应的名称
digits:指定
1 PIL基本操作:主要是为了介绍 PIL 打开、展示和保存图像的基本运用。
2 图像处理:这个主要是为了对原始图像进行再处理,从而使图像符合我们的需求,
通常这里的处理情况会影响到模型训练的精度和准。
3 图像向量化:由于图片是非结构化数据,计算机不能直接识别处理,
因此需要向量化处理,从而转换成结构
在深度学习的分类任务中,对模型的评估或测试时需要计算其在验证集或测试集上的预测精度(prediction/accuracy)、召回率(recall)和F1值。本文首先简要介绍如何计算精度、召回率和F1值,其次给出python编写的模块,可直接将该模块导入在自己的项目中,最后给出这个模块的实际使用效果。
混淆矩阵及P、R、F1计算原理
进行二分类或多分类任务中,对于预测的评估经常需要构建一个混淆矩阵来表示测试集预测类与实际类的对应关系,混淆矩阵横坐标表示实际的类,纵坐标表示预测的类。混