

Tensorflow初学笔记——tf.nn.conv2d()的工作方法
首先,卷积的意思就是从图像的像素点上抽象出特征,然而这个特征抽取的过程并不是传统意义上的人工的抽取,而是通过卷积核进行自动抽取,当然这种抽取的结果对于人类来说也很难讲有什么能够解释的意义。数字图像(比如说一张照片),可以看做是一个矩阵,每一个像素点都是矩阵中的一个元素:特别的,如果照片是黑白的,那么可以看做是一个length×width×1的三维矩阵;如果是彩色的(比如RGB)那么就可以看做一个length×width×3的三维矩阵。卷积核像一小块方形的抹布,在图片上由上到下从左到右均匀抹过,并不时的停下来,当抹布停下来的时候,抹布上的点就会和其覆盖的点进行计算,得到一个值,这个值就将成为卷积计算输出矩阵的对应点的值。
从直观上看,卷积的过程相当于将图片“浓缩了”,当然在浓缩的过程中,厚度是可以变的。
函数tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)有六个参数,其中前面的四个比较主要。
input :输入图片,格式为[batch,长,宽,通道数],长和宽比较好理解,batch就是一批训练数据有多少张照片,通道数实际上是输入图片的三维矩阵的深度,如果是普通灰度照片,通道数就是1,如果是RGB彩色照片,通道数就是3,当然这个通道数完全可以自己设计。
filter :就是卷积核,其格式为[长,宽,输入通道数,输出通道数],其中长和宽指的是本次卷积计算的“抹布”的规格,输入通道数应当和input的通道数一致,输出通道数可以随意指定。
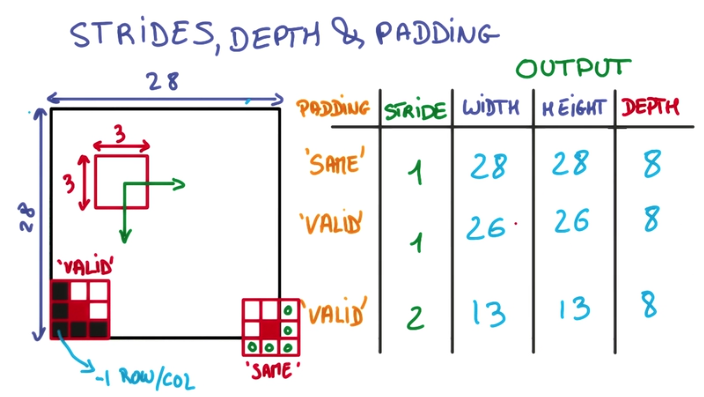
strides :是步长,一般情况下的格式为[1,长上步长,宽上步长,1],所谓步长就是指抹布(卷积核)每次在长和宽上滑动多少会停下来计算一次卷积。这个步长不一定要能够被输入图片的长和宽整除。
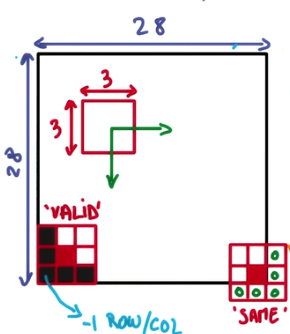
padding :是卷积核(抹布)在边缘处的处理方法,描述起来比较复杂,一张图比较直观,直接上图:
那么具体的卷积方法用一个实例来解释:
(1)输入的数据是[100,80,100,4]的数据,经过的卷积核是[8,8,4,32],步长为[1,4,4,1]策略是valid,那么首先输入的batch=100是不会变的,深度4要变成输出的32,输入图片长度80要在长为8的卷积核下以步长4划过一次,那么抹布的右边缘所处的像素点横坐标应当依次是8,12,16,20……80一共19次计算,所以输出结果的长应当是19,同理,输出结果的宽应当是24,因此输出结果的形状应当是[100,19,24,32]
(2)将第一步的结果输入卷积核[4,4,32,64],步长调整为[1,2,2,1],模式依旧是valid,那么输出结果是[100,8,11,64]
(3)将第二步的结果输入卷积核[3,3,64,128],步长调整为[1,1,1,1],模式调整为same,那么输出结果是[100,8,11,128]
在实际的运算中,计算机实际上首先将输入的input数据规模上进行拓展,由原来的[batch,length,width,channel_in]转化为[batch,out_length,out_width,filter_length×filter_width×channel_in]的格式,其中所谓输出的长宽是通过卷积核的长宽和卷积模式计算好的,一般来讲,卷积过程中卷积核的抽象区域应当有重叠而不应当有缝隙,所以大多数情况下,这样变形的结果是输入数据从规模上被扩大了。而此时,需要进行计算的卷积核矩阵也被变形成[filter_length×filter_width×channel_in,channel_out]的格式,虽然从规模上来说矩阵的大小没变,但是从维度上来说,卷积核被从4维拍扁成了两维,两个变形后的矩阵相乘,得到的结果就是[batch,out_length,out_width,channel_out]了
剩下的事情就是把卷积好的结果输入你设计好的隐藏层、softmax之类的玩意,然后输出预测,计算损失函数,然后迭代优化了。
初学乍练,现学现卖,如有错误,万望指出。