


爬虫小记——曾经热爱的漫画

火影忍者已经完结,但我还念念不忘。
省下一次次早餐钱、忍饥挨饿在所不惜、只敢偷摸着看的热爱
和小伙伴们攒钱"众筹"买来你我分享的快乐时光
那个躲在被窝里被手电筒照亮的热血世界
都已逝去,但不曾失去
既为纪念,亦为实践 Scrapy ,故写下此文
系统环境:win10
IDE:pycharm
python : 3.6
关于Scrapy:
简介:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
Scrapy使用前需要安装,网上有介绍。
Scrapy其实本人不是很精通,但是官方文档的初级教程已足够我写出这份爬虫了。
本文所有关于Scrapy 的指令在初级教程都有提及。
先期探索——目标页
目标网址:
1.例行ctrl+F12 审查元素:

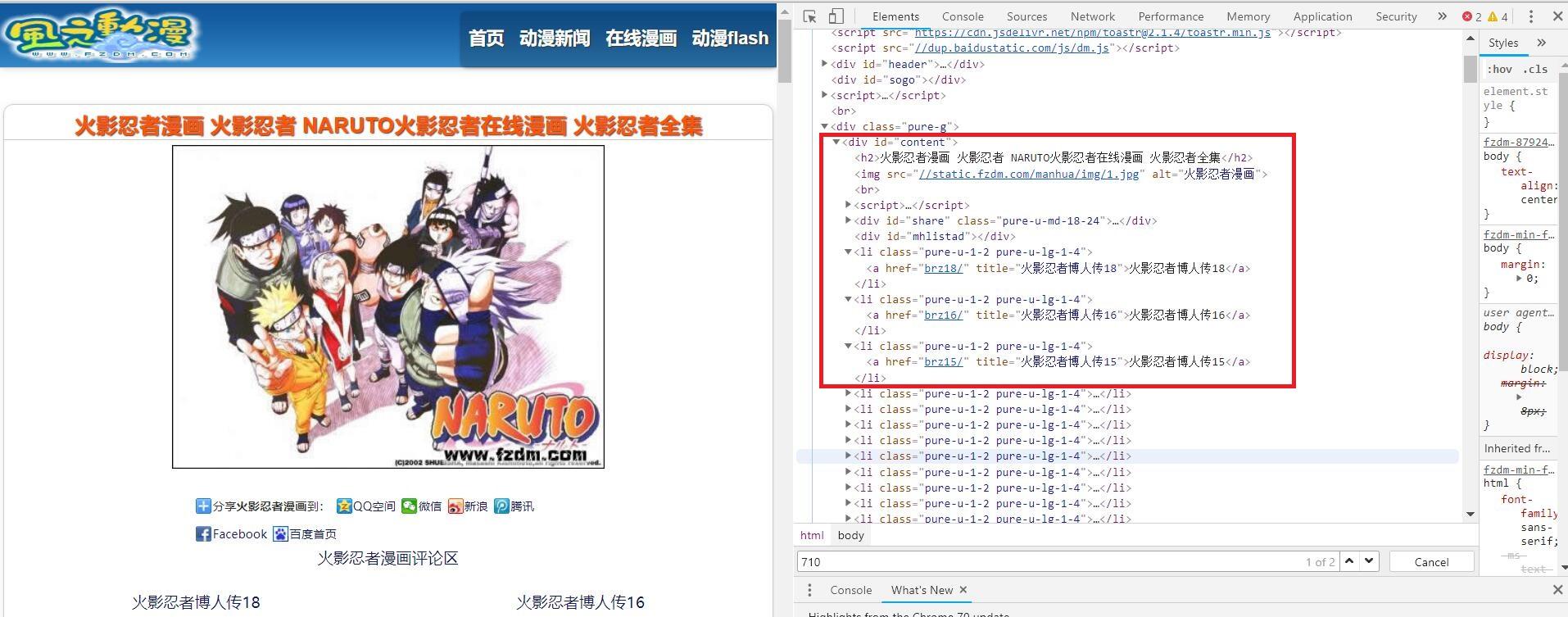
发现所有章节的相关信息都包含在节点
<div id = 'content'>
下,且其下所有
<li>节点的子节点<a>
都依次包含了某一章节的 次级url ,章节名。
2.下面尝试获取章节相关性息
这里需要调试,可以使用scrapy 内置的shell,但是太丑了,故使用win10自带的 Power Shell(以下简称PS)
Scrapy shell "https://www.fzdm.com/manhua/001//"

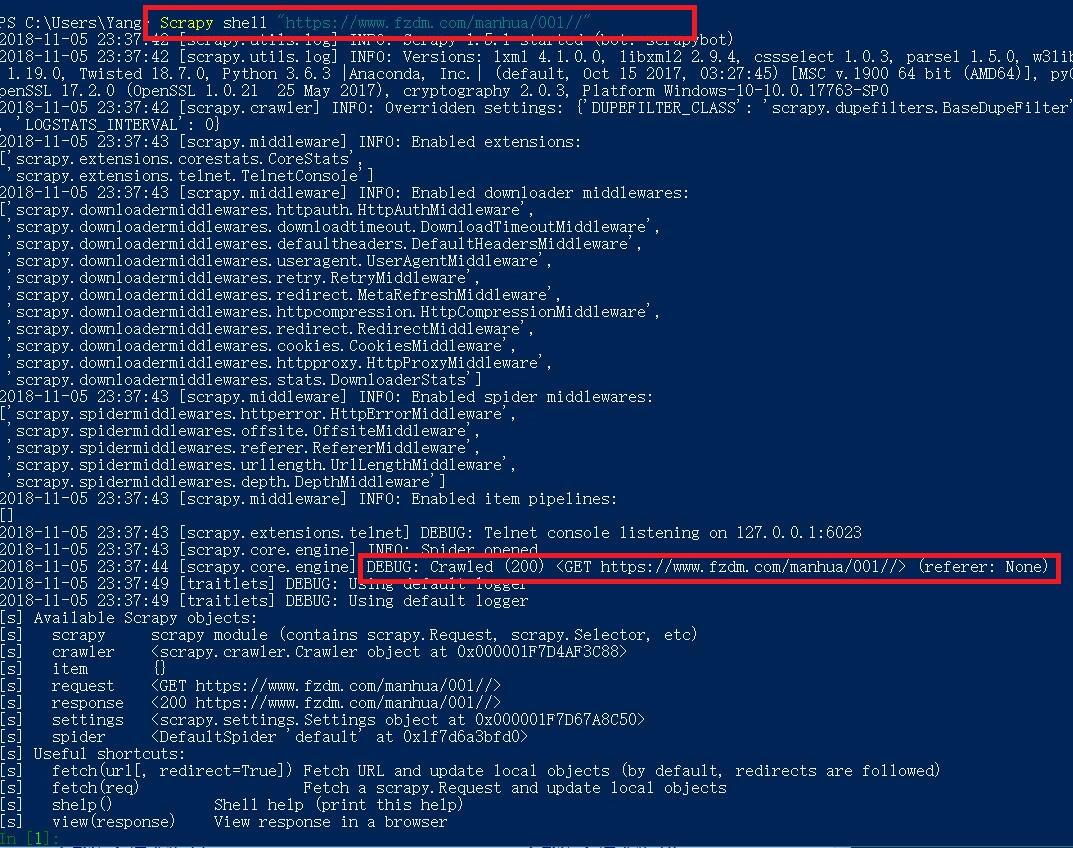
通过这个指令,PS 返回 一个
response
,其中包含了目标网址的全部信息, 其内容就是审查元素中看到的HTTP代码。
也可以通过指令
response.body
来输出HTTP代码, 但这样看的体验极差,不推荐。
回到我们之前提到
<li class = "pure-u-1-2 pure-u-lg-1-4">都包含了某一章节的 次级url ,章节名 ......
故通过 xpath 获取并拼接章节url以及章节名:
可以将xpath看作一种查找工具
关于xpath 下面有更多信息和教程
输入以下指令
response.xpath('//li/a')

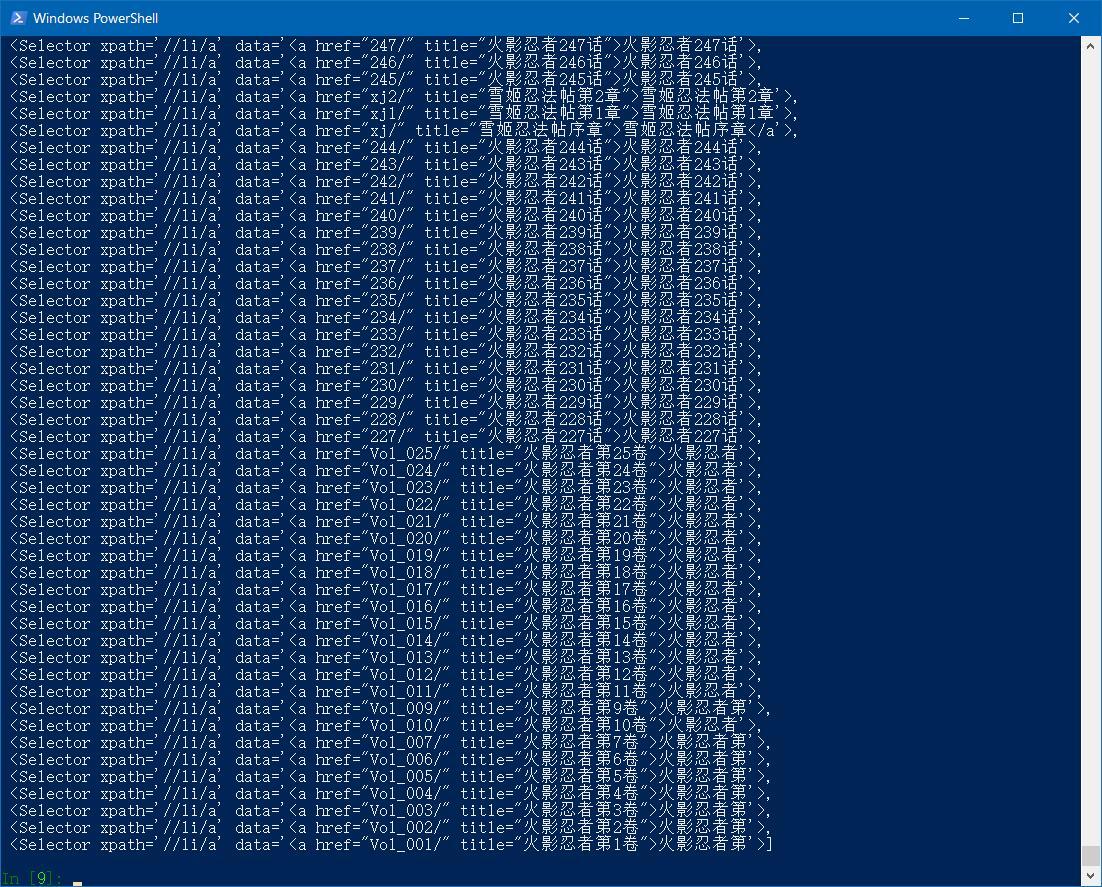
提取里面的节点要用到extract()方法
提取节点:
response.xpath('//li/a').extract()

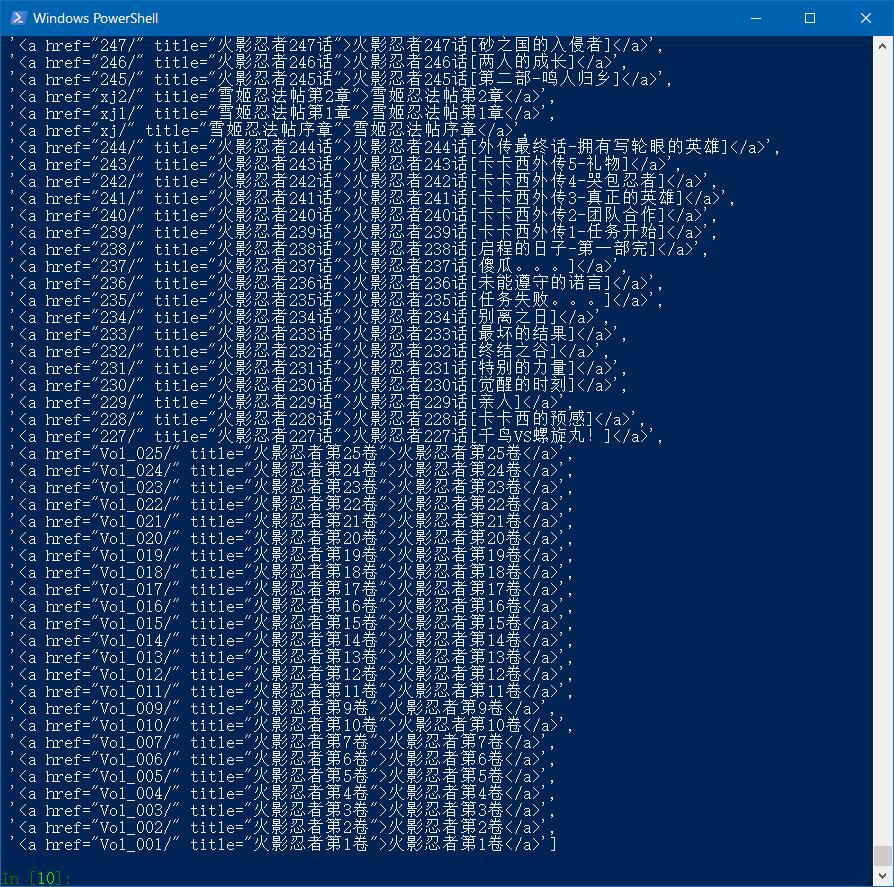
可以通过以下指令分别提取章节次级url和章节名:
1.
章节url
: response.xpath('//li//a/@href').extract(
)

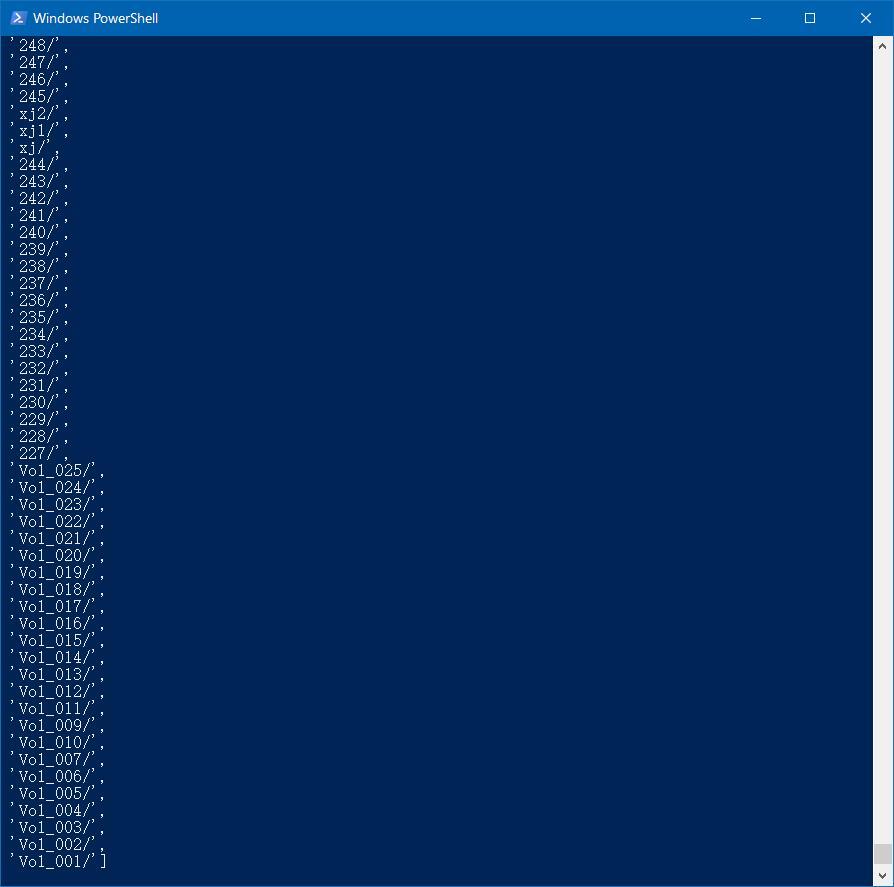
2.
章节名
:response.xpath('//li/a/text()').extract()

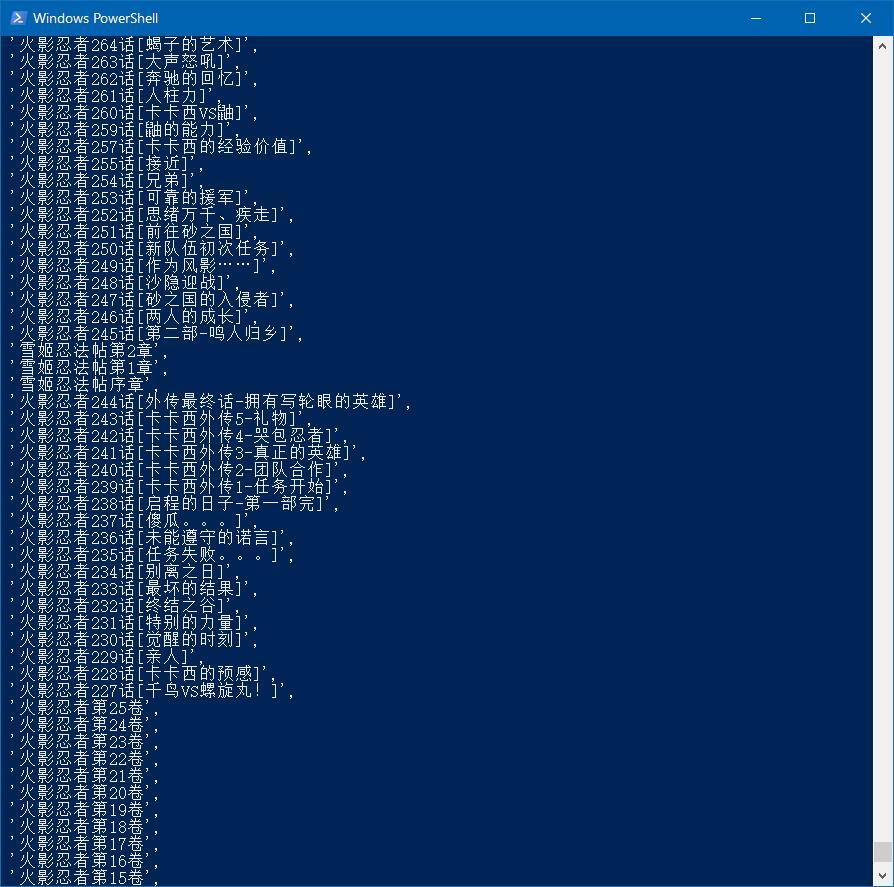
以上 我们成功获得了全部章节的URL和章节名。
二期探索:章节URL网页
单单获得所有章节的URL还不够,但已经做完了一半。
继续探索章节网页
步骤和之前探索目标网址一样
1.审查元素:
这里以章节“博人传18”为例
章节页:

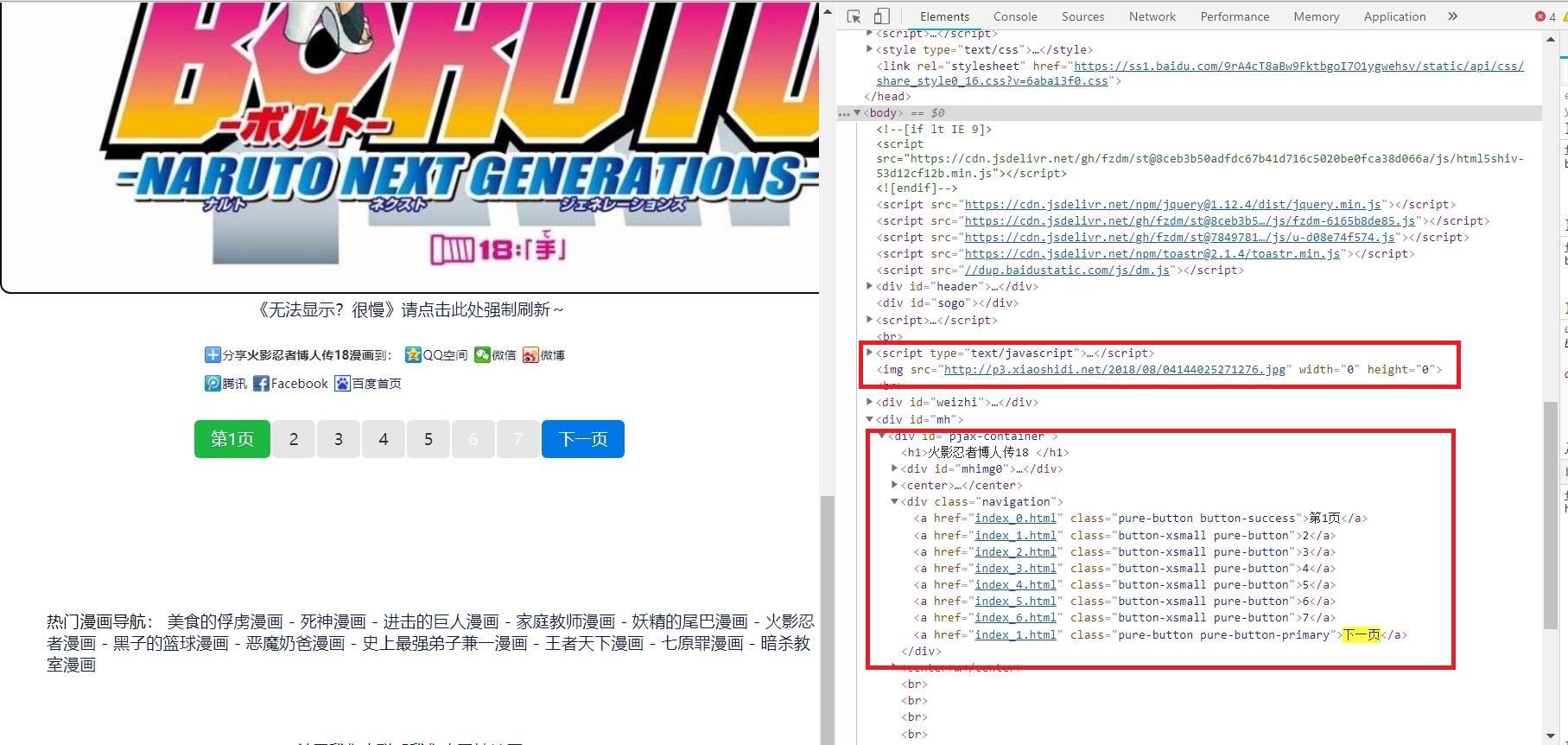
发现我们需要的信息有:
1.漫画页码:位于节点<div class = "navigation"> 下的节点<a>中
2.漫画图片url:位于节点<script>下的节点<img>中
2. 尝试提取我们需要的信息
PS退出之前的目标网址(
指令:exit
)
PS输入
Scrapy shell "https://www.fzdm.com/manhua/001//brz18/"
2.1查找漫画页码:

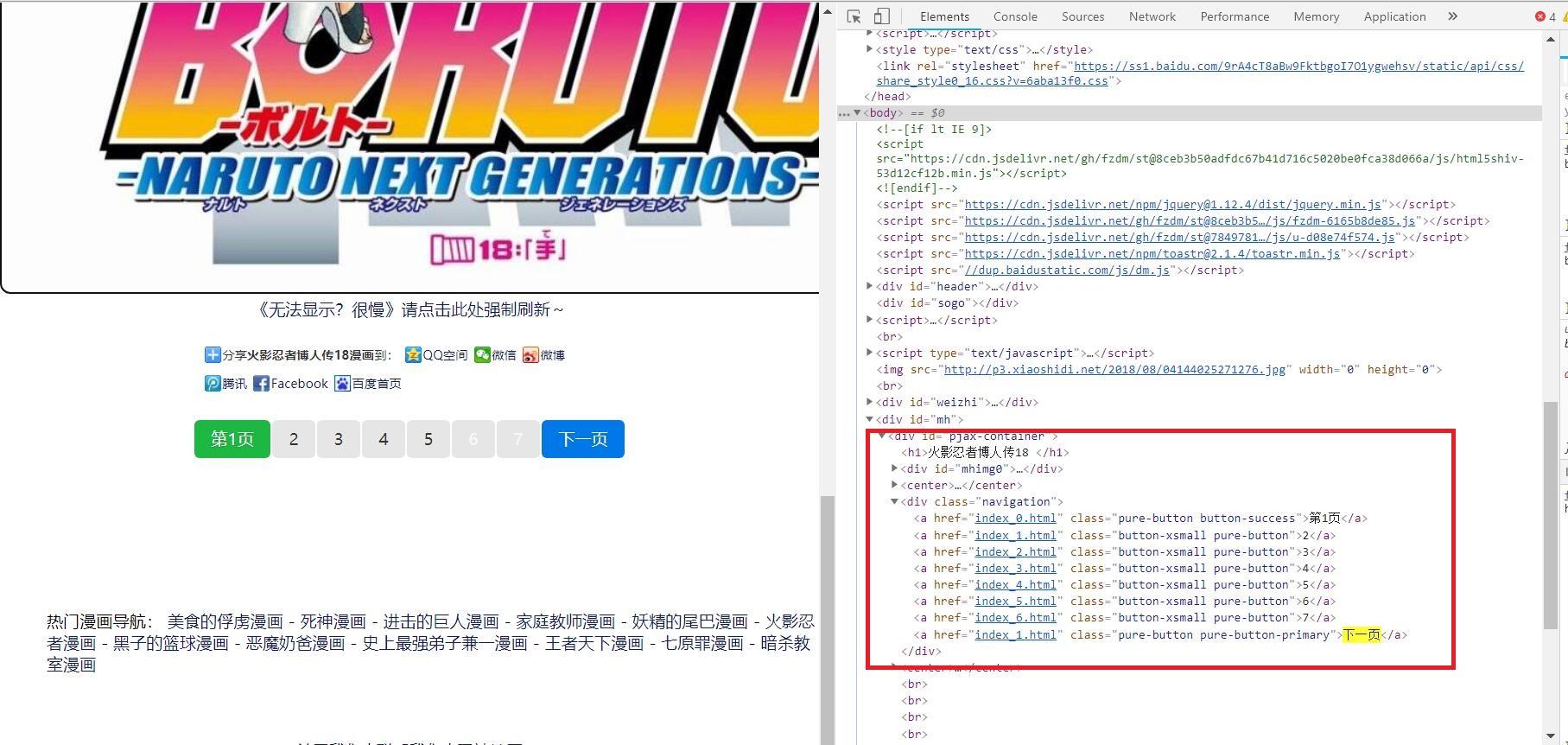
response.xpath('//div/a/text()')
结果:

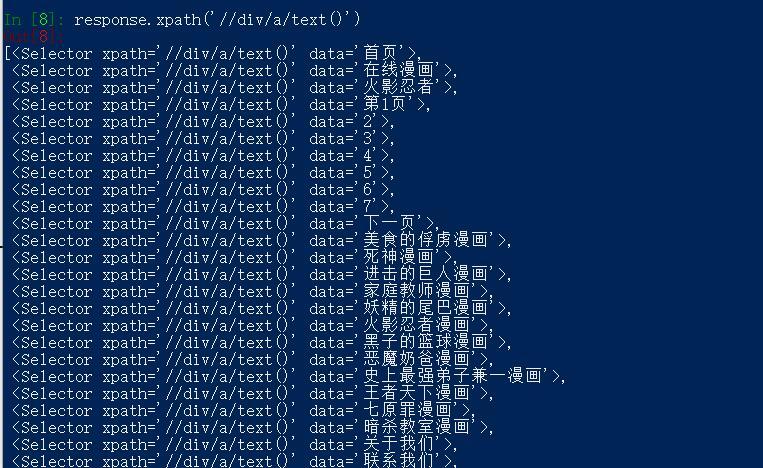
我们需要的是,其中的 "1,2,3,4,5,6,7" 。
发现包含多余信息,但没关系,可以通过正则表达式获得我们需要的页码信息。
response.xpath('//div/a/text()').re('\d')

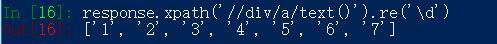
2.2提取漫画图片url:
继续输入
response.xpath('//script/img/@scr').extract()
但是
发现返回为空。
回到漫画页观察审查元素发现,这个链接是使用JS动态加载进去的。直接获取是不行的,网页分为静态页面和动态页面,对于静态页面好说,对于动态页面就复杂一些了。可以使用PhantomJS、发送JS请求、使用Selenium、运行JS脚本等方式获取动态加载的内容。
其实回顾一下发现JS脚本就在节点中
<script type="text/javascript">
,这说明JS脚本并非外部脚本,这样就好处理,可以省下很多时间。:


阅读JS脚本,发现其中已经包含了我们需要的信息,比如说第二行中漫画图片url :
mhurl="2018/08/04144025271276.jpg
以及漫画图片的服务器地址:
http://p3.xiaoshidi.net/
尝试提取下
response.xpath('//script/text()').re('mhurl=+.*\.jpg')


到此全部探索完成,整理我们的思路:
1.我们需要从目标页中提取所有章节的次级url 和章节名,将得到的章节页次级URL与目标页URL拼接, 得到所有章节的URL
2.之前我们在章节页中发现,每章节都包含了多个漫画页的URL,我们需要从每个章节页中获取所有的漫画页URL
3.从漫画页中获取 漫画图片URL
4.保存图片。
图片的存储规则:每一章节为一个独立文件夹,每章节的漫画图片根据页码命名。
1.Scrapy 项目创建
这部分参照scrapy文档中的初级教程而写的
scrapy 新建爬虫
在POWERSHELL中输入:scrapy startproject 爬虫项目名
我的是:
scrapy startproject comic_crawer
-
创建好后,在对应目录里,找到对应的项目目录:

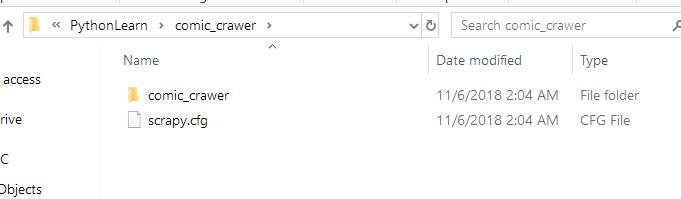
其中文件的意义:
-
scrapy.cfg: 项目的配置文件 -
comic_crawer/: 该项目的python模块。之后将在此加入代码。 -
comic_crawer/items.py: 项目中的item文件. -
comic_crawer/pipelines.py: 项目中的pipelines文件. -
comic_crawer/settings.py: 项目的设置文件. -
comic_crawer/spiders/: 放置spider代码的目录.
2.代码

上面的文件中,需要编写items.py 和 spiders下面的爬虫代码,以及修改settings.py中的一些代码
这部分需要自己理解,已经在代码中加入了注释
items.py 编写
内容如下:
import scrapy
class ComicCrawerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
chapter_name = scrapy.Field() #章节名[]
chapter_url = scrapy.Field() #章节url[]
index_urls = scrapy.Field() #每章页码链接[]
indexes = scrapy.Field() #每章的页码[]
img_url = scrapy.Field() #每页漫画图片url
img_paths = scrapy.Field() #漫画图片存储路径。爬虫呢。爬虫要在comic_crawer/spiders/ 创建自己的python 文件,写入爬虫代码:
comic_spider.py
import re
import scrapy
from scrapy import Selector
from comic_crawer.items import ComicCrawerItem
class ComicSpider(scrapy.Spider):
#爬虫的名字,自定义,启用爬虫时需要用到
name = 'Comic'
def __init__(self):
#设置爬虫活动范围,防止乱爬
self.allowed_domains = ['www.fzdm.com']
#设置初始目标页
self.start_url = ['https://www.fzdm.com/manhua/1/']
#章节URL的前半部分,用于和后面获得的次级URL进行拼接,得到章节页URL
self.target_link = 'https://www.fzdm.com/manhua/1/'
#漫画图片服务器地址
self.img_server = 'http://p3.xiaoshidi.net/'
def start_requests(self):
#启动时爬虫从start_url开始
yield scrapy.Request(url =self.start_url[0], callback= self.parse_1)
def parse_1(self, response):
items = []
chapter_response = Selector(response)
urls = chapter_response.xpath('//li//a/@href').extract()
#urls 全部章节URL
chapter_names = chapter_response.xpath('//li/a/text()').extract()
#chapter_names 全部章节名
#将获得的信息保存到item, item可以在scrapy的各个组件中传递
for index in range(len(urls)):
item = ComicCrawerItem()
item['chapter_name'] = chapter_names[index]
item['chapter_url'] = self.target_link + urls[index]
item['index_urls'] = []
item['img_url'] = []
items.append(item)
for item in items[3: ] :
#items的前三项不是我们需要的。所以从第四项开始
# 解析获得章节URL, 并传递item到parse2
yield scrapy.Request(url= item['chapter_url'], meta= {'item':item}, callback= self.parse_2)
def parse_2(self, response):
####parse_2 主要用于解析章节URL, 获得漫画图片链接和页数信息###
#接收parse_1传递来的item
item = response.meta['item']
img_response = Selector(response)
#获取图片页数列表
img_page_list = response.xpath('//div/a/text()').re('\d')
indexes = range(len(img_page_list))
#页数列表保存到item中
item['indexes'] = img_page_list
for index in indexes :
#将章节页URL与页数拼接组成漫画页URL
index_url = item['chapter_url']+'index_'+str(index)+'.html'
#漫画页URL保存入item中
item['index_urls'].append(index_url)
#抓取漫画页,传递item到parse_3
yield scrapy.Request(url= index_url, meta={'item': item}, callback = self.parse_3)
def parse_3(self, response):
###parse_3用于解析漫画页URL,并获得漫画图片的URL###
#接受Parse_2传递来的item
item = response.meta['item']
index_response = Selector(response)
# 截掉“mhurl=”,获得漫画图片URL
img_url_last = response.xpath('//script/text()').re('mhurl=+.*\.jpg')[0][7:]
#漫画图片服务器地址与漫画图片URL拼接,得到完整URL
ultimate_img_url = self.img_server+img_url_last
#保存到item中
item['img_url'].append(ultimate_img_url)
#将item传给pipelines, 进行漫画图片的下载和保存
yield item
settings.py编写:
BOT_NAME = 'comic_crawer'
SPIDER_MODULES = ['comic_crawer.spiders']
NEWSPIDER_MODULE = 'comic_crawer.spiders'
IMAGES_STORE = 'D:/火影忍者'
# USER_AGENTS = [
# "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.25
COOKIES_ENABLED = False
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
ITEM_PIPELINES = {
'comic_crawer.pipelines.ComicCrawerPipeline': 1,
}pipelines.py编写:
from comic_crawer import settings
from scrapy import Request
import requests
import os
class ComicCrawerPipeline(object):
def process_item(self, item, spider):
if 'img_url' in item:
image_urls = item['img_url']
indexes = item['indexes']
img_paths = []
#文件夹路径及名称
chapter_path = '%s/%s' % (settings.IMAGES_STORE, item['chapter_name'])
#若不存在则创建
if not os.path.exists(chapter_path):
os.makedirs(chapter_path)
for (image_url,index) in zip(image_urls,indexes):
img_name = '第' + index + '页.jpg'
#图片保存路径
img_path = '%s/%s' % (chapter_path, img_name)
img_paths.append(img_path)
with open(img_path,'wb') as f_img:
response = requests.get(url= image_url)
for block in response.iter_content(1024):
if not block:
break