

SQL专题(三十一)presto SQL 中一些特别的点

数据类型
集合数据类型
- array
- map
- json
- row
array --可以是数字,也可以是字符串等等
不建议翻译成数组,阵列可能比较好一点
很好理解,就是一个数组,数组里面的元素的类型必须一致:
An array of the given component type.All ARRAY elements must be the same type
Example:
ARRAY[1,2,3]
select typeof(ARRAY[1,2,3])返回array(integer)
select ARRAY[1,2,3]返回1,2,3
map--映射关系
表示是一个映射类型,跟JSON不一样的是,所有的key的类型必须一致,所有value的类型也必须一致。在字面量里面,Presto是通过让用户指定两个有序ARRAY: 一个key的ARRAY,一个value的ARRAY来表达的:
在内存里面的表示,
MAP
的内容这是被保存成一个一个的key-value对:
A map between the given component types.Key and value arrays must be the same length
MAP(ARRAY['foo','bar'],ARRAY[1,2])
select typeof(MAP(ARRAY['foo', 'bar'], ARRAY[1, 2]))map(varchar(3), integer)
select MAP(ARRAY['foo', 'bar'], ARRAY[1, 2])结果是:{bar=2, foo=1}
json
Variable length json data.
MAP
表示是一个映射类型,跟JSON不一样的是,所有的key的类型必须一致,所有value的类型也必须一致
换句话说,json里面的key的类型,value的类型是不是可以不一致。
row
表示的是一行记录,这行记录的数据可以是各种不同的类型,比如:
select typeof(ROW(1, 2.0))返回row(integer, double)
select ROW(1, 2.0)返回{field0=1, field1=2.0}
select ROW(1, 'wqw')返回{field0=1, field1=wqw}
时间间隔数据类型--interval
interval 可以是:
- year to month
- day to second
注意:year to month 格式 是这样interval 'years-months' year to month (可以单独year也可以单独month)
day to second 格式是 interval '4 01:03:05.44' day to second (可以单独day也可以单独second)
select date('2021-10-21')+INTERVAL '2' DAY
select now()+INTERVAL '2 01:05:04' DAY to second返回2021-11-30 01:13:14.003 UTC
select date('2021-11-21')+INTERVAL '4-1' year to month 返回December 21, 2025, 12:00 AM
try函数
TRY
评估一个表达式,如果出错,则返回Null。类似于编程语言中的try catch
try函数一般结合COALESCE使用,COALESCE可以将异常的空值转为0或者’’
以下情况会被try捕获:
分母为0
错误的cast操作或者函数入参
数字超过了定义长度
个人不推荐使用,应该明确以上异常,做数据预处理
try_cast(value AS type) → type
如果遇见字符串转换不成数字这种,返回null
字符串
拼接||
比较方便,不用concat
split
特别注意split(string,delimiter) 在presto delimiter是 分隔符
但是hive中的这个函数,第二个参数是正则表达式。这也是为什么某些特殊字符需要用\转义字符的原因,加上hive里面转义字符有需要双反斜线\\
容易困惑,提醒一下大家
split_apart
select split_part('192.1.1.2','.',1) as resulthive里面--substring_index
这个函数需要注意参数count,可以是负数。从后向前
substring_index(str,delim,count)
str:要处理的字符串
delim:分隔符
count:计数
例子:str= http://www. wikibt.com
substring_index(str,'.',1)
结果是:www
substring_index(str,'.',2)
结果是:www.wikibt
也就是说,如果count是正数,那么就是从左往右数,第N个分隔符的左边的全部内容
相反,如果是负数,那么就是从右边开始数,第N个分隔符右边的所有内容,如:
substring_index(str,'.',-2)
结果为: http:// wikibt.com
有人会问,如果我要中间的的wikibt怎么办?
很简单的,两个方向:
从右数第二个分隔符的右边全部,再从左数的第一个分隔符的左边:
substring_index(substring_index(str,'.',-2),'.',1);
substr---hive里面也有
substr,substring
select substr('abcde',2);从第二个截,截到结尾
select substr('abcde',1,3);从第一个截,截三个长度
select substr('wfeww',-2);从尾部截,截两个长度
可以用于比如截取身份证后几位操作
字符串和映射--split_ to_ map---split_to_multimap
split_to_map
(
string
,
entryDelimiter
,
keyValueDelimiter
)→ map<varchar, varchar>
Splits
string
by
entryDelimiter
and
keyValueDelimiter
and returns a map.
entryDelimiter
splits
string
into key-value pairs.
keyValueDelimiter
splits each pair into key and value.
函数通过使用entryDelimiter将字符串参数分割,将字符串拆成包含键值对的字符串,然后使用keyValueDelimiter将这些字符串拆成键和值,其结果是一个映射。
SELECT split_to_map('userid=1234&reftype=email&device=mobile', '&', '=');当同一个键出现多次时,split_to_map函数会返回错误。
类似的函数split_to_multimap可以在一个键重复出现时使用。假定前面的例子中有一个重复的device项:
SELECT
split_to_multimap(
'userid=1234&reftype=email&device=mobile&device=desktop',
'=');返回{device=[mobile, desktop], userid=[1234], reftype=[email]}
解嵌套---unnest操作
下面链接是官方的解释(一行转多行,解聚的操作)
UNNEST
can be used to expand an
ARRAY
or
MAP
into a relation.
Arrays are expanded into a single column, and maps are expanded into two columns (key, value).
UNNEST
can also be used with multiple arguments, in which case they are expanded into multiple columns, with as many rows as the highest cardinality argument (the other columns are padded with nulls).
UNNEST
can optionally have a
WITH
ORDINALITY
clause, in which case an additional ordinality column is added to the end.
UNNEST
is normally used with a
JOIN
and can reference columns from relations on the left side of the join.
以下数据来自presto 实战:
通过UNNEST操作,可以将8.9.1节中讨论的复杂集合数据类型展开成关系。对于大数据和嵌套结构数据类型,这是一个非常强大的功能。通过将数据展开到关系中,你可以更容易地在查询中访问嵌套在结构中的值。
解聚单行---array
数据集:
SELECT * FROM permissions;
user | roles
--------+----------------------------------------------
matt | [[WebService_ReadWrite, Storage_ReadWrite],
[Billing_Read]]
martin | [[WebService_ReadWrite, Storage_ReadWrite],
[Billing_ReadWrite, Audit_Read]]我们可以通过使用UNNEST来展开每个角色,然后与用户关联:
SELECT user, t.roles
FROM permissions,
UNNEST(permissions.roles) AS t(roles);
user | roles
--------+-------------------------------------------
martin | [WebService_ReadWrite, Storage_ReadWrite]
martin | [Billing_ReadWrite, Audit_Read]
matt | [WebService_ReadWrite, Storage_ReadWrite]
matt | [Billing_Read]
(4 rows)进一步展开结构
SELECT user, permission
FROM permissions,
UNNEST(permissions.roles) AS t1(roles),
UNNEST(t1.roles) AS t2(permission);
user | permission
--------+----------------------
martin | WebService_ReadWrite
martin | Storage_ReadWrite
martin | Billing_ReadWrite
martin | Audit_Read
matt | WebService_ReadWrite
matt | Storage_ReadWrite
matt | Billing_Read最终的使用
SELECT user, permission
FROM permissions,
UNNEST(permissions.roles) AS t1(roles),
UNNEST(t1.roles) AS t2(permission)
WHERE permission = 'Audit_Read';
user | permission
--------+-----------
martin | Audit_Read
(1 row)解聚多列--array
这列的多列实际上是一个嵌套nest array
SELECT typeof(ARRAY [ARRAY['-999999', '-6', '升级检测总计'],
ARRAY['-999999', '-5', '升级失败'],
ARRAY['-999999', '-4', '不需要升级'],
ARRAY['-999999', '-3', '成功总计'],
ARRAY['-999999', '-2', '安装成功'],
ARRAY['-999999', '-1', '插件信息同步成功'],
ARRAY['3', '1', '不需要升级'],
ARRAY['3', '2', '需要升级'],
ARRAY['3', '3', '升级策略检测错误'],
ARRAY['4', '4', '下载插件plugin_info.json阶段开始下载'],
ARRAY['4', '5', '下载插件plugin_info.json阶段下载成功'],
ARRAY['5', '6', '开始解析'],
ARRAY['5', '7', '解析成功,同步插件信息成功'],
ARRAY['5', '8', '解析成功'],
ARRAY['6', '9', '配置下载策略'],
ARRAY['6', '10', '配置成功,同步插件信息成功'],
ARRAY['6', '11', '配置成功'],
ARRAY['7', '12', '空间检查'],
ARRAY['7', '13', '空间检查次成功'],
ARRAY['8', '14', '下载'],
ARRAY['8', '15', '下载成功'],
ARRAY['9', '16', '包检查'],
ARRAY['9', '17', '包检查成功'],
ARRAY['10', '18', '安装'],
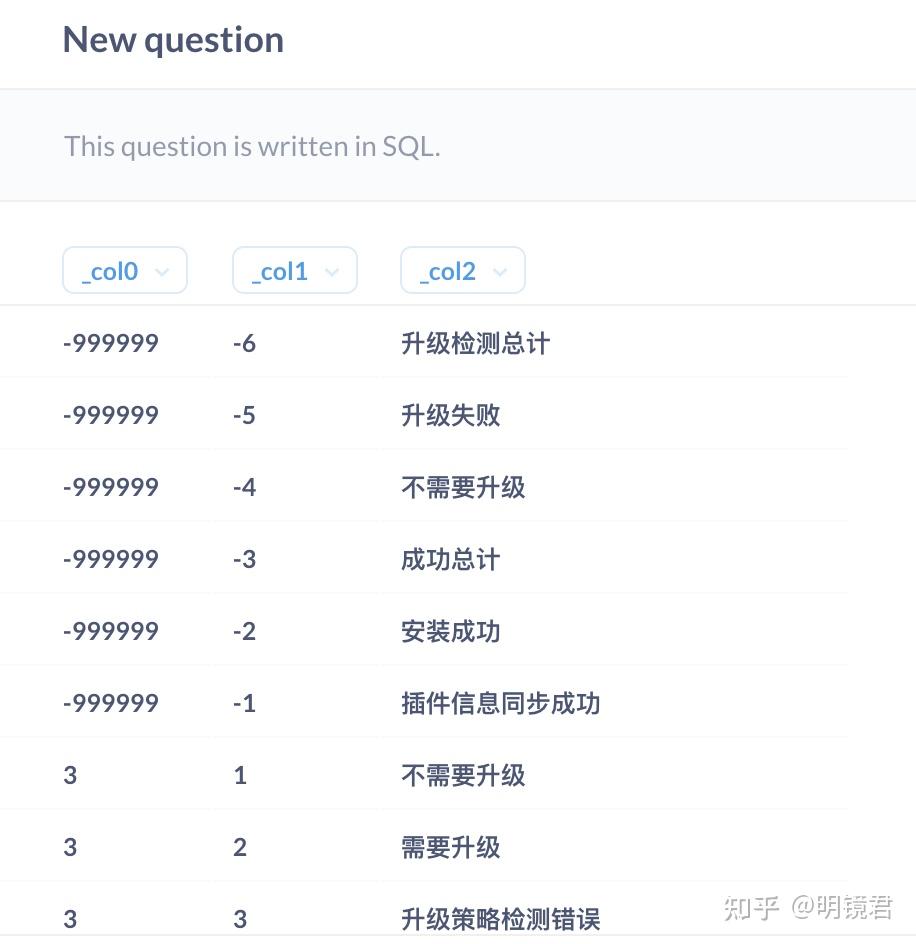
ARRAY['10', '19', '安装成功'] ])返回结果是:array(array(varchar(26)))
上面这个在SQL里面虽然说是嵌套数组,但是还是一行数据。这一行数据如何才能够拆成,类似python中的那种X*Y的数组结构,或者dataframe结构给我们使用呢。
当然就是unnest(解嵌套),然后在cross join即可
select tags,tag[1],tag[2],tag[3]
(SELECT ARRAY [ARRAY['-999999', '-6', '升级检测总计'],
ARRAY['-999999', '-5', '升级失败'],
ARRAY['-999999', '-4', '不需要升级'],
ARRAY['-999999', '-3', '成功总计'],
ARRAY['-999999', '-2', '安装成功'],
ARRAY['-999999', '-1', '插件信息同步成功'],
ARRAY['3', '1', '不需要升级'],
ARRAY['3', '2', '需要升级'],
ARRAY['3', '3', '升级策略检测错误'],
ARRAY['4', '4', '下载插件plugin_info.json阶段开始下载'],
ARRAY['4', '5', '下载插件plugin_info.json阶段下载成功'],
ARRAY['5', '6', '开始解析'],
ARRAY['5', '7', '解析成功,同步插件信息成功'],
ARRAY['5', '8', '解析成功'],
ARRAY['6', '9', '配置下载策略'],
ARRAY['6', '10', '配置成功,同步插件信息成功'],
ARRAY['6', '11', '配置成功'],
ARRAY['7', '12', '空间检查'],
ARRAY['7', '13', '空间检查次成功'],
ARRAY['8', '14', '下载'],
ARRAY['8', '15', '下载成功'],
ARRAY['9', '16', '包检查'],
ARRAY['9', '17', '包检查成功'],
ARRAY['10', '18', '安装'],
ARRAY['10', '19', '安装成功'] ] tags )a
--这里要特别注意 如果是在metabase中使用因为[ [,] ]两个连续的中括号会被认成变量filter 会报错
--因此这两个符号之间必须加空格
cross join unnest(tags) as b(tag)返回的结果就是这样:

关于metabase报错的问题,因为[[]] 的原因呢,详细连接如下:
Hello everyone.
I've ran into the same issue and it seems that the problem is caused by having either "[[" or "]]" in the commented part of a query.
Adding "]]" in the comments of any queries I have makes it fail with the error:
Output of parse-tokens* does not match schema: �[0;33m [(named [nil nil (not (matches-some-precondition? a-clojure.lang.ChunkedCons))] "parsed tokens") (not (present? "remaining tokens"))]
Adding "[[" in the comments of any queries I have makes it fail with the error:
Invalid query: found [[ or {{ with no matching ]] or }}
However, everything works fine when I add a space between the 2 characters.
简单点说:以下代码会报错,变的方法是在[[ 或者]] 添加一个 空格就好了
select 1+2 --[[]]
解聚多列--map
---实际上是把解决之前的一行和解聚后的多行就行了一个交叉连接
配合with 子句 建立维度表(不用手动维护表)
SELECT typeof(MAP(ARRAY ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','29','30','31','32','33','50','51','99','100','-1','','ALL'],
ARRAY ['Factory Mode','Homepage App Icon','Remote Button','MyApps App Icon','Remote Button(Power On)','URL EPOS','4kNow','AppsNow','SearchNow','Store Mode','Mobile/PC App','Notification-Dialog','FVP','Backwards EPG','Forwards EPG','Launcher Discover for U3','RemoteNow','Virtual Input','Notification-Toast','Start App by Voice','VIDAA Sports','Voice Search','VIDAA Art','VIDAA Free','Launcher Collection','Media Login','From Setting','Notification-4k content','FTE','Search from Live TV ','WebApp','Start App by Voice(Google Assistant)','VIDAA Account','OTT Channel','Launcher Category','Self Diagnosis','Mobile/PC App','Others','Unknown','Unknown','ALL']))上述代码是这种数据类型:map(varchar(3), varchar(36))
结果是:
{22=VIDAA Art, =Unknown, 23=VIDAA Free, ALL=ALL,
24=Launcher Collection, 25=Media Login, 26=From Setting,
27=Notification-4k content, 28=FTE, 29=Search from Live TV ,
50=Launcher Category, 51=Self Diagnosis, 30=WebApp,
31=Start App by Voice(Google Assistant), 10=Mobile/PC App, 32=VIDAA Account,
11=Notification-Dialog, 33=OTT Channel, 99=Mobile/PC App, 12=FVP, 13=Backwards EPG,
14=Forwards EPG, 15=Launcher Discover for U3, -1=Unknown, 16=RemoteNow,
17=Virtual Input, 18=Notification-Toast, 19=Start App by Voice,
0=Factory Mode, 1=Homepage App Icon, 100=Others, 2=Remote Button, 3=MyApps App Icon,
4=Remote Button(Power On), 5=URL EPOS, 6=4kNow, 7=AppsNow, 8=SearchNow, 9=Store Mode,
20=VIDAA Sports, 21=Voice Search}接下来一步,把上述结果从一行集合(一一对应)数据类型,拆成了2列数据。
select id,name