本文主要是在pandas中如何对字符串进行切分。我们考虑一下下面的应用场景。

这个是我们的数据集(data),可以看到,数据集中某一列(name)是某个行业的分类。各个行业之间用符号 ‘|’分割。
我们要把用每个‘|’进行分割的内容抽取出来。
pandas有个一步到到位的方法,非常方便。
import pandas as pd
data['name'].str.split('|',expand=True)
关键是参数expand,这个参数取True时,会把切割出来的内容当做一列。 如果不需要pandas为你分好列,expand=False就可以了。
通过上面一步,我们可以得到下面的结果。
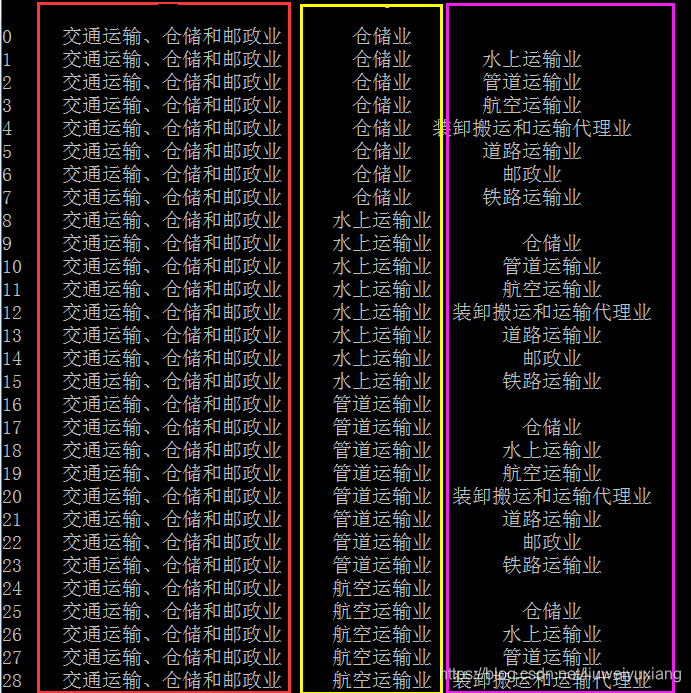
这个时候已经切成3列了。
然后,我们如果只想要第一列的话,只需要做:
data['name'].str.split('|',expand=True)[0]
原文链接:
- pandas 如何分割字符
- 5、pandas的字符串的分割之str.split()
本文主要是在pandas中如何对字符串进行切分。我们考虑一下下面的应用场景。这个是我们的数据集(data),可以看到,数据集中某一列(name)是某个行业的分类。各个行业之间用符号 ‘|’分割。我们要把用每个‘|’进行分割的内容抽取出来。pandas有个一步到到位的方法,非常方便。import pandas as pddata['name'].str.split('|',expand=...
# 将每个数据按照_分割返回结果默认是一个由列表组成的Series
s = pd.Series(['a_b_c', 'd_e_f', np.nan, 'g_h_i'])
s.str.split('_')
卸载 pandas
pip uninstall pandas
pip install pandas==0.25.3 -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
df.explode("")
column : str or tuple
return dataframe
我们来看一下女生给我的文件是什么样子
print(type(df['exp_job'][0]))
df['exp_job']=df['exp_job'].m
这个是我们的数据集(data),可以看到,数据集中某一列(name)是某个行业的分类。各个行业之间用符号 ‘|’分割。
我们要把用每个‘|’进行分割的内容抽取出来。
pandas有个一步到到位的方法,非常方便。
import pandas as pddata['name'].str.split(
文章目录分列方法一览split()有分裂键extract()无分列键
split()有分裂键
str.split()有三个参数:第一个参数就是引号里的内容:就是分列的依据,可以是空格,符号,字符串等等。
第二个参数就是前面用到的expand=True,这个参数直接将分列后的结果转换成DataFrame。
第三个参数的n=数字就是限制分列的次数。 默认从右边进行分列
如果从左边分列的话可以用 rsplit() ,用法与split()相同
根据"-"进行分列
df["列名"].str.split(
为了介绍python语言中pandas库在数据分析中的重要作用,本人打算以NBA球星勒布朗詹姆斯在2020-2021赛季常规赛个人数据为例对pandas相关函数进行详细说明。利用爬虫技术,在知名篮球网站虎扑爬取了勒布朗詹姆斯的数据,稍后会将数据上传至csdn,以供大家下载。
这篇文章,详细介绍了pandas字符串分割函数---str.split()的用法。
DataFrame.str.split(pa,n,expand)
pat:字符串分隔符,默认为空格。
n:用于指定...
工作中经常遇到 DataFrame结构 一列 数据 存了多个字段,或者 想要去除 开头结尾 与业务无关的字符,形如:
以此为例 我们 提取出 Product ID后边的四位 数字 单独成一列,还是有很多细节 所以本文介绍一下。
1将表格df2内数据转换成字符串格式
df3=df2.astype(str)
此时已经转换新的表 已经赋值给df3
整体结构仍是DataFrame,每个字段内的数据都已经通过 astype(str)转换成了 字符串。
2提取产品列用str.sp
data.insert(1,'city',data['address']) #先复制原来的列
data["address"] = data["address"].map(lambda x:x.split()[0]) #分别处理新旧两列
data["city"] = data["city"].map(lambda x:x.split()[1])
import pandas as pd
employees = pd.read_excel("../018/Employees.xlsx",index_col="ID")
employees .head()
对 Full Name 进行切割分列:
# df = employees["Full Name"].str.split...
今天在工作中遇到要将
pandas数据框的一行拆成多行,和一列拆为多列的需求,一台服务器中可以有多个网卡,每个网卡都有状态,通过网卡的上下行流量。下面以一组“数据”为例,来说一下
pandas如何将一行拆分为多行,一列拆分为多列。
需求如下图
1.先将(0,c)拆成一个数据框
2.再将新数据框拆成4列(list1,list2,list3,list4)
3. 将原始数据框的c列删除,合并两个数据框
pandas中str.contains是一个字符串方法,用于检查一个字符串是否包含另一个字符串。它的语法是:
DataFrame['列名'].str.contains('要查找的字符串', na=False)
其中,DataFrame是一个数据框,['列名']是要查找的列名,'要查找的字符串'是要查找的字符串,na=False表示不包括缺失值。如果要查找多个字符串,可以使用正则表达式。

