

1.2 Flink SourceFunction详细说明


本文主要详细介绍Flink中Data Source相关的详细概念,以及Data Source的创建和使用。
Source是Flink应用程序的开始,Flink应用程序从Source获取数据输入。
Flink预定义了一些常用的DataSource,以下是官网内容:
基于文件:
readTextFile(path) - 读取文本文件,例如遵守 TextInputFormat 规范的文件,逐行读取并将它们作为字符串返回。
readFile(fileInputFormat, path) - 按照指定的文件输入格式读取(一次)文件。
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是前两个方法内部调用的方法。
它基于给定的 fileInputFormat 读取路径 path 上的文件。根据提供的 watchType 的不同,
source 可能定期(每 interval 毫秒)监控路径上的新数据(watchType 为 FileProcessingMode.PROCESS_CONTINUOUSLY),
或者处理一次当前路径中的数据然后退出(watchType 为 FileProcessingMode.PROCESS_ONCE)。
使用 pathFilter,用户可以进一步排除正在处理的文件。
在底层,Flink 将文件读取过程拆分为两个子任务,即 目录监控 和 数据读取。每个子任务都由一个单独的实体实现。
监控由单个非并行(并行度 = 1)任务实现,而读取由多个并行运行的任务执行。后者的并行度和作业的并行度相等。
单个监控任务的作用是扫描目录(定期或仅扫描一次,取决于 watchType),找到要处理的文件,将它们划分为分片,
并将这些分片分配给下游 reader。Reader 是将实际获取数据的角色。每个分片只能被一个 reader 读取,
而一个 reader 可以一个一个地读取多个分片。
重要提示:
如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,当一个文件被修改时,
它的内容会被完全重新处理。这可能会打破 “精确一次” 的语义,因为在文件末尾追加数据将导致重新处理文件的所有内容。
如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,source 扫描一次路径然后退出,无需等待 reader 读完文件内容。
当然,reader 会继续读取数据,直到所有文件内容都读完。关闭 source 会导致在那之后不再有检查点。
这可能会导致节点故障后恢复速度变慢,因为作业将从最后一个检查点恢复读取。
基于套接字:
socketTextStream - 从套接字读取。元素可以由分隔符分隔。
基于集合:
fromCollection(Collection) - 从 Java Java.util.Collection 创建数据流。集合中的所有元素必须属于同一类型。
fromCollection(Iterator, Class) - 从迭代器创建数据流。class 参数指定迭代器返回元素的数据类型。
fromElements(T ...) - 从给定的对象序列中创建数据流。所有的对象必须属于同一类型。
fromParallelCollection(SplittableIterator, Class) - 从迭代器并行创建数据流。class 参数指定迭代器返回元素的数据类型。
generateSequence(from, to) - 基于给定间隔内的数字序列并行生成数据流。
addSource - 关联一个新的 source function。
例如,你可以使用 addSource(new FlinkKafkaConsumer<>(...)) 来从 Apache Kafka 获取数据。以上是官网给出的flink预置的DataSource,像基于文件、基于集合以及基于套接字的DataSource大部分情况都用于本地开发测试。在实际生产环境大部分的数据源都是像Kakfa这样的消息队列,需要使用addSource。所以我们也主要研究一下自定义DataSource的内容。
在程序中使用方式:
//首先创建Flink env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//创建DataSource,这里的SourceFunction是一个接口,我们可以实现这个接口来创建自定义的Source,
//另外,Flink还提供了对应的并行接口ParallelSourceFunction用于创建一个并行的Source,
//以及对应的抽象类RichSourceFunction和RichParallelSourceFunction,Rich Function提供了访问上下文信息的能力。
env.addSource(sourceFunction);首先,先看一下SourceFunction的类图关系:
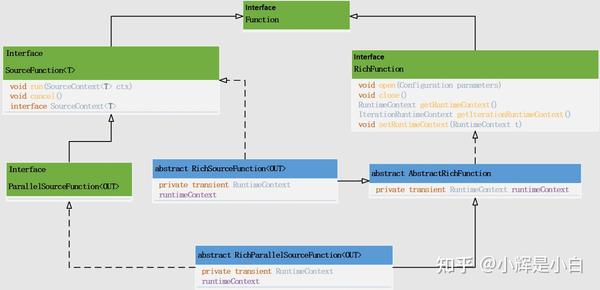
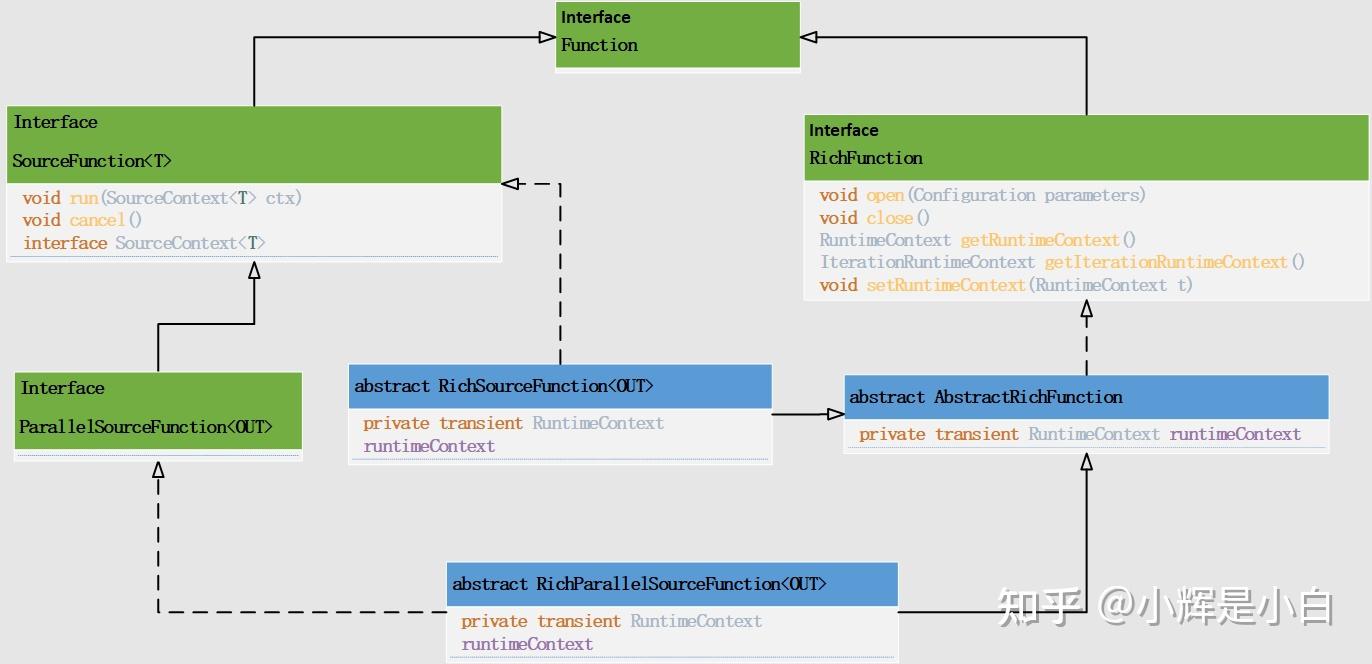
从类图中可以看出,如果我们需要自定义Source的话,则需要实现SourceFunction接口,或者继承该接口对应的抽象类。例如FlinkKafkaConsumer(1.13版本)。我们先自己实现一个简单的SourceFunction,如下图,是一个非常简单的SourceFunction实现,只实现了SourceFunction接口的run方法和cancel()方法。
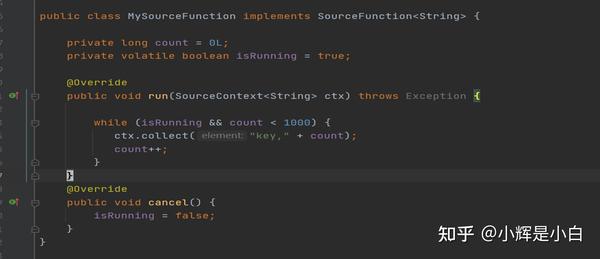
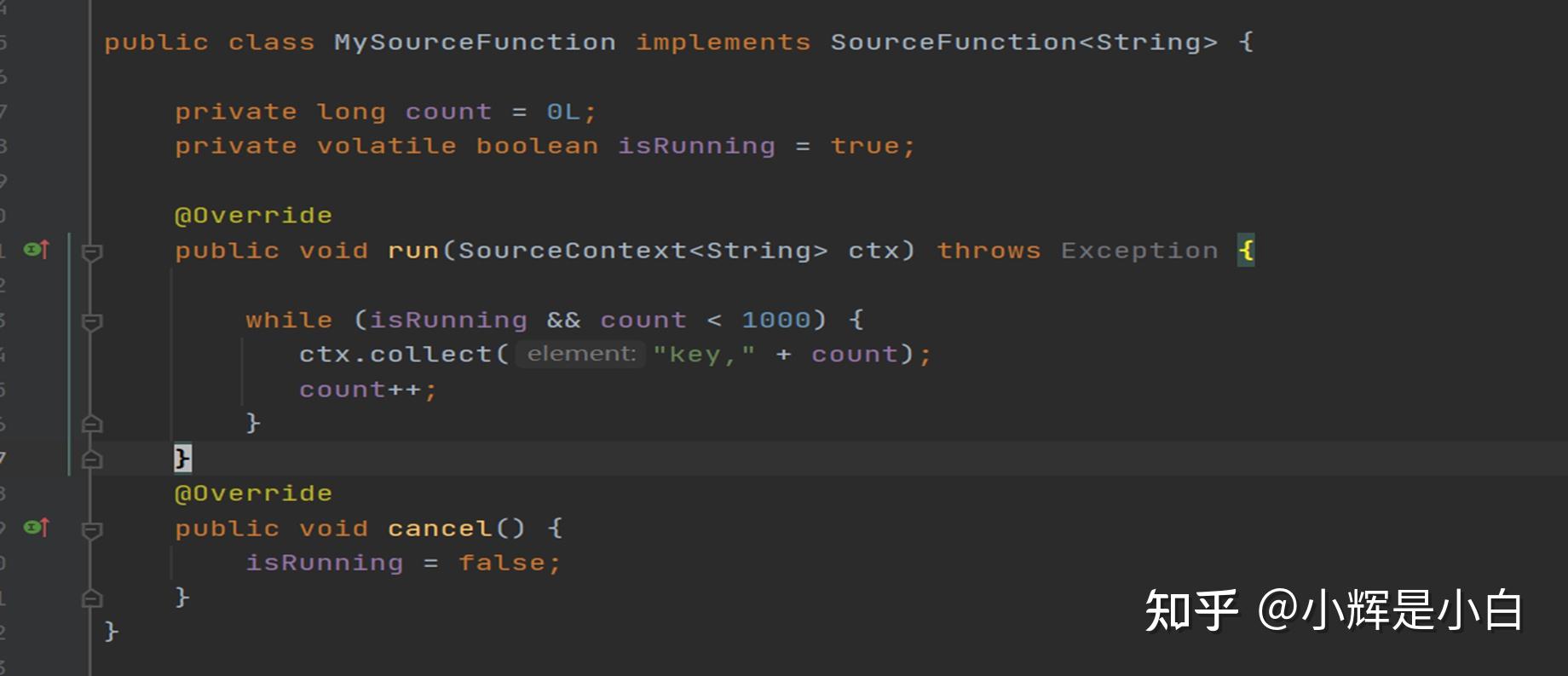
然而,实际应用中SourceFunction的实现要复杂的多,下面我们主要分析一下1.15版本之前的FlinkKafkaConsumer(FlinkKafkaConsumer已被弃用并将在 Flink 1.15 中移除),使用KafkaSource 替代。
先看一下FlinkKafkaConsumer的类图关系。
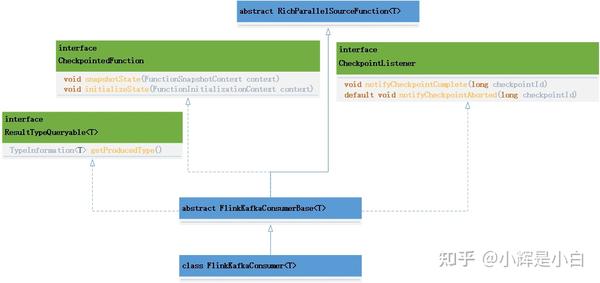
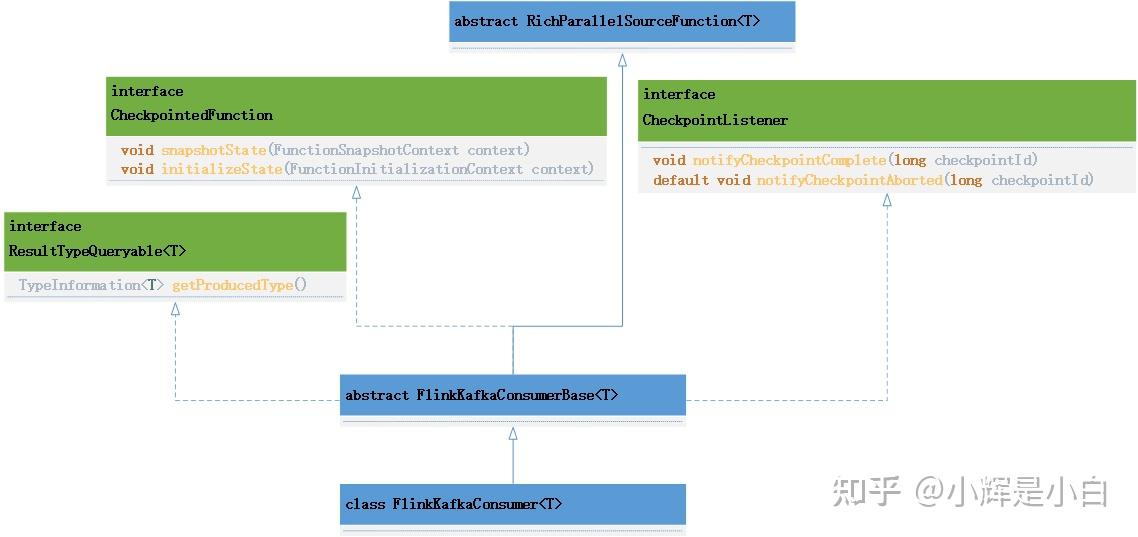
通过类图关系我们可以看出,FlinkKafkaConsumer除了继承RichParallelSourceFunction抽象类,还实现了三个接口, CheckpointedFunction、CheckpointListener、ResultTypeQueryable。
其中:
CheckpointedFunction 是有状态转换函数的核心接口,提供了两个方法,snapshotState方法每次触发checkpoint时执行。initializeState方法在任务初始化时执行。
CheckpointListener ,此接口通常只用于与“外部世界”的事务交互,如在检查点上提交外部副作用。例如,在检查点完成后提交外部事务。该接口也提供两个方法,notifyCheckpointComplete方法通知Listener检查点已完成并已提交。notifyCheckpointAborted方法会在checkpoint失败时被调用。
SourceFunction的run方法是在FlinkKafkaConsumerBase这个抽象类中实现的,FlinkKafkaConsumer主要定义了不同的构造函数,用于创建Consumer,实现了用于从kafka抓取数据的createFetcher方法,以及分区发现等。FlinkKafkaConsumerBase在run方法中创建一个kafkaFetcher对象,并调用kafkaFetcher.runFetchLoop()
run方法的主要源码如下:
@Override
public void run(SourceContext<T> sourceContext) throws Exception {
if (subscribedPartitionsToStartOffsets == null) {
throw new Exception("The partitions were not set for the consumer");
// 初始化提交metrics和默认偏移回调方法
this.successfulCommits =
this.getRuntimeContext()
.getMetricGroup()
.counter(COMMITS_SUCCEEDED_METRICS_COUNTER);
this.failedCommits =
this.getRuntimeContext().getMetricGroup().counter(COMMITS_FAILED_METRICS_COUNTER);
final int subtaskIndex = this.getRuntimeContext().getIndexOfThisSubtask();
this.offsetCommitCallback =
new KafkaCommitCallback() {
@Override
public void onSuccess() {
successfulCommits.inc();
@Override
public void onException(Throwable cause) {
LOG.warn(
String.format(
"Consumer subtask %d failed async Kafka commit.",
subtaskIndex),
cause);
failedCommits.inc();
//如果没有初始化起始分区,则将子任务置位空闲
//一旦这个子任务发现分区并开始收集数据,这些任务的状态将自动触发为活动状态
if (subscribedPartitionsToStartOffsets.isEmpty()) {
sourceContext.markAsTemporarilyIdle();
LOG.info(
"Consumer subtask {} creating fetcher with offsets {}.",
getRuntimeContext().getIndexOfThisSubtask(),
subscribedPartitionsToStartOffsets);
//创建 KafkaFetcher 对象
this.kafkaFetcher =
createFetcher(
sourceContext,
subscribedPartitionsToStartOffsets,
watermarkStrategy,
(StreamingRuntimeContext) getRuntimeContext(),
offsetCommitMode,
getRuntimeContext().getMetricGroup().addGroup(KAFKA_CONSUMER_METRICS_GROUP),
useMetrics);
if (!running) {
return;
if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) {
//调用runFetchLoop,循环消费数据。
kafkaFetcher.runFetchLoop();
} else {
runWithPartitionDiscovery();
}从run方法中看出,主要是通过 kafkaFetcher.runFetchLoop()循环消费数据的。runFetchLoop源码如下:
@Override
public void runFetchLoop() throws Exception {
try {
// 启动kafka消费线程
consumerThread.start();
while (running) {
// 这里会阻塞,直到获取到下一条数据,并且会自动抛出异常。
final ConsumerRecords<byte[], byte[]> records = handover.pollNext();
//从topic的每个partition获取数据
for (KafkaTopicPartitionState<T, TopicPartition> partition :
subscribedPartitionStates()) {
List<ConsumerRecord<byte[], byte[]>> partitionRecords =
records.records(partition.getKafkaPartitionHandle());
//往下游发送数据
partitionConsumerRecordsHandler(partitionRecords, partition);
} finally {
consumerThread.shutdown();
}下面是一个FlinkKafkaConsumer使用的例子:
/**
* 从kafka中获取数据源
* @param env flink env
* @param sourceConfigs 配置信息
* @return ds
public static DataStreamSource<String> getDataStreamSourceFromKafka(StreamExecutionEnvironment env, SourceConfigs sourceConfigs){
Properties properties = SourceConfigs.getProperties(sourceConfigs);
//consumer