


GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval

论文: GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval
Abstract
稠密检索相比于稀疏检索可以克服lexical gap,可以得到更好的检索结果。然而训练稠密检索模型往往需要大量的数据。 BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models 表明领域迁移会极大地影响稠密检索模型的性能。
本文针对稠密检索提出了一种先进的无监督领域适应方法Generative Pseudo Labeling (GPL),使用query生成模型与基于cross-encoder的匹配模型为目标域构造伪标签。 实验结果证明了此方法的有效性,且相比于之前的领域迁移方法更加鲁棒。
本文还 探究了六种近期提出的预训练方法在稠密检索领域迁移任务上的表现 ,只有三种方法有促进作用。其中效果最好的 TSDAE 可以与GPL结合,进一步提升模型性能。
Introduction
稠密检索模型需要大量的训练数据才可表现优异,研究表明其对领域迁移十分敏感。比如,在MS MARCO上训练的检索模型在COVID-19相关文档检索任务中表现很差。MS MARCO数据集是在COVID-19之前创建的,因此它不包括任何与COVID-19相关的主题,模型无法学习如何在向量空间中很好地表示该主题。
针对此问题,本文提出Generative Pseudo Labeling (GPL),具体流程如下图所示。

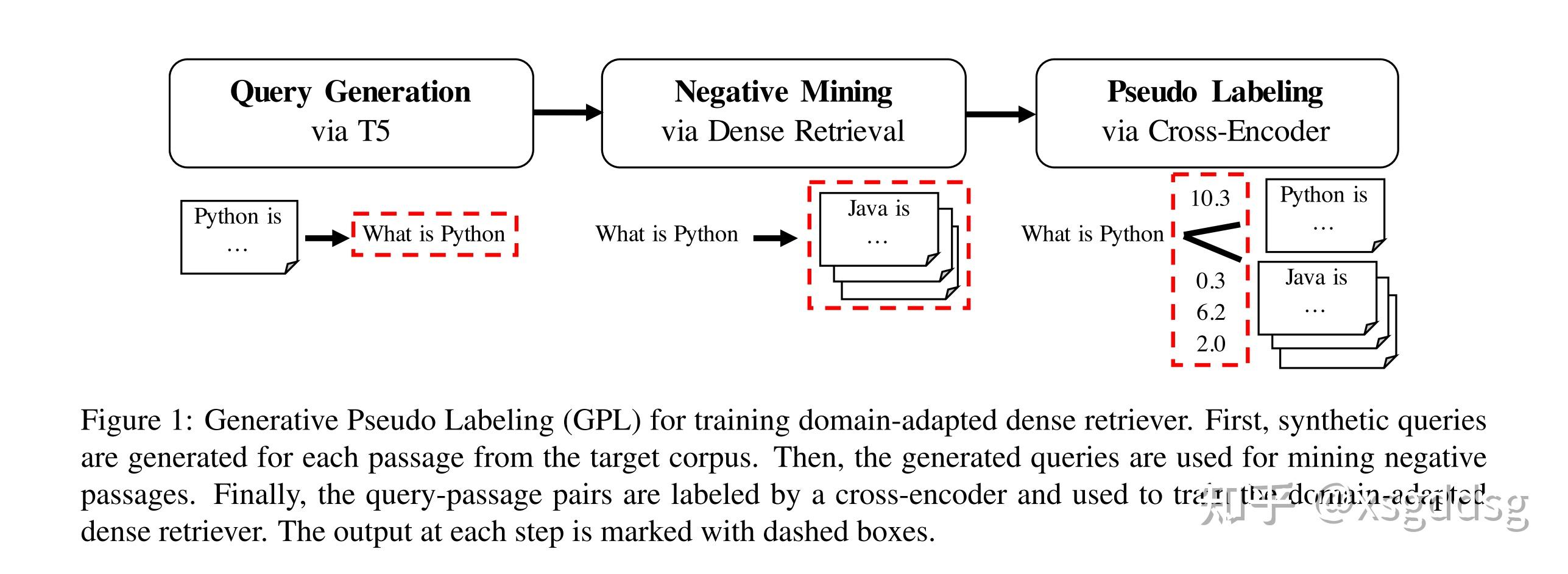
- 首先使用预训练T5模型根据目标域passage生成对应的query;
- 之后使用稠密检索模型为每个query挖掘负样本;
- 最后,使用cross-encoder为每个query-passage对打分,为目标域稠密检索模型的训练构造伪标签。
流程中使用到的T5、稠密检索模型、cross-encoder均为现有的在MS MARCO数据集上预训练过的模型。
Related Work
Pre-Training based Domain Adaptation
对于transformer模型,最常用的领域适应方法是 基于域自适应的预训练,该方法的基本做法是在使用标签数据对模型进行微调之前,先使用目标域数据对模型进行预训练 。然而对于检索任务,目标域标签数据往往难以获得,因此需进行零样本学习。除MLM(Masked Language Modeling)外,还有一些针对稠密检索的其他预训练策略,具体如下。
- ICT( Latent Retrieval for Weakly Supervised Open Domain Question Answering , ACL 2019)通过从passage中随机选择一个句子作为query,剩余的部分作为配对的passage,生成query-passage对。
- CD( Condenser: a Pre-training Architecture for Dense Retrieval , EMNLP 2021)提出针对稠密检索的预训练模型Condenser,改变现有MLM的结构以迫使模型学习有意义的CLS表示。
- SimCSE( SimCSE: Simple Contrastive Learning of Sentence Embeddings , EMNLP 2021)将同一句句子输入到具有不同dropout的网络中两次,最小化两次结果的距离。
- CT(Semantic Re-tuning with Contrastive Tension, ICLR 2021)与SimCSE类似,不同的是其将句子输入到不同的两个模型中。
- TSDAE( TSDAE: Using Transformer-based Sequential Denoising Auto-Encoder for Unsupervised Sentence Embedding Learning , EMNLP 2021 finding )使用具有瓶颈的去噪自编码器架构:从输入文本中删除单词,并通过编码器生成固定大小的embedding,解码器须重构原始文本。
ICT、CD仅被研究用于域内的性能,即在预训练之后,有大量标签数据用于后续有监督的微调。SimCSE, CT, TSDAE仅用于无监督的句子向量学习。直接使用利用这些策略学习到的句子表示用来检索,其性能远远不足。

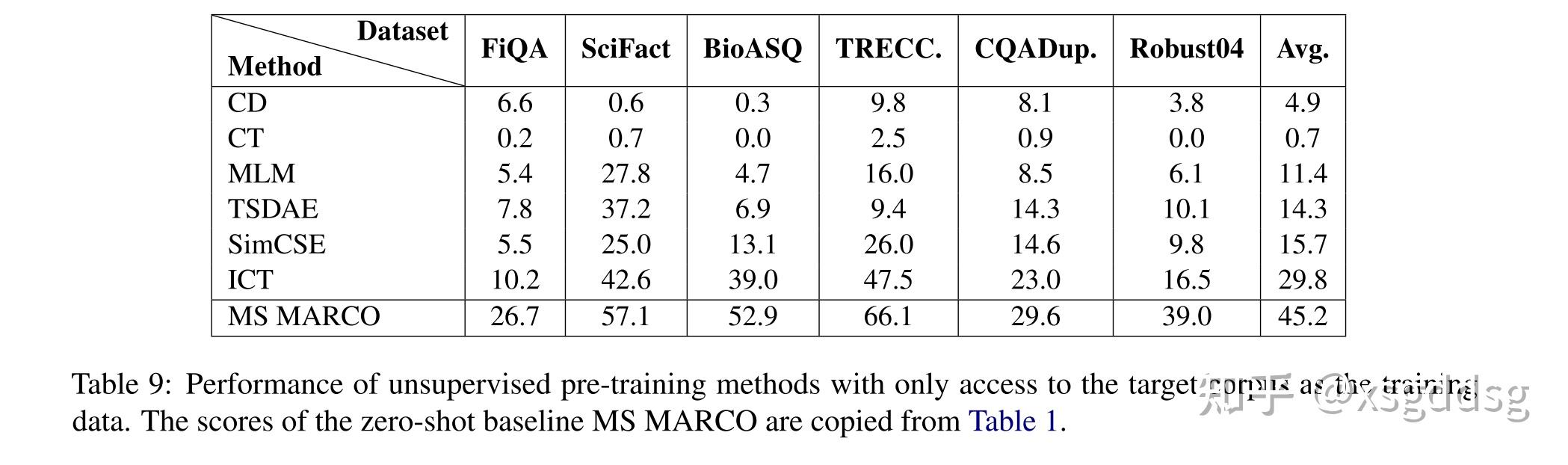
目前这些预训练方法是否可以用于稠密检索的无监督领域适应还不明确。 本文首先使用这些这些策略在目标域文本上进行预训练,之后在MS MARCO数据集上微调模型来实现稠密检索的领域迁移,并探究其效果。
Query Generation
一些工作通过query生成来提升检索模型的性能。
- Doc2query( Document Expansion by Query Prediction )使用预测的查询进行文档扩展,之后使用BM25来检索文档。
- QGen( Zero-shot Neural Passage Retrieval via Domain-targeted Synthetic Question Generation , EACL 2021)使用通用领域训练的query生成器在目标域生成query构造合成数据,之后稠密检索模型根据合成数据从零开始训练。
尽管QGen很有效, 训练检索模型时损失使用的是批内负样本的交叉熵损失,这仅提供了粗粒度的相关性,因此限制了模型的性能 。本文使用考虑困难样本的cross-encoder提供的伪标签来提升模型性能。
Other Methods
- MoDIR( Zero-Shot Dense Retrieval with Momentum Adversarial Domain Invariant Representations )使用域对抗训练(DAT)用于稠密检索的无监督领域适应。
- UDALM( UDALM: Unsupervised Domain Adaptation through Language Modeling , NAACL 2021)采用多阶段训练,首先在目标域使用MLM预训练,之后采用目标域MLM与源域有监督目标进行多任务学习。
Pseudo Labeling and Cross-Encoders
不同于双塔式结构,cross-encoder将query和passage进行拼接后通过cross-attention预测相关性分数,通常用于精排阶段。相关研究表明cross-encoder相比于稠密检索模型具有更好的性能和领域适应能力。但由于其较高的计算开销,不太适用于检索,但检索模型可从cross-encoder中蒸馏知识以提升性能。
Method
Introduction部分已介绍本文所提出GPL的基本结构,此处不再赘述。此处主要介绍本文方法相比于QGen的区别。
QGen进行query生成后,使用MultipleNegativesRanking (MNRL) 损失训练检索模型:
L_{\mathrm{MNRL}}(\theta)= -\frac{1}{M} \sum_{i=0}^{M-1} \log \frac{\exp \left(\tau \cdot \sigma\left(f_{\theta}\left(Q_{i}\right), f_{\theta}\left(P_{i}\right)\right)\right)}{\sum_{j=0}^{M-1} \exp \left(\tau \cdot \sigma\left(f_{\theta}\left(Q_{i}\right), f_{\theta}\left(P_{j}\right)\right)\right)} \\
其中 Q 表示query, P 表示passage, M 表示batch size, \tau 控制softmax归一化的尖锐程度。
QGen存在一些弊端:MNRL损失仅考虑了query与passage之间的粗粒度相关性;query生成器可能生成不能被输入passage回答的query;存在其他passage可能与query相关的情况,即假负例的问题。
本文使用cross-encoder提供的伪标签和MarginMSE损失来训练模型,使稠密检索模型模仿query与正负passage之间的得分差异。
L_{\text {MarginMSE }}(\theta)=-\frac{1}{M} \sum_{i=0}^{M-1}\left|\hat{\delta}_{i}-\delta_{i}\right|^{2} \\
其中 \hat{\delta}_{i}=f_{\theta}\left(Q_{i}\right)^{T} f_{\theta}\left(P_{i}\right) - f_{\theta}\left(Q_{i}\right)^{T} f_{\theta}\left(P_{i}^{-}\right) ,为稠密检索模型的得分差 。
MarginMSE损失解决了两个关键问题:当query生成器生成的query质量较低时,其cross-encoder分数也会比较低,此时稠密检索模型不会使query和passage在向量空间中过于接近。假负例会在cross-encoder中得到高分,相应的向量也不会被拉得很远。
Experiments
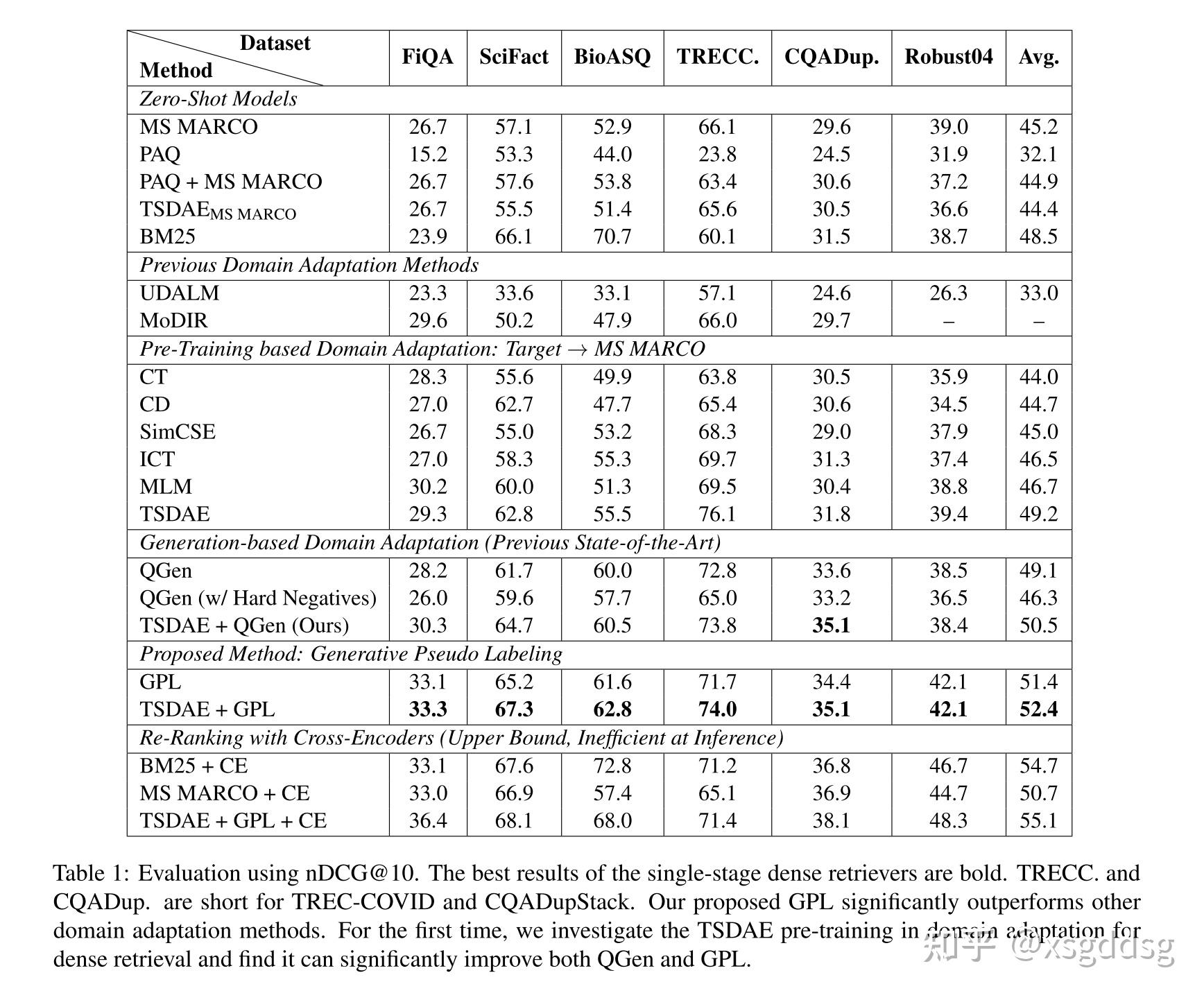
选择六个特定领域来检测模型的领域适应能力,包括FiQA (financial domain) , SciFact (scientific papers) , BioASQ (biomedical Q&A) , TREC-COVID(scientific papers on COVID-19), CQADupStack (12 StackExchange sub-forums), Robust04 (news articles)。使用nDCG@10作为评估指标。实验结果如下表所示,与多个baseline相比可见GPL的有效性。

Analysis
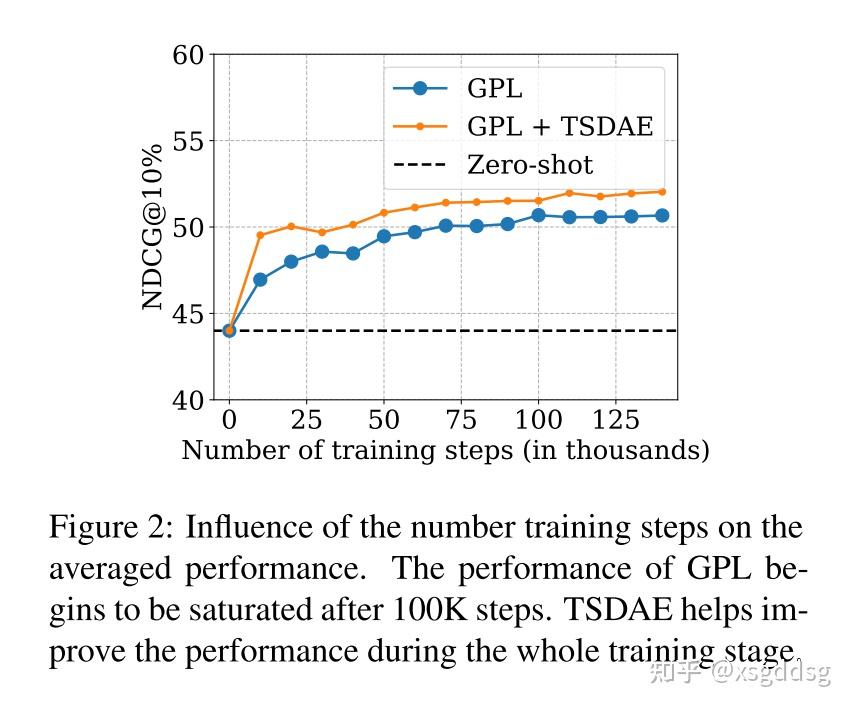
此部分分析了训练步数、语料库数量、query生成、开始checkpoint对GPL模型的影响。


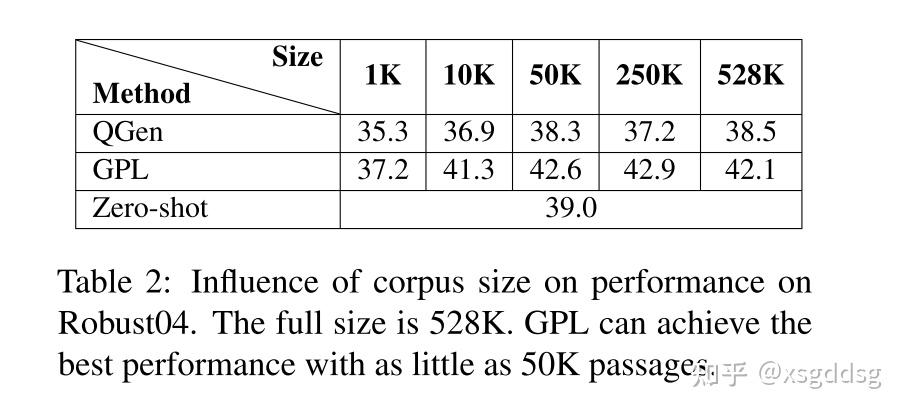

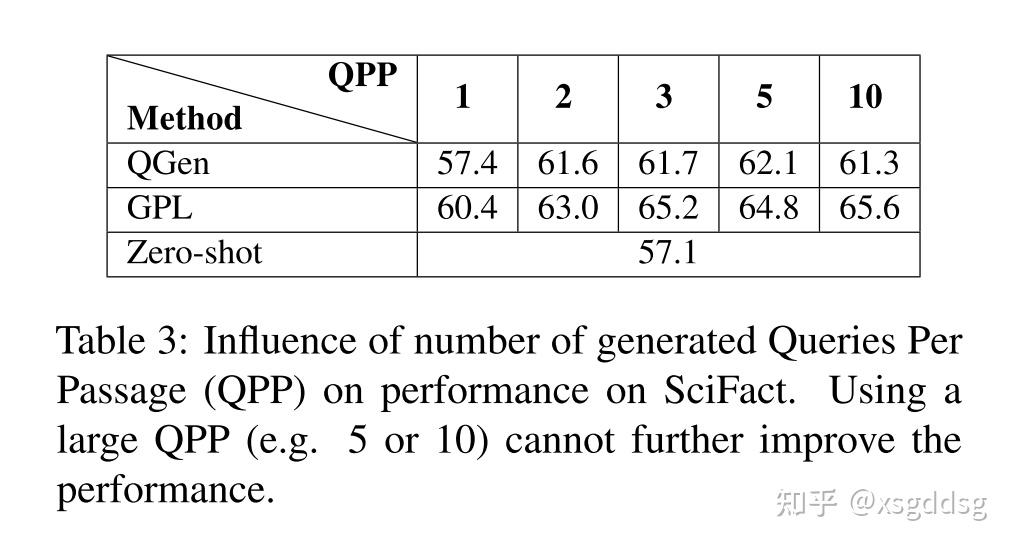

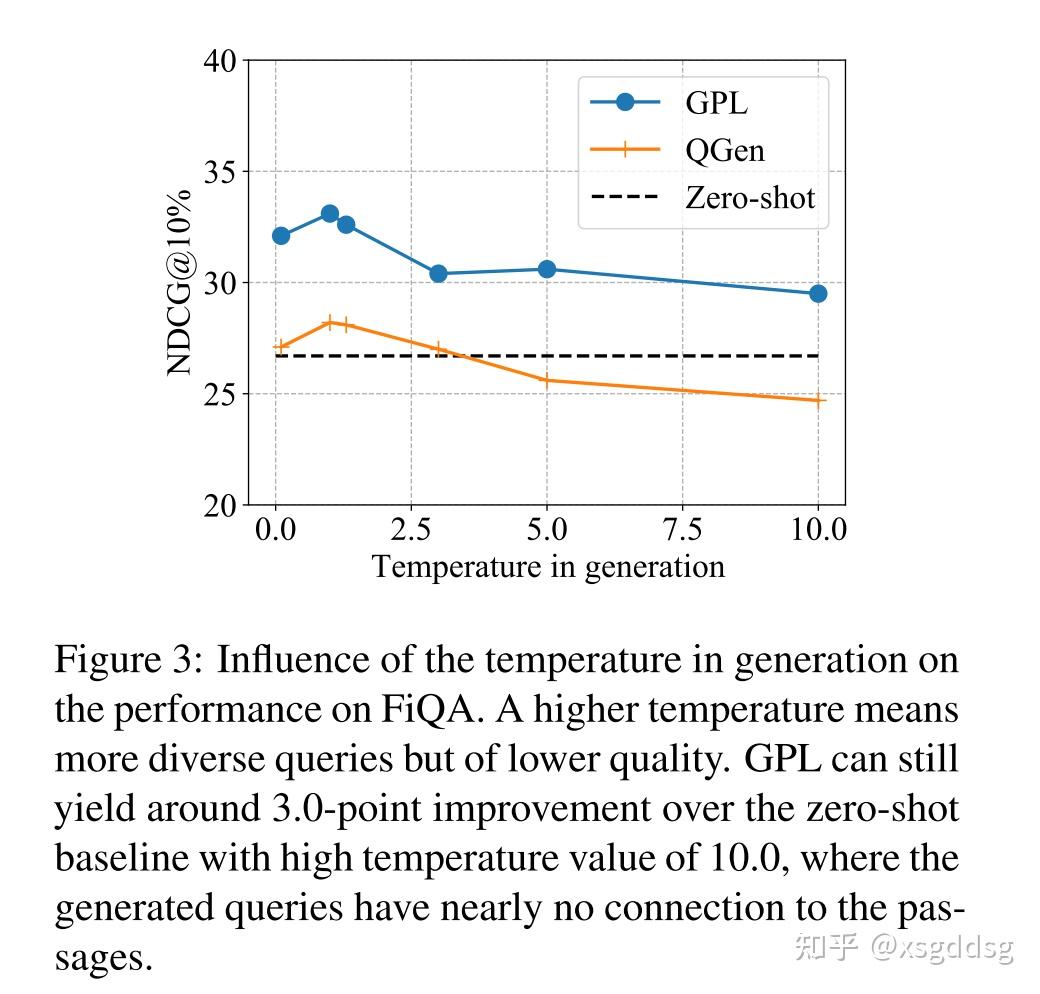

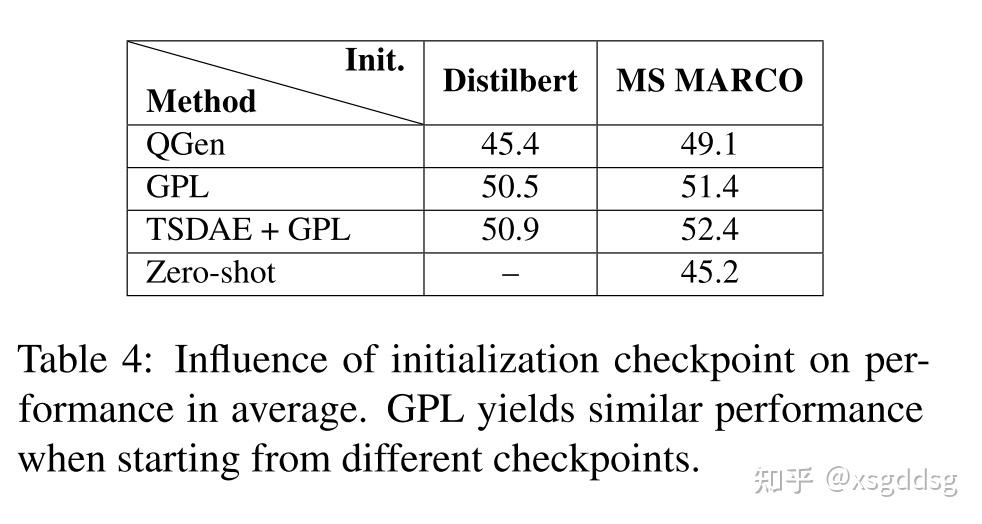
Conclusion
本文提出GPL,一种稠密检索的无监督领域适应方法,通过query生成模型为目标域passage生成qurey并使用cross-encoder构造伪标签,克服了以往方法的两个重要缺点:query质量无法保证及假负例的问题。GPL在所有目标数据集上的表现超越了之前的方法。
本文还探究了多个预训练策略在领域适应上的表现,ICT和MLM可以带来少许提升,TSDAE可以带来较为明显的提升,其他方法反而对性能有损。
模型的领域适应本质上是对源域训练的模型进行修正或补充,因此设计与目标任务更接近的预训练策略或为目标任务构造对模型修正有效的训练数据均可以提高模型在目标域的表现。
