来源: PaperWeekly
本文约1700字,建议阅读5分钟本文中各类 forest-based methods 主要从 split 和 predict 两个角度展开,忽略渐进高斯性等理论推导。
1. Random Forest
传统随机森林由多棵决策树构成,每棵决策树在第 i 次 split 的时候,分裂准则如下(这里关注回归树):
其中 表示在 的划分情况下, 所在的叶子结点。随机森林构建完成后,给定测试数据 ,预测值为:
2. Causal Forest
类似地,因果森林由多棵因果树构成,由于需要 Honest estimation(用互不重合的数据 分别进行 split 和 estimate),因此相较于决策树,每棵因果树 split 的分裂准则修改如下:
在叶子结点内可以认为所有样本同质,所以因果森林构建完成后,给定测试数据 ,其预测值为:
3. Generalized Random Forest
广义随机森林可以看作是对随机森林进行了推广:原来随机森林只能估计观测目标值 ,现在广义随机森林可以估计任何感兴趣的指标 。
3.1 predict
先假设我们在已经有一棵训练好的广义随机森林,现在关注给定测试数据,如何预测我们感兴趣的指标?
通过公式 (2) 和 (3),传统随机森林预测的做法是:
1. 在单棵树中,将测试数据 所在叶子结点的观测目标值取平均作为该树对 的预测;
2. 在多棵树中,将单棵树的不同预测结果取平均作为最终的预测结果。
而在广义随机森林中,首先基于因果森林得到各数据 相对于测试数据 的权重 ,之后加权求解局部估计等式,具体地:
权重估计阶段:
将数据 与测试数据 在同一叶子结点中的“共现频率”作为其权重,如下:
加权求解局部估计等式阶段:
下式中 表示我们感兴趣的参数, 表示我们不感兴趣但必须估计的参数, 表示观测到的与我们感兴趣的参数相关的值。
在 predict 阶段,我们可以证明,随机森林恰好是广义随机森林的一个特例,证明如下:
首先,在随机森林的 setting 下,,我们感兴趣的参数恰好是 ;
极大似然函数为 ,其 score function 为 ;
因此公式 (11) 为:
因此有 ,可得:
3.2 split
首先,由于广义随机森林的目标是准确估计感兴趣的参数 ,因此针对单一节点 与一组样数据 ,估计参数 的方法是:
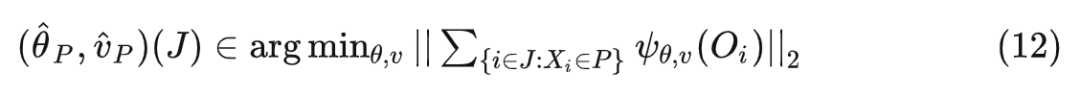
接着,我们要将节点 P 分裂为两个子节点 ,分裂的目标是极小化感兴趣的参数的误差:
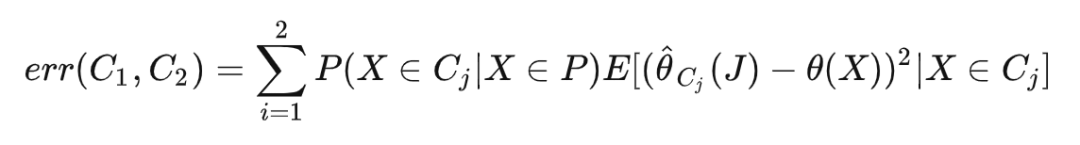 但是实际上 是不可见的,经过一番推导,最终可以发现最小化 等价于最大化下面的公式:
但是实际上 是不可见的,经过一番推导,最终可以发现最小化 等价于最大化下面的公式:
也就是说,最小化感兴趣的参数的误差等价于最大化两个子节点的异质性。
如果每个 都通过求解式 (12) 获得,那算法的计算复杂度非常高,因此可以通过 gradient-based 的方法去得到 的近似解:
至此,我们可以将 split 分成两个阶段:
标记阶段:
计算父节点的 ,之后针对每个样本计算虚拟的目标值:
回归阶段:
分裂准则为最大化式 (14):
在 split 阶段,也可以证明随机森林是广义随机森林的一个特例:
首先,在随机森林的 setting 下,score function 为 ;
3.3 局部估计等式
在广义随机森林中,假设下列的数据产生过程:
这里 ,有:
此时 相当于:
带上权重 的时候类似。
3.4 other
causal forest 和 generalized random forest 的分裂准则其实是等价的,只不过式 (4) 考虑了下式的 b 和 c 两部分,式 (13)/(15) 只考虑了 b 部分:
4. Orthogonal Random Forest
orthogonal random forest 只是在 generalized random forest 的基础上进行了两个改动:
加了 DML:在一开始先拟合 ,得到残差(first stage);再对残差跑 generalized random forest(second stage)。与广义随机森林的 score function (16) 相比,正交随机森林的 score function 的定义如下:
此时 相当于:
带上权重 的时候类似:
在 predict 阶段强调 locally,即拟合 的时候(DML 的 first stage)使用上权重 。
5. TO DO
记录一个还没想明白的问题,路过的大佬有懂的欢迎讨论。
到这里我们可以发现一个节点内的数据的 HTE 有两种计算方式:
一种是如式 (8) 所示,直接计算不同 treatment 组的期望相减,即 ;
另外一种是求解式 (12) 的局部估计等式。
在随机森林假设的线性 treatment effect 的情况下,这两种计算本质上是等价的。那为什么式 (13) 中的 不能直接用第一种方式求,而是要大费周章地用梯度去近似呢?
目前的结论:上述等价性成立的前提是线性 effect 和二元 treatments 假设,第二种计算方式可以推广到多元甚至连续 treatments。
[1] Athey S, Imbens G. Recursive partitioning for heterogeneous causal effects[J]. Proceedings of the National Academy of Sciences, 2016, 113(27): 7353-7360.
[2] Wager S, Athey S. Estimation and inference of heterogeneous treatment effects using random forests[J]. Journal of the American Statistical Association, 2018, 113(523): 1228-1242.
[3] Athey S, Tibshirani J, Wager S. Generalized random forests[J]. The Annals of Statistics, 2019, 47(2): 1148-1178.
[4] Oprescu M, Syrgkanis V, Wu Z S. Orthogonal random forest for causal inference[C]//International Conference on Machine Learning. PMLR, 2019: 4932-4941.
编辑:王菁
校对:林亦霖
来源:PaperWeekly本文约1700字,建议阅读5分钟本文中各类 forest-based methods 主要从 split 和 predict 两个角度展开,忽略渐进高斯性等理论推导。1. Random Forest传统随机森林由多棵决策树构成,每棵决策树在第 i 次 split 的时候,分裂准则如下(这里关注回归树):其中表示在的划分情况下,所在的叶子结点。随机森林构建...
近年来,
因果
推断逐渐成为了
机器学习
中的热点话题。增益
模型
(Uplift Model)作为工业界
因果
推断与
机器学习
结合最成熟的
算法
之一,在智能营销中有着广泛的应用。但是目前大多数增益
模型
仅讨论了二元处理变量情况下的处理
效应
估计
,然而在网约车市场中存在大量多维、连续的处理变量。针对这一困境,我们构造了连续
因果
森林
模型
,并成功地应用在了网约车交易市场策略上。
在网约车供需策略技术基础能力团队,我们最关注的工作之一就是量化价格对网约车供需关系的影响。这对于精细化定价补贴策略的制定和优化有着重要的.
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录随机
森林
模型
一、随机
森林
模型
1.数据加载二、数据清洗2.1.删除变量2.2变量数据类型转换2.3划分训练集和测试集三、随机
森林
分析3.1建模分析3.2
模型
优化
总结
随机
森林
模型
首先:安装需要的几个R语言包:ggplot2,VIM,ggrepel
数据说明:
森林
顾名思义就是有很多
树
,这里的
树
当然就是决策
树
。实际上随机
森林
就是将 fully-grown C&RT decision tree 作为 bagging 基
模型
(base model)。
random forest (RF) = bagging + fully-grown C&RT decision...
这是使用python
因果
森林
模型
计算处理
效应
异质
性的代码示例: import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor # 读取数据
data = pd.read_csv('data.csv') # 定义自变量和因变量
X = data[['var1','var2','var3','var4','var5','var6','var7','var8','var9','var10']]
y = data['output'] # 使用
因果
森林
模型
计算处理
效应
异质
性
rf = RandomForestRegressor(n_estimators=1000, max_features=3, random_state=42, oob_score=True)
rf.fit(X,y)
heterogeneity_effect = rf.oob_score_ print('Heterogeneity effect:', heterogeneity_effect)

