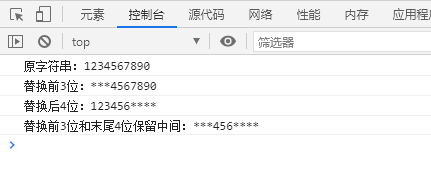
console
.
log
(
'原字符串:'
+
str
)
console
.
log
(
'替换前3位:'
+
str
.
replace
(
/
^.{3}
/
,
'***'
)
)
console
.
log
(
'替换后4位:'
+
str
.
replace
(
/
.{4}$
/
,
'****'
)
)
console
.
log
(
'替换前3位和末尾4位保留中间:'
+
str
.
replace
(
/
^.{3}(.*).{4}$
/
,
'***$1****'
)
)
运行结果截图
我们经常需要获得某个标签开始和结束之间的内容,
javascript
如何实现获得以{
开头
,以}
结尾
的内容呢?这里还是得用到
正则表达式
,我们看看具体怎么实现?
<!DOCTYPE
html
>
<
html
xmlns="http://www.w3.org/1999/x
html
">
<title>
js
正则匹配
以{
开头
,以}
结尾
怎么写?</title>
<meta http-equiv="Content-Type" con
{}:设置区间,可出现几次到几次
<a href="
javascript
:prn_p1()">点击获取</a><br>
<script language="
javascript
" type="text/
javascript
">
var LODOP; //声明为全局变量
function prn_p1(){
(?:pattern)
()表示捕获分组,()会把每个分组里的匹配的值保存起来,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推
(?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来
import re
a = "123abc456"
pattern = "([0-9]*)([a-z]*)([0-9]*)"
pr...
正则表达式
用于定义一些
字符串
的规则,计算机可以根据
正则表达式
,来检查一个
字符串
是否符合规则,获取将
字符串
中符合规则的内容提取出来语法:
使用检查正则对象,会返回
2、正则方法
正则表达式
的方法:使用这个方法可以用来检查一个
字符串
是否符合
正则表达式
的规则,如果符合则返回,否则返回
在构造函数中可以传递一个匹配模式作为第二个参数,可以是
3、正则语法
使用字面量来创建
正则表达式
,语法:使用字面量的方式创建更加简单;使用构造函数创建更加灵活
使用表示或者的意思
里的内容也是或的关系:
任意小写字母
任意大写字母
2017-05-15
.*匹配除 \n 以外的任何
字符
。 /[\u4E00-\u9FA5]/ 汉字 /[\uFF00-\uFFFF]/ 全角符号 /[\u0000-\u00FF]/ 半角符号 --------------------- 这个正则我写的,仔细想了之后,这个答案还不够严谨,例如末尾为aba,这个应当是符合规则的,但会被这个正则报false,上面提到的三点应该是或者的关系,只要...
var str='12#$[22@@JL]444[[你是]11[——+][]';
var reg=/\[([^\[\]])*\]/g; //[^\[\]]匹配除[]以外的全部
字符
,因[ ]是特殊
字符
,所以需要\转义
var des=str.replace(reg,(ev)=>{
return ' '+ev+' '
console.log(des);
输出:12#$ [...
正则表达式
(regular expression)描述了一种
字符串
匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做
替换
或者从某个串中取出符合某个条件的子串等。
var inReg = new RegExp("[a-zA-Z\u4e00-\u9fa5]");
var inputContent = "123ABC321";
// 如果开始时数字
var regstart = new RegExp("^
正则表达式
目的在于处理
字符串
的查找、验证、修改、
替换
var reg1 = new RegExp('s','g'); // 构造函数的写法
var reg2 = /s\d?/g; // 字面量写法
2.
正则表达式
方法
test():判断
字符串
是否存在符合
正则表达式
的子
字符串
,存在返回true,反之返回false
exec():返回一个数组,包括符合
正则表达式
条件的子
字符串
的元素和位置
javaprivate static String getQuestionResolution(String
html
){String regex = "【解析】([\\s\\S]*?)【";Matcher matcher = Pattern.compile(regex).matcher(
html
);if (matcher.find()){return matcher.group(1).trim(...
在
字符串
处理中,
正则表达式
是一大利器,但其对于初学者而言是存在一定的难度的。
而如何匹配以xx
开头
以xx
结尾
的单词呢?假设需要匹配的
字符串
为:site sea sue sweet see case sse ssee loses
需要匹配的为以s
开头
以e
结尾
的单词。
正确的正则式为:\bs\S*?e\b无论什么语言的正则的格式都一样,下面以python为例来进行代码演示:
解释一下:在pyt

