


《PostgreSQL 开发指南》第 21 篇 窗口函数

为了方便大家阅读学习,制作了专栏的电子版PDF,免费开放下载: https:// github.com/dongxuyang19 85/postgresql_dev_guide
在专栏的 第 13 篇 中我们学习了常见的聚合函数,包括 AVG、COUNT、MAX、MIN、SUM 以及 STRING_AGG。聚合函数的作用是针对一组数据行进行运算,并且返回一条汇总结果。
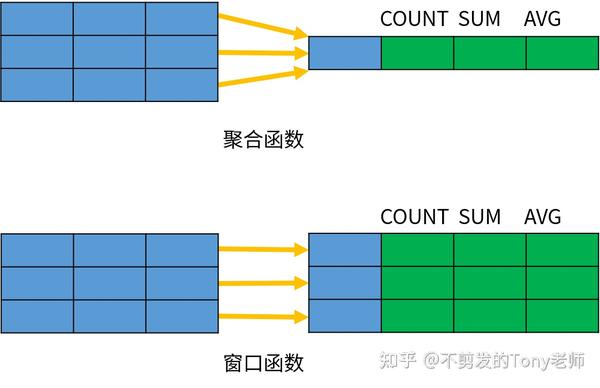
除了聚合函数之外,SQL 还定义了许多专门用于数据分析的窗口函数(Window Function)。但是,窗口函数不是将一组数据汇总为单个结果;而是针对每一行数据,基于和它相关的一组数据计算出一个结果。下图演示了聚合函数和窗口函数的效果:

以下示例分别将 AVG、COUNT、SUM 作为聚合函数和窗口函数,计算员工的平均月薪、人数总和以及月薪总和:
SELECT AVG(salary), COUNT(*), SUM(salary)
FROM employees;
avg |count|sum |
---------------------|-----|---------|
6461.8317757009345794| 107|691416.00|
SELECT employee_id,first_name, last_name, AVG(salary) OVER (), COUNT(*) OVER (), SUM(salary) OVER ()
FROM employees;
employee_id|first_name |last_name |avg |count|sum |
-----------|-----------|-----------|---------------------|-----|---------|
100|Steven |King |6461.8317757009345794| 107|691416.00|
101|Neena |Kochhar |6461.8317757009345794| 107|691416.00|
102|Lex |De Haan |6461.8317757009345794| 107|691416.00|
...
聚合函数通常也可以作为窗口函数,区别在于后者包含了
OVER
关键字;空括号表示将所有数据作为整体进行分析,所以得到的数值和聚合函数一样。显然,窗口函数为每一个员工都返回了一个结果。
窗口函数的定义
窗口函数的定义如下:
window_function ( expression, ... ) OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)
其中,window_function 是窗口函数的名称;expression 是参数,有些函数不需要参数;
OVER
子句包含三个选项:分区(
PARTITION BY
)、排序(
ORDER BY
)以及窗口大小(
frame_clause
)。
分区选项(PARTITION BY)
PARTITION BY
选项用于定义分区,作用类似于
GROUP BY
的分组。如果指定了分区选项,窗口函数将会分别针对每个分区单独进行分析;如果省略分区选项,所有的数据作为一个整体进行分析,上文中的示例就是如此。
以下语句按照部门进行分组,分析每个部门的平均月薪:
SELECT first_name, last_name, department_id, salary, AVG(salary) OVER (PARTITION BY department_id)
FROM employees
ORDER BY department_id;
first_name |last_name |department_id|salary |avg |
-----------|-----------|-------------|--------|----------------------|
Jennifer |Whalen | 10| 4400.00| 4400.0000000000000000|
Pat |Fay | 20| 6000.00| 9500.0000000000000000|
Michael |Hartstein | 20|13000
.00| 9500.0000000000000000|
Shelli |Baida | 30| 2900.00| 4150.0000000000000000|
Karen |Colmenares | 30| 2500.00| 4150.0000000000000000|
Den |Raphaely | 30|11000.00| 4150.0000000000000000|
...部门 10 只有一个员工,平均月薪就是她自己的月薪 4400;部门 20 有两个员工,平均月薪等于 (6000 + 13000)/2 = 9500;其他数据依次类推。
排序选项(ORDER BY)
ORDER BY
选项用于指定
分区内
的排序方式,通常用于数据的排名分析。以下示例用于计算每个员工在部门内的入职顺序:
SELECT first_name, last_name, department_id, hire_date,
RANK() OVER (PARTITION BY department_id ORDER BY hire_date)
FROM employees
ORDER BY department_id;
first_name |last_name |department_id|hire_date |rank|
-----------|-----------|-------------|----------|----|
Jennifer |Whalen | 10|2003-09-17| 1|
Michael |Hartstein | 20|2004-02-17| 1|
Pat |Fay | 20|2005-08-17| 2|
Den |Raphaely | 30|2002-12-07| 1|
Alexander |Khoo | 30|2003-05-18| 2|
Sigal |Tobias | 30|2005-07-24| 3|
...
其中,
PARTITION BY
选项表示按照部门进行分区;
ORDER BY
选项指定在部门内按照入职先后进行排序;RANK 函数用于计算名次,下文将会进行介绍。
部门 10 只有一个员工,Jennifer Whalen 就是第一个入职的员工;部门 20 有两个员工,Michael(2004-02-17)比 Pat(2005-08-17)入职更早;其他数据依次类推。
ORDER BY
子句同样支持 NULLS FIRST 和 NULLS LAST 选项,用于指定空值的排序顺序。默认为 NULLS LAST。
窗口选项(frame_clause)
frame_clause
选项用于在
当前分区
内指定一个计算窗口。指定了窗口之后,分析函数不再基于分区进行计算,而是基于窗口内的数据进行计算。以下示例用于计算每个产品当当前月份的累计销量(
示例数据
):
SELECT product AS "产品", ym "年月", amount "销量",
SUM(amount) OVER (PARTITION BY product ORDER BY ym ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM sales_monthly
ORDER BY product, ym;
产品|年月 |销量 |sum |
----|------|--------|---------|
桔子|201801|10154.00| 10154.00|
桔子|201802|10183.00| 20337.00|
桔子|201803|10245.00| 30582.00|
桔子|201804|10325.00| 40907.00|
桔子|201805|10465.00| 51372.00|
桔子|201806|10505.00| 61877.00|
其中,
PARTITION BY
选项表示按照产品进行分区;
ORDER BY
选项表示按照日期进行排序;窗口子句
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
指定窗口从当前分区的第一行开始到当前行结束;因此 SUM 函数计算的是产品累计到当前月份为止的销量合计。
具体来说,窗口大小的常用选项如下:
{ ROWS | RANGE } frame_start
{ ROWS | RANGE } BETWEEN frame_start AND frame_end
其中,
ROWS
表示以行为单位计算窗口的偏移量,
RANGE
表示以数值(例如 30 分钟)为单位计算窗口的偏移量。其中,frame_start 用于定义窗口的起始位置,可以指定以下内容之一:
-
UNBOUNDED PRECEDING,窗口从分区的第一行开始,默认值; -
N PRECEDING,窗口从当前行之前的第 N 行或者数值开始; -
CURRENT ROW,窗口从当前行开始。
frame_end 用于定义窗口的结束位置,可以指定以下内容之一:
-
CURRENT ROW,窗口到当前行结束,默认值; -
N FOLLOWING,窗口到当前行之后的第 N 行或者数值结束; -
UNBOUNDED FOLLOWING,窗口到分区的最后一行结束。
下图可以方便我们理解这些选项的含义:
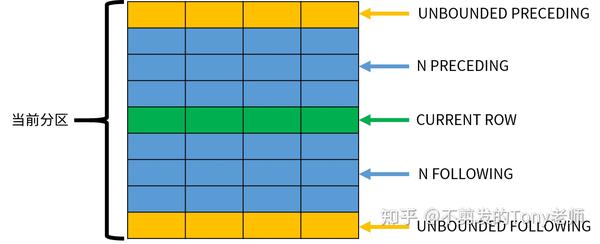

CURRENT ROW
表示当前正在处理的行;其他的行可以使用相对当前行的位置表示。需要注意,窗口的大小不会超出当前分区的范围。
PostgreSQL 还提供了更多复杂的窗口选项,可以参考 官方文档 。
常见的窗口函数可以分为以下几类:聚合窗口函数、排名窗口函数以及取值窗口函数。
聚合窗口函数
常用的聚合函数,例如 AVG、SUM、COUNT 等,也可以作为窗口函数使用。上文我们已经列举了一些聚合窗口函数的示例,再来看一个使用 AVG 函数计算移动平均值的例子:
SELECT saledate, amount, avg(amount) OVER (ORDER BY saledate ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
FROM sales_data
WHERE product = '桔子' AND channel = '淘宝';
saledate |amount |avg |
----------|-------|---------------------|
2019-01-01|1864.00|1893.5000000000000000|
2019-01-02|1923.00|1505.3333333333333333|
2019-01-03| 729.00|1066.3333333333333333|
2019-01-04
| 547.00| 966.6666666666666667|
2019-01-05|1624.00|1272.0000000000000000|
2019-01-06|1645.00|1332.0000000000000000|
...该语句返回了“桔子”在“淘宝”上的销量,以及每一天和它前后一天(共 3 天)的平均销量。
移动平均值通常用于处理时间序列的数据。例如,厂房的温度检测器获取了每秒钟的温度,我们可以使用以下窗口计算前五分钟内的平均温度:
avg(temperature) OVER (ORDER BY ts RANGE BETWEEN interval '5 minute' PRECEDING AND CURRENT ROW)排名窗口函数
排名窗口函数用于对数据进行分组排名。常见的排名窗口函数包括:
- ROW_NUMBER ,为分区中的每行数据分配一个序列号,序列号从 1 开始分配。
- RANK ,计算每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
- DENSE_RANK ,计算每行数据在其分区中的名次;即使存在名次相同的数据,后续的排名也是连续的值。
- PERCENT_RANK ,以百分比的形式显示每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
- CUME_DIST ,计算每行数据在其分区内的累积分布,也就是该行数据及其之前的数据的比率;取值范围大于 0 并且小于等于 1。
- NTILE ,将分区内的数据分为 N 等份,为每行数据计算其所在的位置。
排名窗口函数不支持动态的窗口大小(frame_clause),而是以当前分区作为分析的窗口。
以下示例按照部门为单位,计算员工的月薪排名:
SELECT d.department_name "部门名称", concat(e.first_name, ',' , e.last_name) "姓名", e.salary "月薪",
ROW_NUMBER() OVER (PARTITION BY e.department_id ORDER BY e.salary DESC) AS "row_number",
RANK() OVER (PARTITION BY e.department_id ORDER BY e.salary DESC) AS "rank",
DENSE_RANK() OVER (PARTITION BY e.department_id ORDER BY e.salary DESC) AS "dense_rank",
PERCENT_RANK() OVER (PARTITION BY e.department_id ORDER BY e.salary DESC) AS "percent_rank"
FROM employees e
JOIN departments d ON (e.department_id = d.department_id)
WHERE d.department_name in ('IT', 'Purchasing')
ORDER BY 1, 4;
部门名称 |姓名 |月薪 |row_number|rank|dense_rank|percent_rank|
----------|----------------|--------|----------|----|----------|------------|
IT |Alexander,Hunold| 9000.00| 1| 1| 1| 0|
IT |Bruce,Ernst | 6000.00| 2| 2| 2| 0.25|
IT |Valli,Pataballa | 4800.00| 3| 3| 3| 0.5|
IT |David,Austin | 4800.00| 4| 3| 3| 0.5|
IT |Diana,Lorentz | 4200.00| 5| 5| 4| 1|
Purchasing|Den,Raphaely |11000.00| 1| 1| 1| 0|
Purchasing|Alexander,Khoo | 3100.00| 2| 2| 2| 0.2|
Purchasing|Shelli,Baida | 2900.00| 3| 3| 3| 0.4|
Purchasing|Sigal,Tobias | 2800.00| 4| 4| 4| 0.6|
Purchasing|Guy,Himuro | 2600.00| 5| 5| 5| 0.8|
Purchasing|Karen,Colmenares| 2500.00| 6| 6| 6| 1|ROW_NUMBER 函数为每个员工分配了一个连续的数字编号,可以看作是一种排名。IT 部门的“Valli,Pataballa”和“David,Austin”的月薪相同,但是编号不同;
RANK 函数为每个员工指定了一个名次,IT 部门的“Valli,Pataballa”和“David,Austin”的名次都是 3;而且在他们之后的“Diana,Lorentz”的名次为 5,产生了跳跃;
DENSE_RANK 函数为每个员工指定了一个名次,IT 部门的“Valli,Pataballa”和“David,Austin”的名次都是 3;在他们之后的“Diana,Lorentz”的名次为 4,名次是连续值;
PERCENT_RANK 函数按照百分比指定名次,取值位于 0 到 1 之间。其中“Diana,Lorentz”的百分比排名为 1,也产生了跳跃。
以上示例中 4 个窗口函数的 OVER 子句完全相同,此时可以采用一种更简单的写法:
SELECT d.department_name "部门名称", concat(e.first_name, ',' , e.last_name) "姓名", e.salary "月薪",
ROW_NUMBER() OVER w AS "row_number",
RANK() OVER w AS "rank",
DENSE_RANK() w AS "dense_rank",
PERCENT_RANK() w AS "percent_rank"
FROM employees e
JOIN departments d ON (e.department_id = d.department_id)
WHERE d.department_name in ('IT', 'Purchasing')
WINDOW w AS (PARTITION BY e.department_id ORDER BY e.salary DESC)
ORDER BY 1, 4;
其中,
WINDOW
定义了一个窗口变量 w,然后在窗口函数的 OVER 子句中使用了该变量;这样可以简化函数的输入。
窗口函数在GROUP BY分组、聚合函数以及HAVING过滤之后运行。如果多个窗口函数拥有相同的PARTITION BY和ORDER BY选项,它们会在遍历数据时一起进行计算,也就是说它们读取输入数据的顺序完全一致。
以下语句演示了 CUME_DIST 和 NTILE 函数的作用:
SELECT concat(first_name, ',' , last_name) "姓名", hire_date AS "入职日期",
CUME_DIST() OVER (ORDER BY hire_date) AS "累积占比",
NTILE(100) OVER (ORDER BY hire_date) AS "相对位置"
FROM employees;
姓名 |入职日期 |累积占比 |相对位置|
-----------------|----------|--------------------|-------|
Lex,De Haan |2001-01-13|0.009345794392523364| 1|
Hermann,Baer |2002-06-07| 0.04672897196261682| 1|
Shelley,Higgins |2002-06-07| 0.04672897196261682| 2|
William,Gietz |2002-06-07| 0.04672897196261682| 2|
Susan,Mavris |2002-06-07| 0.04672897196261682| 3|
Daniel,Faviet |2002-08-16|0.056074766355140186| 3|
...其中,CUME_DIST 函数显示 2001-01-13 以及之前入职的员工大概有 0.9%(1/107);NTILE(100) 函数表明前 1% 入职的员工有“Lex,De Haan”和“Hermann,Baer”,由于员工总数为 107,所以不是完全准确。
取值窗口函数
取值窗口函数用于返回指定位置上的数据。常见的取值窗口函数包括:
- FIRST_VALUE ,返回窗口内第一行的数据。
- LAST_VALUE ,返回窗口内最后一行的数据。
- NTH_VALUE ,返回窗口内第 N 行的数据。
- LAG ,返回分区中当前行之前的第 N 行的数据。
- LEAD ,返回分区中当前行之后第 N 行的数据。
其中,LAG 和 LEAD 函数不支持动态的窗口大小(frame_clause),而是以当前分区作为分析的窗口。
以下语句使用 FIRST_VALUE、LAST_VALUE 以及 NTH 函数分别获取每个部门内部月薪最高、月薪最低以及月薪第三高的员工:
SELECT department_id, first_name, last_name, salary,
FIRST_VALUE(salary) OVER w,
LAST_VALUE(salary) OVER w,
NTH_VALUE(salary, 3) OVER w
FROM employees
WINDOW w AS (PARTITION BY department_id ORDER BY salary desc ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
ORDER BY department_id, salary DESC;
department_id|first_name |last_name |salary |first_value|last_value|nth_value|
-------------|-----------|-----------|--------|-----------|----------|---------|
10|Jennifer |Whalen | 4400.00| 4400.00| 4400.00| |
20|Michael |Hartstein |13000.00| 13000.00| 6000.00| |
20|Pat |Fay | 6000.00| 13000.00| 6000.00| |
30|Den |Raphaely |11000.00| 11000.00| 2500.00| 2900.00|
30|Alexander |Khoo | 3100.00| 11000.00| 2500.00| 2900.00|
30|Shelli |Baida | 2900.00| 11000.00| 2500.00| 2900.00|
30|Sigal |Tobias | 2800.00| 11000.00| 2500.00| 2900.00|
30|Guy |Himuro | 2600.00| 11000.00| 2500.00| 2900.00|
30|Karen |Colmenares | 2500.00| 11000.00| 2500.00| 2900.00|
...
以上三个函数的默认窗口是从当前分区的第一行到当前行,所以我们在
OVER
子句中将窗口设置为整个分区。
LAG 和 LEAD 函数同样用于计算销量数据的环比/同比增长。例如,以下语句统计不同产品每个月的环比增长率:
WITH sales_monthly AS (
SELECT product, to_char(saledate,'YYYYMM') ym, sum(amount) sum_amount
FROM sales_data
GROUP BY product, to_char(saledate,'YYYYMM')
SELECT product AS "产品", ym "年月", sum_amount "销量",
(sum_amount - LAG(sum_amount, 1) OVER (PARTITION BY product ORDER BY ym))/
LAG(sum_amount, 1) OVER (PARTITION BY product ORDER BY ym) * 100 AS "环比增长率(%)"
FROM sales_monthly
ORDER BY product, ym;
产品|年月 |销量 |环比增长率(%) |
----|------|---------|-----------------------|
桔子|201901|126083.00| |