


yolo检测算法系列介绍与yolo v3代码阅读(一)
首先给出论文和阅读的代码的链接:
- 论文链接: yolo v1 , yolo v2 , yolo v3
- 作者的个人主页: darknet
- 阅读的代码链接: https:// github.com/BobLiu20/YOL Ov3_PyTorch
作者风格非常清奇,从他的个人简历就可以看出,他的简历是这样的:


真人长这样:


特别是yolo v3的论文写作风格,彻底放飞自我:我随便写的,你们也就随便看看吧,反正我的效果好你肯定要引用我,还顺带嘲讽了一波retinanet。
一.yolo系列论文的阅读:
1.yolo v1:
1.1.算法的优缺点:
yolo v1 是 one stage detection的开山之作,作者在abstract中就说与two stage方法不同,yolo将object detection 看作一个end-to-end的regression问题,所以在速度上得到了很大的提升。
除了速度快之外,yolo还有一个优点就是利用图片的全局信息做预测,在training和testing的时候隐式的encode了上下文的信息,所以与faster-rcnn一类先提取roi在做分类的算法相比,yolo的背景错误率(false detection,将一个背景错分成object)更低。
最后,作者还做了一些迁移的实验,认为yolo有更好的泛化性能。在自然图像上training的yolo模型在艺术画图片上做testing的效果比其他的detection算法更好。
当然,作者也承认了yolo v1在精度上与two stage的算法还有差异,但是速度的大幅提升确实使得one stage的detection算法会有更广阔的实际应用空间。另外,one stage的算法发展也非常快,ssd,retinanet,yolo v2, yolo v3...个人也非常看好这一类的算法。
1.2.算法的概述:
1.2.1. 统一的检测方法:
之前也说过,与传统的two stage的算法先提取rois不同,yolo采用的是利用图片的全局信息进行bbox的回归与预测,整个过程是end-to-end的,速度很快。
整个的过程也就是先利用多层卷积网络提取image的global information,最后用全连接层来做预测和回归,接下来看一下全连接层的设计。
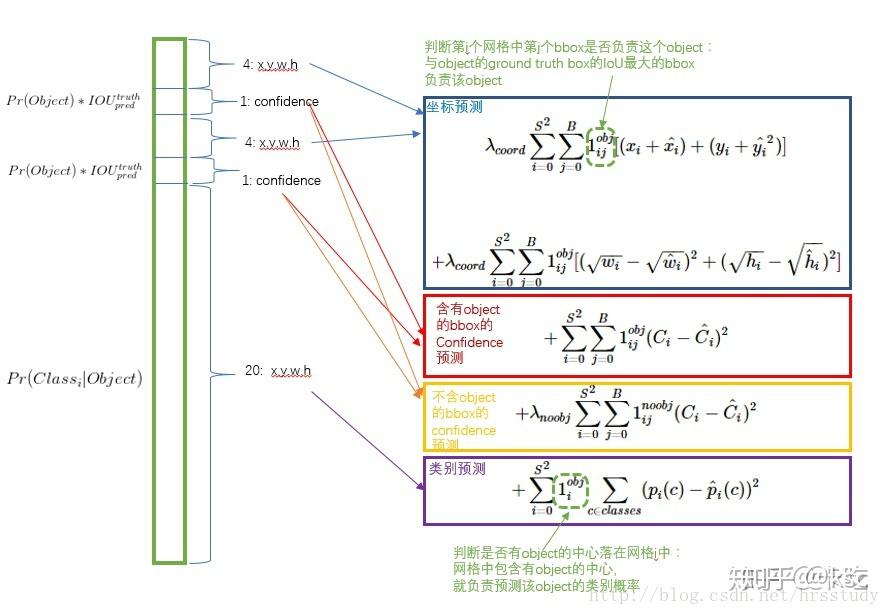
yolo v1将输入的图片分成了SxS的grid(如下图最下面的图所示),如果一个物体的中心落在了一个grid中,这个grid就要负责将这个物体检测出来。
每一个grid可以预测B个bbox,每个bbox负责预测5个值:(x,y,w,h,confidence)。其中x,y分别表示预测的bbox的中心坐标,w,h表示的是相对于整个image来说bbox的宽和高。confidence表示的是一个bbox是否包含物体的置信度。它的形式化定义如下:

前面的值表示如果一个grid中没有物体,那么这个值为0,否则为1。后面的IOU表示的是pred bbox与实际的ground truth的IOU值。它们的乘积表示的就是一个bbox是否包含物体的置信度。
yolo v1没有做基于bbox的类别预测,只是针对每一个grid可以预测一个类别:

将这个与前面的confidence乘起来:

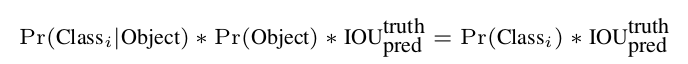
可以得到基于class的confidence。
如下图描述文字,一张图片有SxS个grid,每个grid预测B个bbox,每个bbox预测5个值,每个grid还负责预测C个类别,所以最后全连接的参数就是SxSx(B5+C)。论文在voc 07的试验中选取的S=7,B=2,C=20,所以最终的预测是7x7x(2x5+20)的tensor。

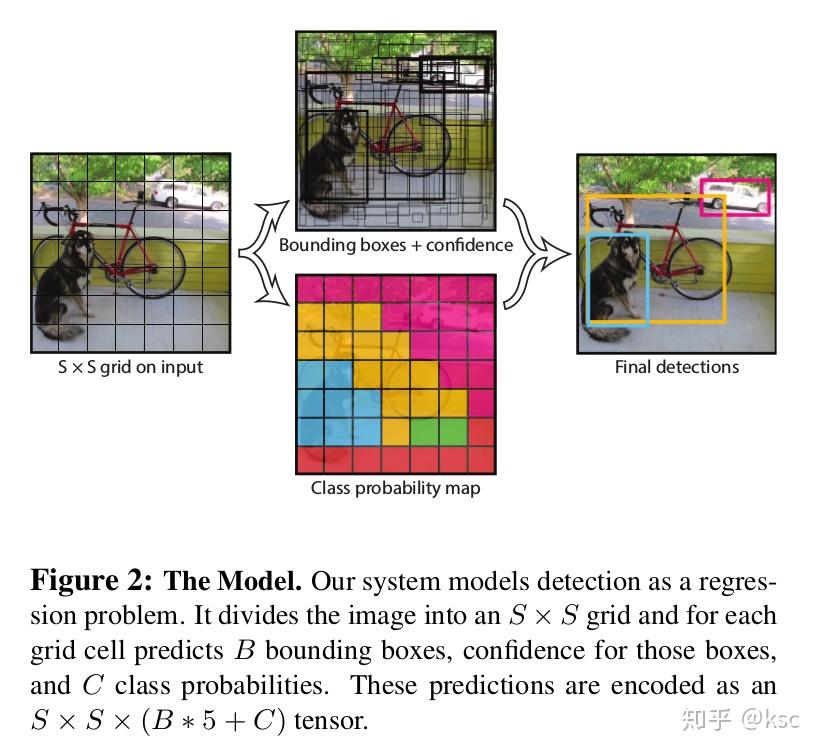
1.2.2. 网络结构设计:
yolo v1的网络结构如下图所示,前面是一些卷积层用来提取特征,后面的全连接层用来对bbox做预测和回归。其实立刻可以发现的改进就是全连接的参数过多,完全可以用卷积来替代,网络可以设计成全卷积的形式,节省参数,提升速度,后面v2和v3版本也确实改进了这一点。
作者在论文中表示yolo v1的网络设计借鉴了GoogLeNet,使用了1x1卷积后面接3x3卷积的形式,这样做可以节约参数。网络的输入图片先resize成448x448,最后的输出也和前面提到的相同,是7x7x30的tensor。

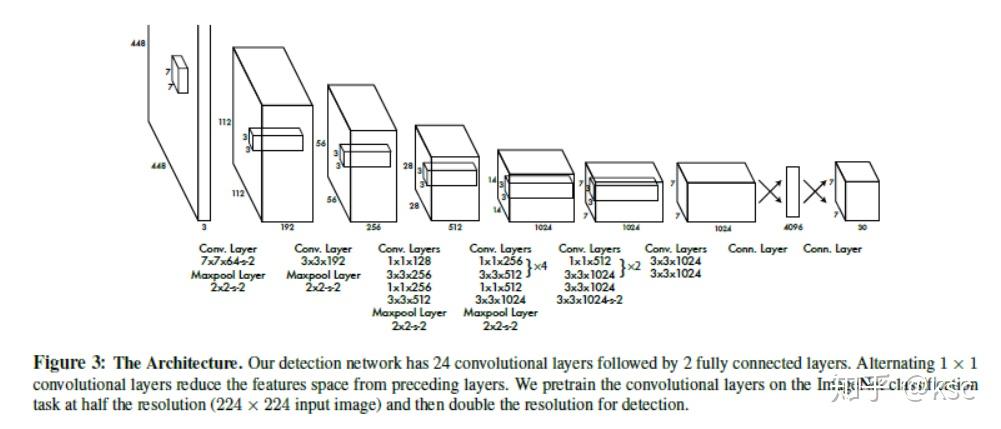
1.2.3. 训练过程:
首先,利用imagenet的分类任务的数据预训练卷积层。然后开始detection的训练,图片的输入resize成448x448,bbox的width和height都进行了normalize,这样这两个值就在0-1之间。bbox的x,y也表示成相对于所在grid的左上角的偏移,这样x,y的预测也在0-1之间。
在最后一层,使用的激活函数是leakly relu,形式如下:

接下来介绍一下loss函数,先给出论文中的图:

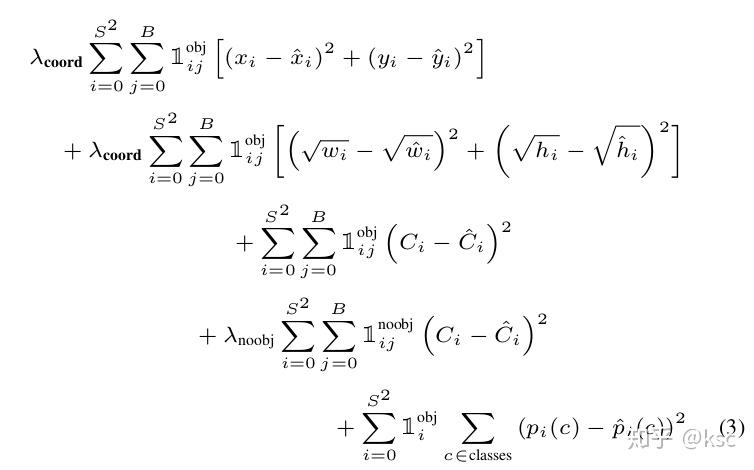
论文中表示使用的是sum-squared-error,但是直接同等对待bbox的定位error和分类error不合理,很多的grid实际上并没有包含物体。所以要增大coordinate的loss,减小没有包含物体的class confidence的loss,所以这里设置两个超参:
和
。
另外,作者还认为sum-square-error同等的看到大的bbox和小的bbox也是不合理的。为了缓和这样的情况,作者对w和h都取了根号。
表示grid
中是否有物体,
表示grid 的第 个bbox是否对这个预测负责(只选取和ground truth IOU最大的)。
这里借鉴一下另外一个博客对loss的解析图:

1.2.4. yolo的瓶颈:
除了最前面提到的一些缺点,yolo v1的每个grid只会预测2个bbox和一个类别,而有的grid中可能会包含多个小物体,所以yolo v1对于小物体的检测效果不是很好。
2.yolo v2:
yolo v2的题目非常霸气: 《YOLO9000:Better,Faster,Stronger》 。作者对yolo v1做了很多的改进得到yolo v2,然后利用wordtree,将检测和分类问题做成了一个统一的框架,并且提出了一种层次性联合训练方法,将ImageNet分类数据集和COCO检测数据集同时对模型训练,这就是标题中的yolo9000。
前面提到yolo v1的缺点在于bbox的定位不准,精度低,对于小物体的检测效果不好,所以yolo v2吸收了其他很多算法来解决这些问题。
2.1.Better
2.1.1.移除Dropout,加入了Batch Normalization,提升了2%的mAP;
2.1.2.使用了更高分辨率的分类器,原来的yolo v1在detection时的输入是448x448,但是在预训练backbone的分类任务时使用的图片是224x224的分辨率;yolo v2在训练backbone的分类任务中就使用了448x448的分辨率。这一点大约提升了4%的mAP。
2.1.3.学习faster rcnn一类的算法,引入了anchor。yolo v2中anchor的设计如下图所示,在detection任务中使用了416x416的分辨率,这是为了保证在多次卷积后,下采样strid32,得到13x13的feature map,feature map的每个点上使用9种anchor,使用了anchor之后,与之前不同的一点就是yolo v1每个grid只预测一个类别,而yolo v2需要为每个anchor box都预测一个类别,13x13x9=1521个,更多的anchor有助于小物体的检测。同时,为了获得合理的anchor box的宽和高,作者在training dataset上使用KMeans进行聚类,选择了更好的anchor宽和高的初始值。

2.1.4.作者也丢弃了之前在yolo v1中使用全连接来进行预测,因为全连接层参数较多,也会丢失一些空间信息,采用卷积网络来替换,这样yolo v2是一个全卷积的网络结构。
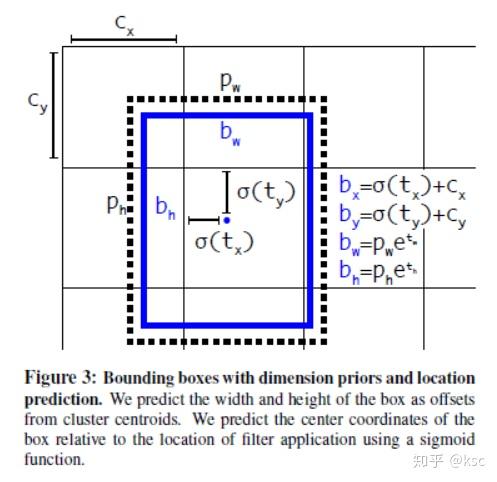
2.1.5.使用直接的定位预测。作者发现使用了anchor之后,在训练的初期阶段,对于bbox的(x,y)的预测不是很稳定。在RPN一类的网络中网络的预测是
和
,x和y表示的是左上角的坐标,计算方式如下:

在Faster R-CNN的预测中,
是没有限制的,因此收敛会比较慢。作者想让每个模型预测目标附近的一个部分,论文对采用了和YOLOv1一样的方法,直接预测中心点,并使用Sigmoid函数将偏移量限制在0到1之间(这里的尺度是针对网格框)。计算方式如下:

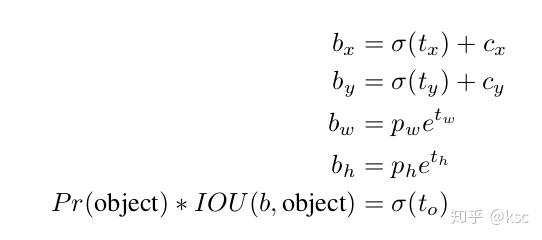
2.1.6.使用细粒度特征。yolo v1对于小物体的检测效果较差,yolo v2借鉴了Faster-RCNN
和SSD的思想,在不同层次的特征图上获取不同分辨率的特征。作者将上层的(前面26×26)高分辨率的特征图(feature map)直接连到13×13的feature map上。把26×26×512转换为13×13×2048拼接在了一起。
2.1.7.使用了多尺度的训练。作者在论文中说明,为了提升模型的鲁棒性,在训练的过程中每隔10个batches就随机的从{320,352,...,608},步长为32的集合中选择一个新的图片分辨率。
总结一下,下面论文中的这张图很好的总结了每一点改进对于yolo v2最后效果的提升:


2.3.Faster
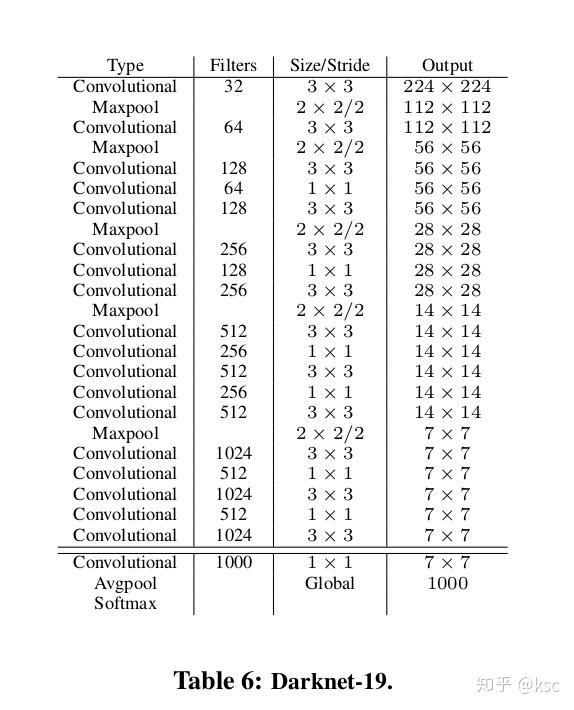
很多的detection frameworks把vgg作为backbone来提取突破特征,但是vgg的效果一般,而且参数较多,作者为yolo v2设计了一个新的backbone叫做Darknet-19(有19个卷积层)。Darknet-19在imagenet上获得了比vgg更好的top-5准确率。Darknet-19的详细结构如下图所示:

2.4.Stronger
这一部分主要讲的是如何利用wordtree联合训练分类和检测任务,使得yolo v2可以检测training data中没有出现过的类别,就不做过多介绍了。
3.yolo v3:
yolo v3是一篇行文风格非常清奇的论文,作者在这篇论文中彻底放飞自我。先看论文中的一张图:

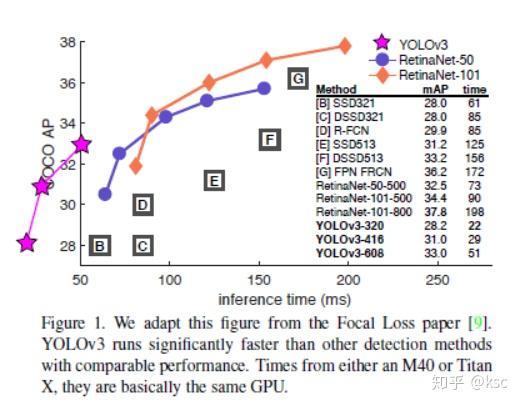
这张图最初的来源是focal loss的那篇文章,但是focal loss的作者在画这张图的时候,给出了yolo v2的坐标但是没有给出成绩,作者可能觉得自己收到了“歧视”,在yolo v3中,将自己放在了第二象限,赤裸裸的表示在座的各位都是垃圾。。。
其实yolo v3也就是把一些视觉这块最新的思想融入了yolo的框架之中,作者也在论文中表示最近都在玩推特,但是yolo v3的效果确实非常的好,接下来就看看作者在yolo v3上做了哪些改进。
3.1.bbox预测:
yolov3对每个bounding box通过逻辑回归预测一个物体的得分,如果预测的这个bounding box与真实的边框值大部分重合且比其他所有预测的要好,那么这个值就为1.如果overlap没有达到一个阈值(yolov3中这里设定的阈值是0.5),那么这个预测的bounding box将会被忽略,也就是会显示成没有损失值。
3.2.多标签分类:
在yolo v2中对于每个bbox的类别预测使用的是softmax,但在yolo v3中使用了sigmoid,主要是为了应对多标签分类的问题。
3.3.多尺度预测:
这里借鉴了SSD和FPN的思想,提取多个feature map并且利用低层的高分辨率信息和高层的语义信心融合后进行预测。
3.4.新的back-bone网络:
新设计了一个网络Darknet53,该网络学习了resnet的residual block,并且采用了SSD的思想输出多个feature map,规模也比yolo v2的Darknet13大。

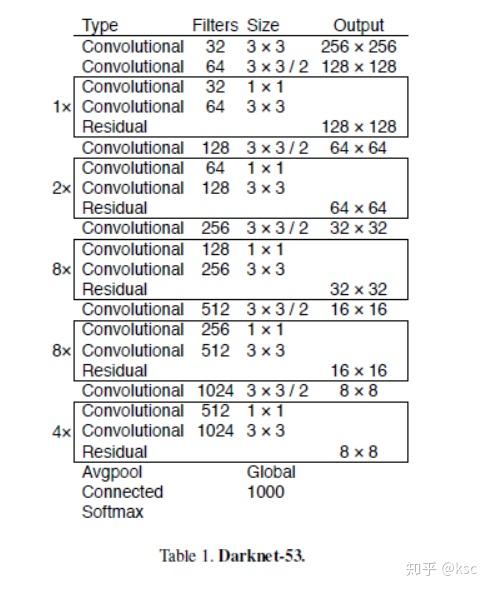
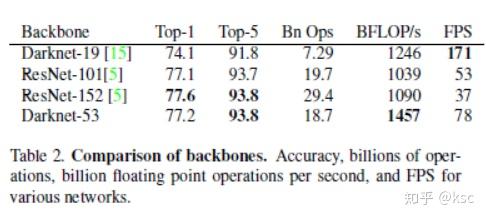
下面这个表格展示了Darknet53作为backbone的优越性:

以上就是对yolo系列三篇文章的总结。
yolo v3的代码在下一篇中。