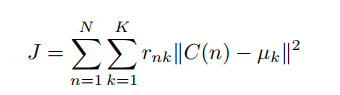import cv2
import numpy as np
from skimage import io
from sklearn.cluster import KMeans
第二步,因为要用到fit(X[, y, sample_weight])来计算k-means聚类,所以读取图片后需要转换数据维度:
img=cv2.imread(r"C:\Users\Administrator\Desktop\color restoration\cao2.jpg")
# 转换数据维度
img1 = img.reshape((img.shape[0] * img.shape[1], img.shape[2]))
读取的图片如下所示,我们要提取的就是该图片中的主色。

第三步,K-means聚类
#聚类个数
k = 3
#构造聚类器
estimator = KMeans(n_clusters=k, max_iter=4000, init='k-means++', n_init=50)
estimator.fit(img1)
#获取聚类中心
centroids = estimator.cluster_centers_
其中的聚类个数和其他参数都可以根据实际情况进行调整。
第四步,主色可视化
# 使用算法跑出的中心点,生成一个矩阵,为数据可视化做准备
result = []
result_width = 200
result_height_per_center = 80
# 获取图片色彩层数
n_channels = img1.shape[1]
for center_index in range(k):
result.append(np.full((result_width * result_height_per_center, n_channels), centroids[center_index], dtype=int))
result = np.array(result)
result = result.reshape((result_height_per_center * k, result_width, n_channels))
result=result.astype(np.uint8)
cv2.imshow('maincolor',result)
# 保存图片
io.imsave(r'C:\Users\Administrator\Desktop\color restoration\color\maincolor.jpg', result)
将提取的3个主色分别显示在80*200的长方形中,并将图片保存下来。最后提取的图片主色如下图:

https://blog.csdn.net/github_39261590/article/details/76910689
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#examples-using-sklearn-cluster-kmeans
基于python+opencv的彩色图片主色提取——利用Kmeans聚类算法一、Kmeans聚类算法1.Kmeans算法原理2. Kmeans聚类算法流程3.sklearn库中Kmeans函数详解一、Kmeans聚类算法常用的背景主色提取方法有两种: 颜色直方图法和聚类分析法. 一般来说, 背景图像中包含巨大的颜色数目,且各颜色分量之间无显著相关性,通过颜色直方图很难快速而准确地提取背景主色. 而采用基于模糊理论的聚类分析, 利用颜色空间本身是建立在人对颜色的主观感觉基础之上, 且颜色归属的模糊性已经
该程序利用OpenCV中的K均值聚类函数Kmeans2对图像进行颜色聚类,达到分割的目的。
编写此函数的目的是:Kmeans2函数的用法有些难掌握,参考资料少,尤其是对图像进行操作的例子少,我找了很久也找不到,
找到的例子也运行不了,今天终于自己搞定了,想给大家分享一下,供大家参考,节省大家利用Kmeans2进行图像方面开发的时间
,少走一些弯路。
本例子对印章图像sample.bmp进行颜色聚类
运行此程序一定要配置好OpenCv环境啊!!!
文章目录提取主色1. RGB Or HSV2. KMeans 自适应3. 整体过程及代码4. 结果后续
提取主色
最近有个小任务,需要提取图片中的主色块。最基本的做法就是聚类找主色,但是目前需要自适应提取,也就是说需要对于不同的图片提取出不同的主色块数量。
1. RGB Or HSV
貌似大多数提取主色都是建立在RGB色彩空间中,但是就人眼感知而言对红色不太敏感而对蓝色较为敏感;而且,RGB色彩空间是利用三个颜色分量的线性组合来表示颜色相关性很高,所以RGB是一种不均匀的颜色空间。
再来看看HSV,对于单
如何使用OpenCV,Python和k-means聚类算法来查找图像中最主要的颜色
该任务可用于分析一张优秀摄影作品的色彩分布,并建立色卡图,将其用于本地调色。
K-Means聚类,那么k-means究竟是什么意思呢?
K-means是一种聚类算法。目标是将n个数据点分成k个簇。 n个数据点中的每一个都将被分配给具有最接近平均值的簇。每个簇的平均值称为“质心”或“中心”。
总的来说,应...
import numpy as np
from scipy.cluster.vq import vq, kmeans, whiten
import matplotlib.pyplot as plt
fe = np.array([[1.9,2.0],
[1.7,2.5],
[1.6,3.1],
[0.1,0.1],
图像主色(dominant color)的提取方法有很多种,这里写的主要是量化的方法
直接描述颜色特征。维度将非常多,尤其是真彩色。因此,直接描述颜色特征。维度将非常多,尤其是真彩色。因此,
需要将HSV 空间量化来减少计算量。一种非等间隔的HSV 空
间量化算法显示如下:
%图像主色提取-量化
OrImage=imread('7.bmp');
hsv_image=rgb2hsv(Or
1 图像分割
1、图像分割:利用图像的灰度、颜色、纹理、形状等特征,把图像分成若干个互不重叠的区域,并使这些特征在同一区域内呈现相似性,在不同的区域之间存在明显的差异性。然后就可以将分割的图像中具有独特性质的区域提取出来用于不同的研究。
2、图像分割技术已在实际生活中得到广泛的应用。例如:在机车检验领域,可以应用到轮毂裂纹图像的分割,及时发现裂纹,保证行车安全;在生物医学工程方面,对肝脏CT图像进行分割,为临床治疗和病理学研究提供帮助。
2 图像分割常用方法
1.阈值分割:对图像灰度值进行度量,设置不同类别
颜色是一张图像最具代表性的特征,那么如何去对一张图像进行主颜色提取呢?这是今天所要解决的问题。
通过查阅相关资料发现,最常使用的主颜色提取方法是利用Kmeans聚类的方法进行颜色提取。
颜色提取方法流程: