官网建议: 设置为当前spark job的总core数量的2~3倍. 理由如下:
背景: spark作业是 1 core 1 task的
假设我们给当前Spark job 设置总Core数为 100, 那么依据1 core 1 task, 当前spark集群中最多并行运行100task任务, 那么通过设置上述两个参数为100, 使得我们结果RDD的分区数为100, 一个分区 1task 1core, 完美! 但是实际生产中会有这样的情况, 100个task中有些task的处理速度快, 有些处理慢, 假设有20个task很快就处理完毕了, 此时就会出现 我们集群中有20个core处理闲置状态, 不符合spark官网所说的最大化压榨集群能力.
而如果我们设置上述参数值为199, 此时的现象: 虽然集群能并行处理199个task, 奈何总core只有100, 所以会出现有99个task处于等待处理的情况. 处理较快的那20task闲置下来的20个core就可以接着运行99个中的20个task, 这样就最大化spark集群的计算能力
谈谈spark.sql.shuffle.partitions和 spark.default.parallelism 的区别及spark并行度的理解spark.sql.shuffle.partitions和 spark.default.parallelism 的区别spark并行度的理解如何设置spark.sql.shuffle.partitions和spark.default.parallelism的值spark.sql.shuffle.partitions和 spark.default.parallel
1.
spark
.
default
.
parallelism
只对RDD有效,对
spark
sql
(DataFrame、DataSet)无效
2.
spark
.
sql
.
shuffle
.
partition
s对
spark
sql
中的joins和aggregations有效,但其他的无效(对这种情况下,上述的两种配置都无效,我们应该怎么办呢?看第三点)
3.我们可以使用re
partition
算子对dataframe进行重分区。
在关于
spark
任务
并行度
的设置中,有两个参数我们会经常遇到,
spark
.
sql
.
shuffle
.
partition
s 和
spark
.
default
.
parallelism
, 那么这两个参数到底有什么
区别
的?
首先,让我们来看下它们的定义
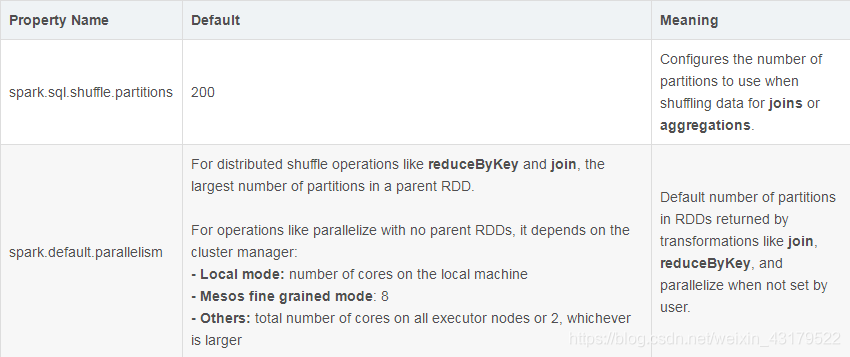
Property Name
Default
Meaning
spark
.
sql
.
shuffle
.
partition
s...
当不跟随父对象
partition
数目的
shuffle
过程发生后,结果的
partition
会发生改变,这两个参数就是控制这类
shuffle
过程后,返回对象的
partition
的
经过实测,得到结论:
spark
.
sql
.
shuffle
.
partition
s 作用于dataframe(val df2=df1.
shuffle
算子(如df1.orderBy()),的df2的
partition
就是这个参...
spark
.reducer.maxSizeInFlight 48m reduce task的buffer缓冲,代表了每个reduce task每次能够拉取的map side数据最大大小,如果内存充足,可以考虑加大,从而减少网络传输次数,提升性能
spark
.
shuffle
.blockTransferService netty
shuffle
过程中,传输数据的方式,两种选项,netty或nio,
spark
1.2开始,默认就是netty,比较简单而且性能较高,
spark
1.5开始nio就是过期的了,而且
spark
1.6中会去除掉
spark
.
shuffle
.compress true 是否对map side输出的文件进行压缩,默认是启用压缩的,压缩器是由
spark
.io.compression.codec属性指定的,默认是snappy压缩器,该压缩器强调的是压缩速度,而不是压缩率
Hive是大数据领域常用的组件之一,主要是大数据离线数仓的运算,关于Hive的性能调优在日常工作和面试中是经常涉及的的一个点,因此掌握一些Hive调优是必不可少的一项技能。影响Hive效率的主要有数据倾斜、数据冗余、job的IO以及不同底层引擎配置情况和Hive本身参数和Hive
SQL
的执行等因素。本文主要结合实际业务情况,在使用
Spark
作为底层引擎时,通过一些常见的配置参数对报错任务进行调整优化。
下面从两个方面对复杂任务的优化:
Spark
资源参数优化
主要针对
Spark
运行过程中各个使用资源的地方,
六、
Spark
Shuffle
的配置选项(配置调优)
一、
spark
的
shuffle
调优
主要是调整缓冲的大小,拉取次数重试重试次数与等待时间,内存比例分配,是否进行排序操作等等
二、
spark
.
shuffle
.file.buffer
参数说明:该参数用于设置
shuffle
write task的BufferedOutputStream的buffer缓冲大小(默认是32K)。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
调优建议:如果作业可用的内存资源较为充
Focusing on a very active area of mathematical research in the last decade, Combinatorics of Set
Partition
s presents methods used in the combinatorics of pattern avoidance and pattern enumeration in set
partition
s. Designed for students and researchers in discrete mathematics, the book is a one-stop reference on the results and research activities of set
partition
s from 1500 A.D. to today.
Each chapter gives historical perspectives and contrasts different approaches, including generating functions, kernel method, block decomposition method, generating tree, and Wilf equivalences. Methods and definitions are illustrated with worked examples and Maple™ code. End-of-chapter problems often draw on data from published papers and the author’s extensive research in this field. The text also explores research directions that extend the results discussed. C++ programs and output tables are listed in the appendices and available for download on the author’s web page.
针对万亿级别的
shuffle
量,
Spark
SQL
调优需要考虑以下几个方面:
1. 调整
并行度
:可以通过调整
并行度
来提高任务的执行效率。可以通过设置
spark
.
sql
.
shuffle
.
partition
s 参数来控制
shuffle
的
并行度
,建议将其设置为节点数的 2-3 倍。
2. 使用合适的存储格式:选择合适的存储格式可以减少
shuffle
的数据量。例如,使用 Parquet 或 ORC 格式可以减少数据的存储空间,从而减少
shuffle
的数据量。
3. 使用合适的数据分区策略:合理的数据分区策略可以减少
shuffle
的数据量。可以根据数据的特点选择合适的分区策略,例如,按照时间、地理位置等进行分区。
4. 使用合适的缓存策略:合理的缓存策略可以减少
shuffle
的数据量。可以将经常使用的数据缓存到内存中,从而减少
shuffle
的数据量。
5. 使用合适的硬件配置:合适的硬件配置可以提高任务的执行效率。可以选择高性能的 CPU、内存和存储设备,从而提高任务的执行效率。
总之,针对万亿级别的
shuffle
量,需要综合考虑多个方面进行调优,以提高任务的执行效率。