


模型剪枝. Network Slimming算法解读

1. 算法解读
1.1 框架
- 论文和源码: Learning Efficient Convolutional Networks through Network Slimming
- 卷积后能得到多个特征图, 但是有些特征图的权重都接近0了,没有起到什么作用
- 那么训练的时候能否加入一些策略,让权重参数出现主次之分?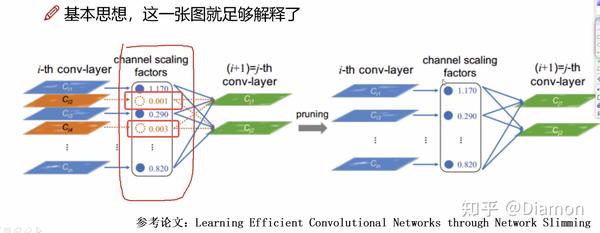
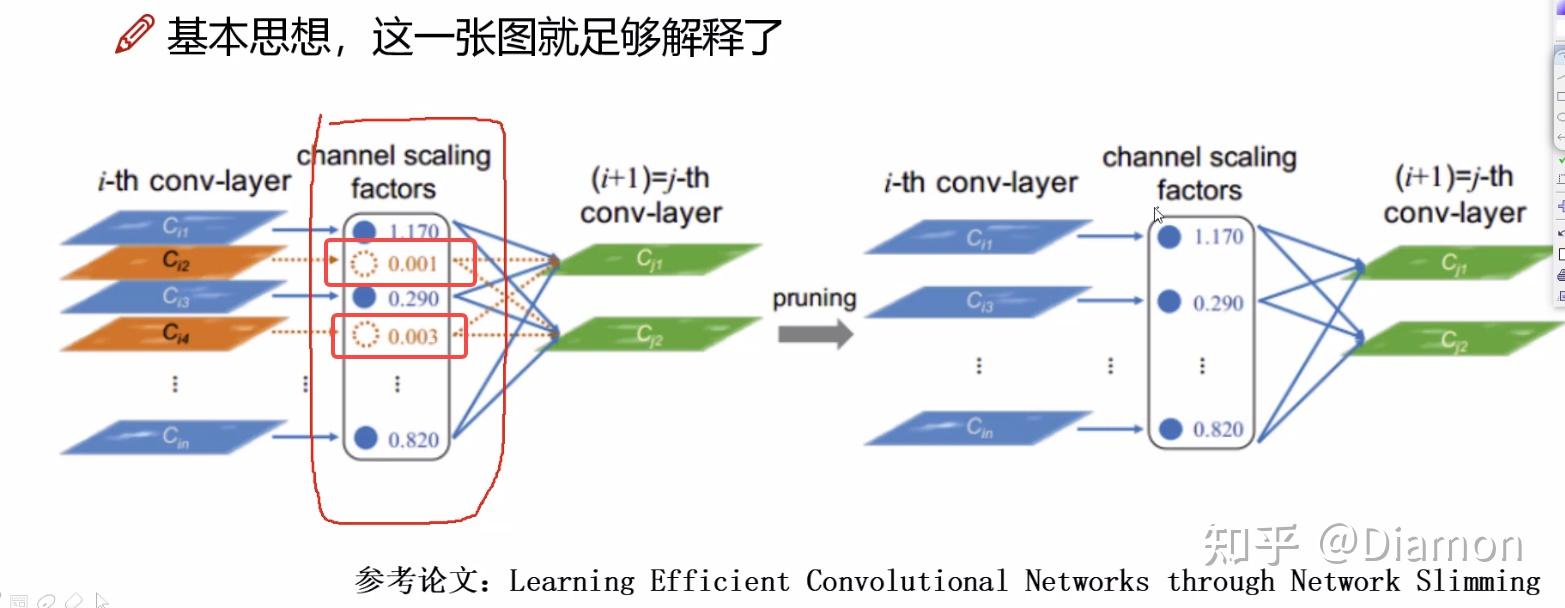
如何得到每特征图的重要性呢?
- NetWork sliming, 就是利用BN层中缩放因子 \gamma
- BN的公式, 即减去均值,除方差
x^{k} = \frac{x^{(k)} - E[x^{(k)} ]}{\sqrt{Var[x^{(k)} ]}}
- 除了常规的归一化操作, 由于归一化后, 数值分布被局限在了非线性函数的线性区域中, BN中额外引入了两个可训练的参数: \gamma \beta
1.2 回顾 BatchNorm
BatchNorm的意义
如果训练的时候,输入数据经过不同卷积层输后, 对于卷积层来说, 它后面几层的卷积层的输入都是前面经过非线性变换后的输出
如果输入的总是改变,比如一会分布在左下方,一会分布在右上方, 这样网络模型学起来是很困难的
- 在sigmoid激活函数的边缘, 梯度的变化是不明显的, 而且这个区域容易出现梯度消失
- 在sigmoid中间地带, 梯度变化非常快, 非常明显
-- 如果对每层的学习结果不加以限制可能会出现问题
-- 以sigmoid为例, 很多输出值越来越偏离,导致模型收敛越来越难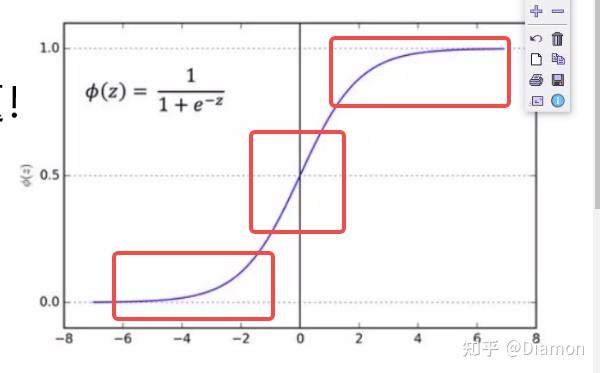
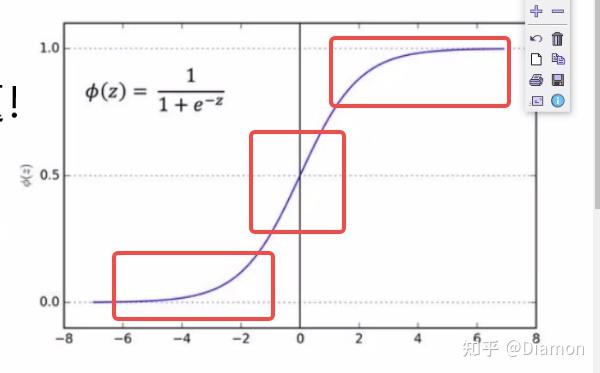
BN要做的就是把越来越偏离的分布给拉回来, 再重新规范化到均值为0方差为1的标准正态分布, 这样能够使得激活函数在数值层面更敏感,训练更快
但是, 经过BN后,把数值分布强制在了非线性函数的线性区域中, 这样也会出现问题:
如果都是线性了,那么神经网络就没有意义了
-- 比如多个串联的卷积层
1. Cov1 = w1*x1
2. cnv2 = Cov1*w2 = w1 * w2 * x1
-- 这样一来多层卷积就没有意义了, 直接拿一个w3 = w1 * w2, 一样的效果额外的训练参数
所以, BN另一方面还需要保证一些非线性,对规范化后的结果再进行变换, 为了补偿BN损失了非线性,现在引入了两个参数,去增加非线性, 这两个参数是训练得到的
y^{(k)} = \gamma^{(k)} x^{(k)} + \beta^{(k)}
1.3 稀疏化原理
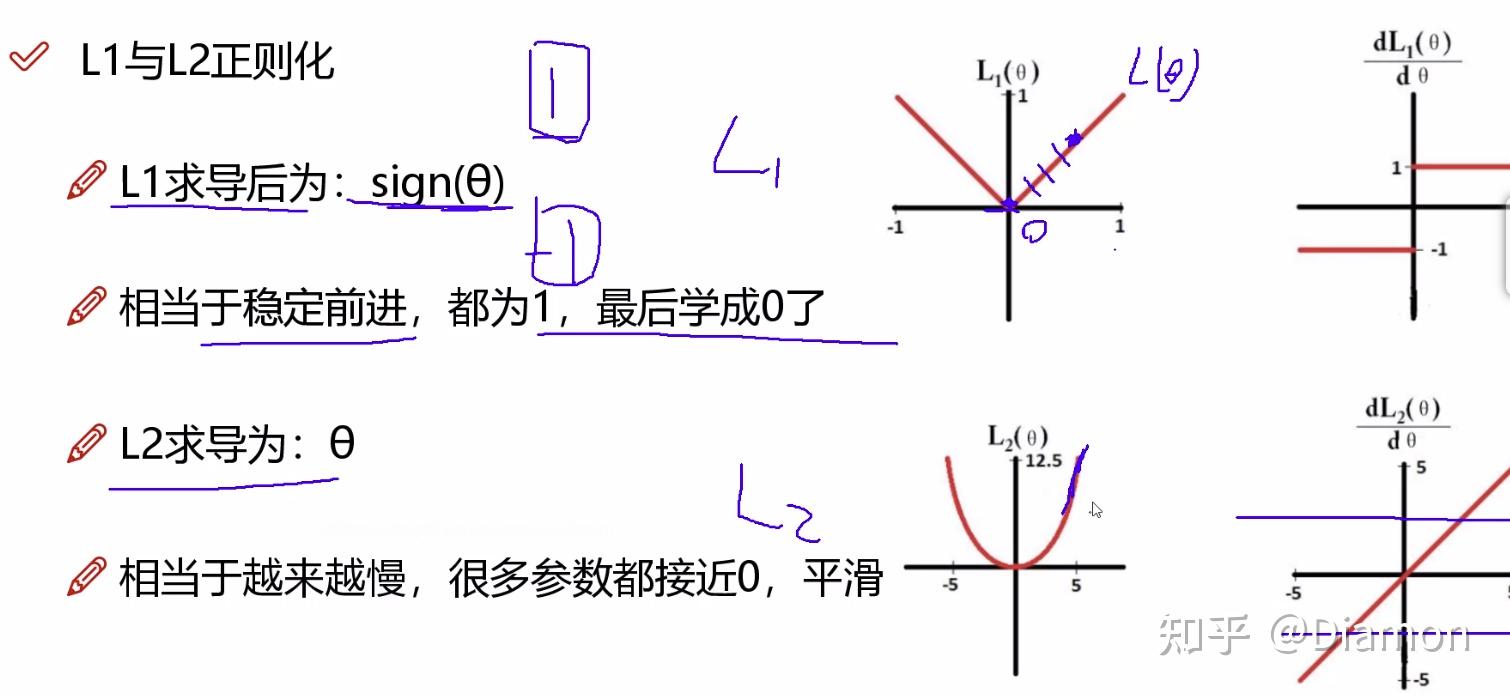
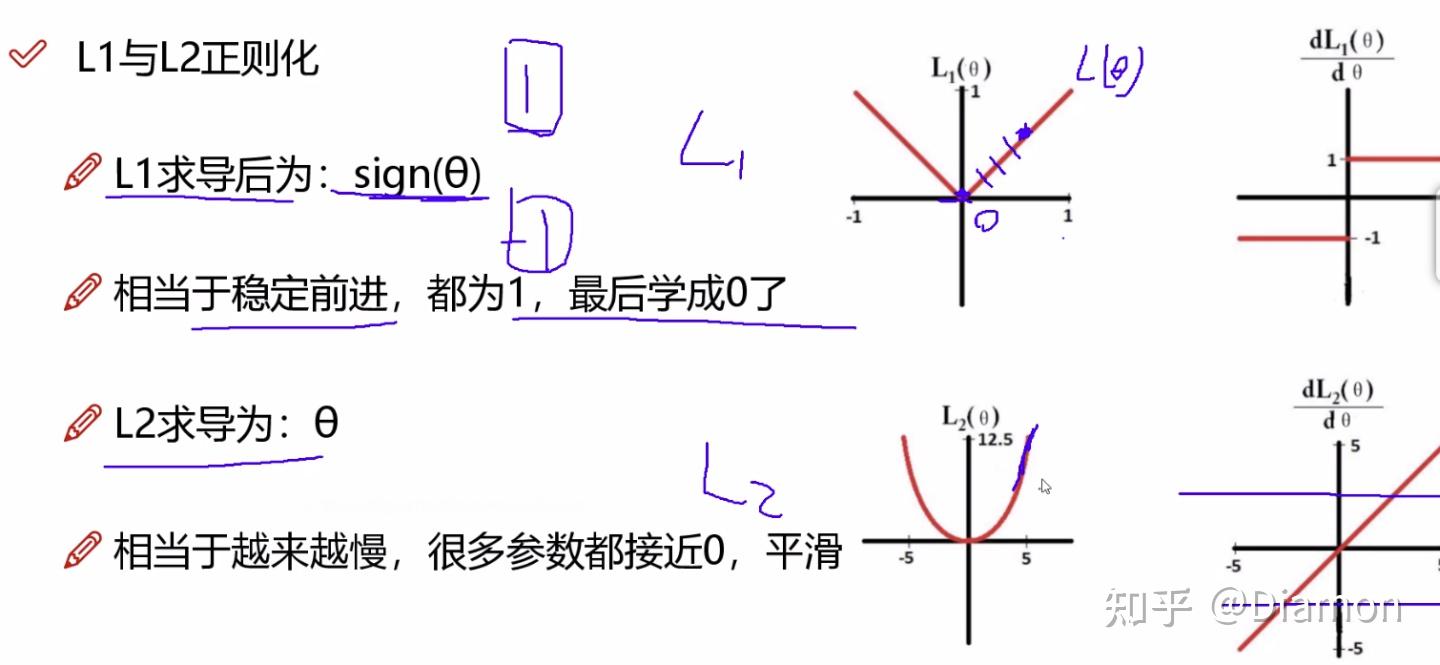
L1 L2正则化
论文中提出:训练时使用L1正则化能对参数进行稀疏作用
用较少的基本信号的线性组合来表达大部分或者全部的原始信号
简单理解稀疏化: 就是用- L1 正则化能够做稀疏表示 和 特征选择, 其公式(loss + 权重), 有些权重会被稀疏的比较小
相当于给权重又加上了一层权重, 权重的权重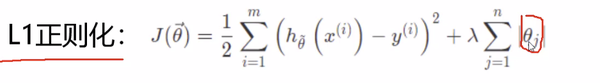
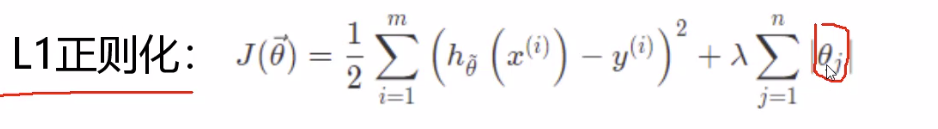
- L2 正则化平滑特征
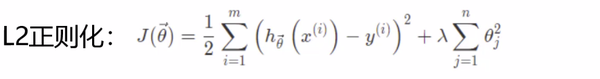
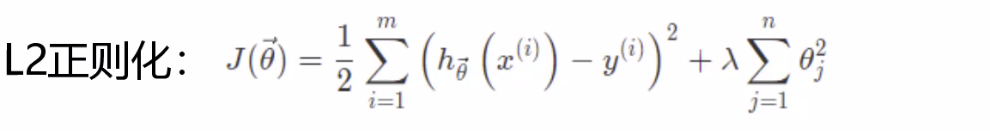
- 为什么L1适合做稀疏, 而L2不适合呢?
-- L1的梯度是固定的,固定能学习到0, 而稀疏就需要要把一些权重的系数给学到0,一旦是0代表这个特征不重要
-- L2的梯度是越接近0越小, 很多参数只是接近0, 是平滑的感觉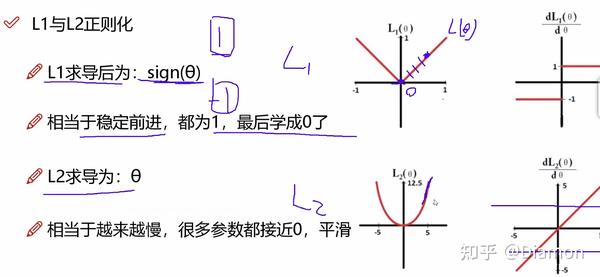
引入L1正则来控制γ, 要把稀疏表达加在γ 上, 得到每个特征的重要性 \lambda
- 每个通道的特征对应的权重是 γ
- 稀疏表达也是对 γ 来说的, 所以正则化系数 λ 也是针对 γ, 而不是 W
- 稀疏化后, 做γ 值的筛选

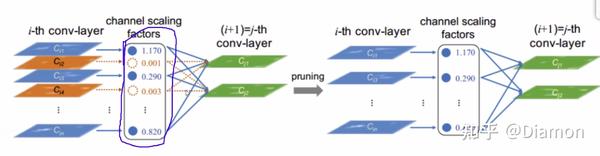
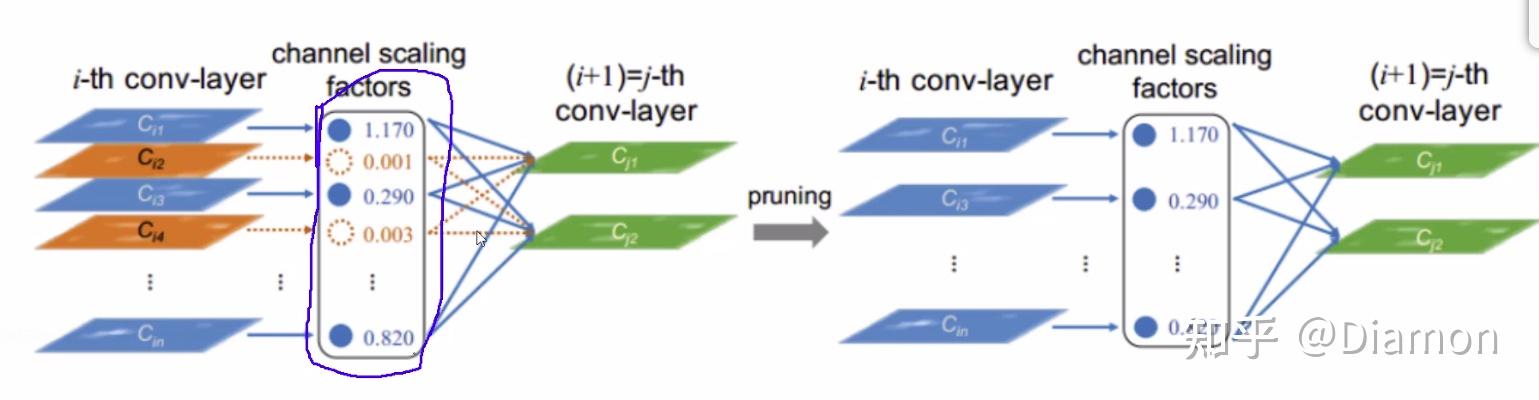
论文的核心就是 : 训练 剪枝 (去掉不重要的特征) 再训练
2. NetWork sliming代码
2.1 构建模型 vgg
- main中创建基本的VGG模型的代码
if args.refine:
checkpoint = torch.load(args.refine)
model = vgg(cfg=checkpoint['cfg'])
model.cuda()
model.load_state_dict(checkpoint['state_dict'])
else:
model = vgg()- debug 进入 vgg
class vgg(nn.Module):
def __init__(self, dataset='cifar10', init_weights=True, cfg=None):
super(vgg, self).__init__()
## 整体特征提取模块
if cfg is None:
## VGG网络结构, [卷积,卷积,pooling.....]
cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512]
self.feature = self.make_layers(cfg, True)
if dataset == 'cifar100':
num_classes = 100
elif dataset == 'cifar10':
num_classes = 10
## 最后加上全连接层
self.classifier = nn.Linear(cfg[-1], num_classes)
if init_weights:
self._initialize_weights()
def make_layers(self, cfg, batch_norm=False):
layers = []
in_channels = 3
# 解析剪枝的配置文件
for v in cfg:
if v == 'M':# 执行maxpooling
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else: # 执行卷积
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1, bias=False)
#print (in_channels,' ',v)
基本组合: 卷积+BN+Relu, 会基于BN中的参数值去判断特征图是否重要
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
# 循环继续,下一层的input 就是 这一层的输出,所以 in_channels = v
in_channels = v
return nn.Sequential(*layers)
def forward(self, x):
x = self.feature(x)
x = nn.AvgPool2d(2)(x)
x = x.view(x.size(0), -1)
y = self.classifier(x)
return y
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(0.5)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()2.2 加入L1正则化来进行更新
- 在main的训练代码中,梯度更新时, 加入正则化的BN, 需要自己指定好如何去更新
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda
:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
if args.sr:##如果加入BN
updateBN()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.1f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))- updateBN()
# additional subgradient descent on the sparsity-induced penalty term
## 加入正则化的BN, 需要自己指定好如何去更新
def updateBN():
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):#判断当前层做的是BN, 那么在更新梯度时多引入一部分
参数更新中融入了正则化
-- args.s, 即前面脚本运行输入的s, 含义即 lamda * L1, L1前面的系数
-- L1前面的系数s * 梯度
-- torch.sign(): 即前面展示的图, L1 大于0为1 小于0为-1 0还是0
m.weight.grad.data.add_(args.s*torch.sign(m.weight.data)) # L1 大于0为1 小于0为-1 0还是0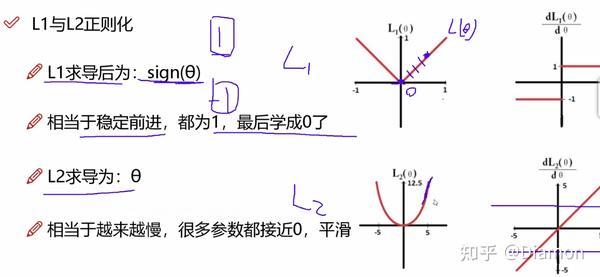
2.3 训练main
- 先训练,并且加入l1正则化 ,得到一个用于剪枝的模型
-sr --s 0.0001- 完整代码
train_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('./data', train=True, download=True,
transform=transforms.Compose([
transforms.Pad(4),
transforms.RandomCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
batch_size=args.test_batch_size, shuffle=True, **kwargs)
### 构建模型
if args.refine:
checkpoint = torch.load(args.refine)
model = vgg(cfg=checkpoint['cfg'])
model.cuda()
model.load_state_dict(checkpoint['state_dict'])
else:
model = vgg()
if args.cuda:
model.cuda()
### 指定优化器
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
print("=> loaded checkpoint '{}' (epoch {}) Prec1: {:f}"
.format(args.resume, checkpoint['epoch'], best_prec1))
else:
print("=> no checkpoint found at '{}'".format(args.resume))
# additional subgradient descent on the sparsity-induced penalty term
## 加入正则化的BN, 需要自己指定好如何去更新
def updateBN():
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):#判断当前层做的是BN, 那么在更新梯度时多引入一部分
参数更新中融入了正则化
-- args.s, 即前面脚本运行输入的s, 含义即 lamda * L1, L1前面的系数
-- L1前面的系数s * 梯度
-- torch.sign(): 即前面展示的图, L1 大于0为1 小于0为-1 0还是0
m.weight.grad.data.add_(args.s*torch.sign(m.weight.data)) # L1 大于0为1 小于0为-1 0还是0
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(
output, target)
loss.backward()
if args.sr:##如果加入BN
updateBN()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.1f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test():
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
test_loss += F.cross_entropy(output, target, size_average=False).item() # sum up batch loss
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.1f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
## 保存模型
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, 'model_best.pth.tar')
## 训练时保存checkpoint
best_prec1 = 0.
for epoch in range(args.start_epoch, args.epochs):
if epoch in [args.epochs*0.5, args.epochs*0.75]:
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1
train(epoch)
prec1 = test()
is_best = prec1 > best_prec1
best_prec1 = max(prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer': optimizer.state_dict(),
}, is_best)
2.4 剪枝模块
剪枝步骤
- 整个网络有很多BN层, 很多特征图, 每个特征图在2.3带着正则化去训练时, 都会有对应的gamma系数(对特征图权重的稀疏表示)
- 统计整个网络特征图的总数, 然后用一个列表bn来保存每个特征图对应的gamma系数
bn = torch.zeros(total)
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
# 把 gammma 值都存入 bn中,按照索引存, 比如 index1:index1+size 存bn1的gamma
size = m.weight.data.shape[0]
bn[index:(index+size)] = m.weight.data.abs().clone()
index += size- 对整个列表进行排序, 按照设定的剪枝百分比对list进行截断
## 对gamma值进行排序
y, i = torch.sort(bn)
## 计算阈值
thre_index = int(total * args.percent)
## 截取到哪一个索引
thre = y[thre_index]- 再根据bn中正则化得到的gamma系数, 制作一个掩码mask([0,0,1,1,0...]), 代表每个特征图对应的权重系数W是否置0
cfg = []
cfg_mask = []
for k, m in enumerate(model.modules()):
if isinstance(m, nn.BatchNorm2d):# 如果是一个BatchNorm2d层
weight_copy = m.weight.data.clone()#把权重拷贝
#.gt 比较前者是否大于后者: 即当前的权重参数是否大于阈值
# mask里的元素是0或1的, 当前排序后gamma的索引大于阈值,返回1,小于0
mask = weight_copy.abs().gt(thre).float().cuda()
# pruned剪枝要剪去多少个, 初始值是0个
pruned = pruned + mask.shape[0] - torch.sum(mask)
# 通过和mask做乘法把实际权重值置0
m.weight.data.mul_(mask) # BN层gamma置0
m.bias.data.mul_(mask)
# cfg是一个list,比如它的第一个元素是34,即第一个卷积层保留了34个特征图
cfg.append(int(torch.sum(mask)))
cfg_mask.append(mask.clone())
print('layer index: {:d} \t total channel: {:d} \t remaining channel: {:d}'.
format(k, mask.shape[0], int(torch.sum(mask))))
elif isinstance(m, nn.MaxPool2d):
cfg.append('M')- 根据cfg_mask, 对模型中不需要的权重W置0, 然后测试, 一般剪枝后的模型效果都会比较差
# 置0后先测试下效果
def test():
kwargs = {'num_workers': 0, 'pin_memory': True} if args.cuda else {}
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5,
0.5))])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
model.eval()
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
print('\nTest set: Accuracy: {}/{} ({:.1f}%)\n'.format(
correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
test()- 根据cfg 保存剪枝后的模型, 再次进行训练(康复训练)
# 执行剪枝
print(cfg)
newmodel = vgg(cfg=cfg) # 剪枝后的模型
newmodel.cuda()
# 为剪枝后的模型赋值权重
layer_id_in_cfg = 0
start_mask = torch.ones(3) #当前block的输入(在BN层更新,当前的输出是下一个block的输入)
end_mask = cfg_mask[layer_id_in_cfg] #当前block的输出(从训练得到的配置中得到)
for [m0, m1] in zip(model.modules(), newmodel.modules()):
if isinstance(m0, nn.BatchNorm2d):
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy()))) # 赋值
m1.weight.data = m0.weight.data[idx1].clone()
m1.bias.data = m0.bias.data[idx1].clone()
m1.running_mean = m0.running_mean[idx1].clone()
m1.running_var = m0.running_var[idx1].clone()
layer_id_in_cfg += 1
start_mask = end_mask.clone() #下一层的
if layer_id_in_cfg < len(cfg_mask): # do not change in Final FC
end_mask = cfg_mask[layer_id_in_cfg] #输出
elif isinstance(m0, nn.Conv2d):
# squeeze 函数:从数组的形状中删除单维度条目,即把shape中为1的维度去掉
# 返回 Array a 中所有满足条件的索引, 类似sql中的where
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
print('In shape: {:d} Out shape:{:d}'.format(idx0.shape[0], idx1.shape[0]))
w = m0.weight.data[:, idx0, :, :].clone() #拿到原始训练好权重
w = w[idx1, :, :, :].clone() # 根据筛选出的特征图的id,拷贝需要的权重
m1.weight.data = w.clone() # 将所需权重赋值到剪枝后的模型
# m1.bias.data = m0.bias.data[idx1].clone()
elif isinstance(m0, nn.Linear):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
# m0.weight.data 是 (10,512), 即每个特征图是长度为10的一维向量,现在按照idx0的索引取出需要的模型
m1.weight.data = m0.weight.data[:, idx0].clone()
# 保存剪枝后的模型
torch.save({'cfg': cfg, 'state_dict': newmodel.state_dict()}, args.save)- 之后在再利用2.3 的main脚本进行训练
--refine pruned.pth.tar --epochs 40
## 剪枝后的模型不用再进行正则化,稀疏表达了- 总结
# 1:训练,并且加入l1正则化 -sr --s 0.0001
# 2:执行剪枝操作 --model model_best.pth.tar --save pruned.pth.tar --percent 0.7
# 3:再次进行微调操作 --refine pruned.pth.tar --epochs 40 2.4 prune完整代码
import os
import argparse
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import datasets, transforms
from vgg import vgg
import numpy as np
脚本命令 --model 用哪个模型 --save 剪枝后保存的模型名 --percent 剪枝百分比
--model model_best.pth.tar --save pruned.pth.tar --percent0.7
# Prune settings
parser = argparse.ArgumentParser(description='PyTorch Slimming CIFAR prune')
parser.add_argument('--dataset', type=str, default='cifar10',
help='training dataset (default: cifar10)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--percent', type=float, default=0.5,
help='scale sparse rate (default: 0.5)')
parser.add_argument('--model', default=
'', type=str, metavar='PATH',
help='path to raw trained model (default: none)')
parser.add_argument('--save', default='', type=str, metavar='PATH',
help='path to save prune model (default: none)')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
model = vgg()
if args.cuda:
model.cuda()
if args.model:
if os.path.isfile(args.model):
print("=> loading checkpoint '{}'".format(args.model))
checkpoint = torch.load(args.model)
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
print("=> loaded checkpoint '{}' (epoch {}) Prec1: {:f}"
.format(args.model, checkpoint['epoch'], best_prec1))
else:
print("=> no checkpoint found at '{}'".format(args.resume))
print(model)
1. 获取所有特征图的gamma值,存入一个list当中
2. 对gamma值进行排序
total = 0 # 每层特征图个数 总和(计算一下整个网络中有多少网络)
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
total += m.weight.data.shape[0]
bn = torch.zeros(total) # 拿到每一个gamma值 每个特征图都会对应一个γ、β
index = 0
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
# 把 gammma 值都存入 bn中,按照索引存, 比如 index1:index1+size 存bn1的gamma
size = m.weight.data.shape[0]
bn[index:(index+size)] = m.weight.data.abs().clone()
index += size
## 对gamma值进行排序
y, i = torch.sort(bn)
## 计算阈值
thre_index = int(total * args.percent)
## 截取到哪一个索引
thre = y[thre_index]
pruned = 0
cfg = []
cfg_mask = []
for k, m in enumerate(model.modules()):
if isinstance(m, nn.BatchNorm2d):# 如果是一个BatchNorm2d层
weight_copy = m.weight.data.clone()#把权重拷贝
#.gt 比较前者是否大于后者: 即当前的权重参数是否大于阈值
# mask里的元素是0或1的, 当前排序后gamma的索引大于阈值,返回1,小于0
mask = weight_copy.abs().gt(thre).float().cuda()
# pruned剪枝要剪去多少个, 初始值是0个
pruned = pruned + mask.shape[0] - torch.sum(mask)
# 通过和mask做乘法把实际权重值置0
m.weight.data.mul_(mask) # BN层gamma置0
m.bias.data.mul_(mask)
# cfg是一个list,比如它的第一个元素是34,即第一个卷积层保留了34个特征图
cfg.append(int(torch.sum(mask)))
cfg_mask.append(mask.clone())
print('layer index: {:d} \t total channel: {:d} \t remaining channel: {:d}'.
format(k, mask.shape[0], int(torch.sum(mask))))
elif isinstance(m, nn.MaxPool2d):
cfg.append('M')
pruned_ratio = pruned/total
print('Pre-processing Successful!')
# 置0后先测试下效果
def test():
kwargs = {'num_workers': 0, 'pin_memory': True} if args.cuda else {}
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
model.eval()
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
print('\nTest set: Accuracy: {}/{} ({:.1f}%)\n'.format(
correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
test()
### 得到的cfg 保存的就是训练过程中的剪枝信息
# 执行剪枝
print(cfg)
newmodel = vgg(cfg=cfg) # 剪枝后的模型
newmodel.cuda()
# 为剪枝后的模型赋值权重
layer_id_in_cfg = 0
start_mask = torch.ones(3) #当前block的输入(在BN层更新,当前的输出是下一个block的输入)
end_mask = cfg_mask[layer_id_in_cfg] #当前block的输出(从训练得到的配置中得到)
for [m0, m1] in zip(model.modules(), newmodel.modules()):
if isinstance(m0, nn.BatchNorm2d):
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy()))) # 赋值
m1.weight.data = m0.weight.data[idx1].clone()
m1.bias.data = m0.bias.data[idx1].clone()
m1.running_mean = m0.running_mean[idx1].clone()
m1.running_var = m0.running_var[idx1].clone()
layer_id_in_cfg += 1
start_mask = end_mask.clone() #下一层的
if layer_id_in_cfg < len(cfg_mask): # do not change in Final FC
end_mask = cfg_mask[layer_id_in_cfg] #输出
elif isinstance(m0, nn.Conv2d):
# squeeze 函数:从数组的形状中删除单维度条目,即把shape中为1的维度去掉
# 返回 Array a 中所有满足条件的索引, 类似sql中的where
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
print('In shape: {:d} Out shape:{:d}'.format(idx0.shape[0], idx1.shape[0]))
w = m0.weight.data[:, idx0, :, :].clone() #拿到原始训练好权重
w = w[idx1, :, :, :].clone() # 根据筛选出的特征图的id,拷贝需要的权重
m1.weight.data = w.clone() # 将所需权重赋值到剪枝后的模型
# m1.bias.data = m0.bias.data[idx1].clone()
elif isinstance(m0, nn.Linear):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
# m0.weight.data 是 (10,512), 即每个特征图是长度为10的一维向量,现在按照idx0的索引取出需要的模型
m1.weight.data = m0.weight.data[:, idx0].clone()
# 保存剪枝后的模型
torch.save({'cfg': cfg, 'state_dict': newmodel.state_dict()}, args.save)