


【Kaggle】模型调参利器 gridSearchCV(网格搜索)


gridSearchCV(网格搜索)的参数、方法及示例
1.简介
GridSearchCV的sklearn官方网址:
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数。但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果。这个时候就是需要动脑筋了。数据量比较大的时候可以使用一个快速调优的方法——坐标下降。它其实是一种贪心算法:拿当前对模型影响最大的参数调优,直到最优化;再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。这个方法的缺点就是可能会调到局部最优而不是全局最优,但是省时间省力,巨大的优势面前,还是试一试吧,后续可以再拿bagging再优化。
通常算法不够好,需要调试参数时必不可少。比如SVM的惩罚因子C,核函数kernel,gamma参数等,对于不同的数据使用不同的参数,结果效果可能差1-5个点,sklearn为我们提供专门调试参数的函数grid_search。
2.参数说明
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’)
(1) estimator
选择使用的分类器,并且传入除需要确定最佳的参数之外的其他参数。每一个分类器都需要一个scoring参数,或者score方法:estimator=RandomForestClassifier(min_samples_split=100,min_samples_leaf=20,max_depth=8,max_features='sqrt',random_state=10),
(2) param_grid
需要最优化的参数的取值,值为字典或者列表,例如:param_grid =param_test1,param_test1 = {'n_estimators':range(10,71,10)}。
(3) scoring=None
模型评价标准,默认None,这时需要使用score函数;或者如scoring='roc_auc',根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。具体值的选取看本篇第三节内容。
(4) fit_params=None
(5) n_jobs=1
n_jobs: 并行数,int:个数,-1:跟CPU核数一致, 1:默认值
(6) iid=True
iid :默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
(7) refit=True
默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
(8) cv=None
交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器。
(9) verbose=0 , scoring=None
verbose :日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
(10) pre_dispatch=‘2*n_jobs’
指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
(11) error_score=’raise’
(12) return_train_score=’warn’
如果“False”,cv_results_属性将不包括训练分数
回到sklearn里面的GridSearchCV,GridSearchCV用于系统地遍历多种参数组合,通过交叉验证确定最佳效果参数。
3. Scoring parameter:评价标准参数详细说明
Model-evaluation tools using cross-validation (such as model_selection.cross_val_score and model_selection.GridSearchCV ) rely on an internal scoring strategy. This is discussed in the section The scoring parameter: defining model evaluation rules .
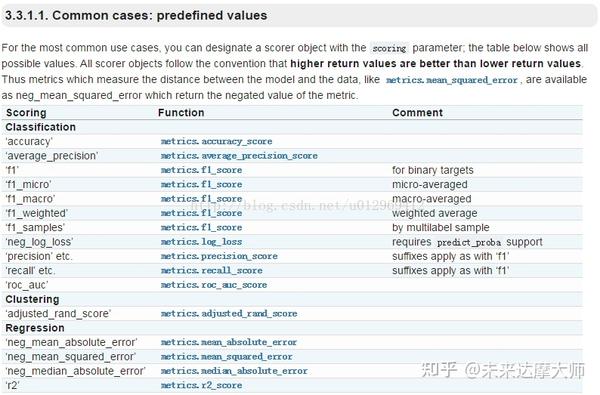
For the most common use cases, you can designate a scorer object with the scoring parameter; the table below shows all possible values. All scorer objects follow the convention that higher return values are better than lower return values . Thus metrics which measure the distance between the model and the data, like metrics.mean_squared_error , are available as neg_mean_squared_error which return the negated value of the metric.

4.属性
(1)cv_results_ : dict of numpy (masked) ndarrays
具有键作为列标题和值作为列的dict,可以导入到DataFrame中。注意,“params”键用于存储所有参数候选项的参数设置列表。
(2)best_estimator_ : estimator
通过搜索选择的估计器,即在左侧数据上给出最高分数(或指定的最小损失)的估计器。 如果 refit = False ,则不可用。
(3)best_score_ : float best_estimator的分数
(4)best_params_ : dict 在保存数据上给出最佳结果的参数设置
(5)best_index_ : int
对应于最佳候选参数设置的索引(cv_results_数组)。
search.cv_results _ ['params'] [search.best_index_]中的dict给出了最佳模型的参数设置,给出了最高的平均分数(search.best_score_)。
(6)scorer_ : function
Scorer function used on the held out data to choose the best parameters for the model.
(7)n_splits_ : int
The number of cross-validation splits (folds/iterations).
(8)grid_scores_: 给出不同参数情况下的评价结果
6.网格搜索实例
import pandas as pd # 数据科学计算工具
import numpy as np # 数值计算工具
import matplotlib.pyplot as plt # 可视化
import seaborn as sns # matplotlib的高级API
from sklearn.model_selection import StratifiedKFold #交叉验证
from sklearn.model_selection import GridSearchCV #网格搜索
from sklearn.model_selection import train_test_split #将数据集分开成训练集和测试集
from xgboost import XGBClassifier #xgboost
pima = pd.read_csv("pima_indians-diabetes.csv")
print(pima.head())
x = pima.iloc[:,0:8]
y = pima.iloc[:,8]
seed = 7 #重现随机生成的训练
test_size = 0.33 #33%测试,67%训练
X_train, X_test, Y_train, Y_test = train_test_split(x, y, test_size=test_size, random_state=seed
model = XGBClassifier()
learning_rate = [0.0001,0.001,0.01,0.1,0.2,0.3] #学习率
gamma = [1, 0.1, 0.01, 0.001]
param_grid = dict(learning_rate = learning_rate,gamma = gamma)#转化为字典格式,网络搜索要求
kflod = StratifiedKFold(n_splits=10, shuffle = True,random_state=7)#将训练/测试数据集划分10个互斥子集,
grid_search = GridSearchCV(model,param_grid,scoring = 'neg_log_loss',n_jobs = -1,cv = kflod)
#scoring指定损失函数类型,n_jobs指定全部cpu跑,cv指定交叉验证
grid_result = grid_search.fit(X_train, Y_train) #运行网格搜索
print("Best: %f using %s" % (grid_result.best_score_,grid_search.best_params_))
#grid_scores_:给出不同参数情况下的评价结果。best_params_:描述了已取得最佳结果的参数的组合
#best_score_:成员提供优化过程期间观察到的最好的评分