

Stata的微观数据清理

do文件获取:首先点击进入, Stata连享会 (arlionn) - Gitee.com
其次,在网页界面顶端“搜开源”搜索“dataclean”
再次,点击进入, Stata连享会/dataclean
最后,点击进入, 数据清理经验分享-涂冰倩.do · Stata连享会/dataclean - Gitee
强烈建议经济类的同学将该网址 Stata连享会 (arlionn) - Gitee.com 添加至电脑桌面。

打开Stata,这里笔者以StataMP16为例。记住do文件的一个快捷键:运行所选代码是Ctrl+D
数据的准备环节
1.读取数据
- 建立文件存储路径
* 建立文件存储路径
global Do "D:\Stata\联享会\数据清理\DoFiles" //存放各类do文件
global Raw "D:\Stata\联享会\数据清理\RawData" //存放原始数据
global Work "D:\Stata\联享会\数据清理\WorkingData" //存放清理后的数据
global Out "D:\Stata\联享会\数据清理\OutFiles" //存放分析结果
global Ref "D:\Stata\联享会\数据清理\Reference" //存放各种参考资料、文献等我这里是如上述代码路径建立了5个文件夹,这是为了将stata相关的数据分门别类,便于以后查找。global定义的是全局宏,goobal A B指的是用A表示B,且全程有效。
- 设置 Stata 环境
* 设置 Stata 环境
cd "$Work" //设置工作路径(可以自行进行修改)
capture log close //关闭以前的log文件,加capture不会报错
log using "$Work\datacleaning", replace
//新建一个名为datacleaning的log文件,log文件可以保存所有的运行记录
set more off //关闭持续翻屏
/* log 文件可以完整保存 Stata 界面的分析过程,以防没有及时保存或者想回溯之前的清理工作。*/do文件放在"D:\Stata\联享会\数据清理\DoFiles"中,log文件放在"D:\Stata\联享会\数据清理\WorkingData"中,本文将do文件和log文件同时命名为“datacleaning”。
- 数据的读取方法
将代码中的xx更改为自己的文件名。
/* 读取数据常用的四种方法 ,这些方法的命令前都加上了注释符,根据自己需要选择其中一个,输入自己的文件名*/
*use xx.dta //读取本地数据
*sysuse xx,clear //读取系统数据
*webuse xx,clear //直接读取网络数据
*import excel xx.xlsx,clear //可读取除stata格式以外的其他数据(如xlsx数据)由于本文只是做一个简单的实验,数据的生成是直接在do文件中手敲的。不依赖上述读取数据的办法。
- 读取/生成2001年农户数据(例子)
* 生成农户数据(仅为举例所用,不具有实际意义)
/* vid 为村庄编号;fid 为家庭编号;pid 为个人编号;
relation 为和受访者的家庭关系(1 为户主);
year 为调查年份;province 为省份 */
/* a1 性别;a2 出生年份;a3 是否外出务工;a4 外出务工时长(月);a5 外出务工收入(元) */
clear
input vid fid pid relation year province a1 a2 a3 a4 a5
1 1 1 1 2001 1 1 1971 1 11 2000
1 1 2 2 2001 1 2 2004 1 10 3000
1 1 3 3 2001 1 1 1996 0 . .
1 1 4 4 2001 1 2 1941 1 . .
1 2 5 4 2001 1 1 1956 0 8 3000
1 2 6 2 2001 1 3 1960 1 8 2000
1 2 7 3 2001 1 2 1981 1 11 4000
2 3 8 5 2001 2 1 1969 1 4 2000
2 3 9 1 2001 2 2 1971 1 11 4000
2 3 10 1 2001 2 2 1993 1 . .
save "$Raw\hh_year2001.dta",replace
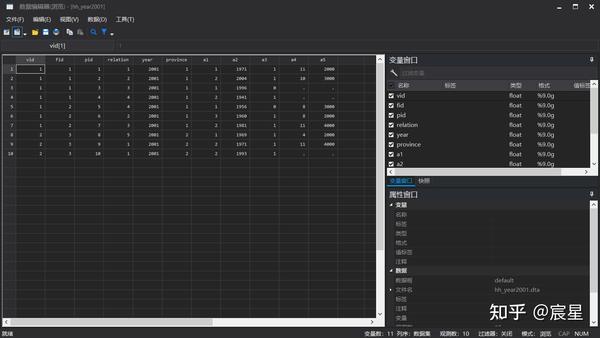
browse
*命令输入后,弹出表格式的数据编辑器,在该编辑器里可以浏览所有的数据弹出如下窗口,其中的变量名解释详见上方代码注释。

- 读取/生成2021年农户数据(例子)
clear
input vid2021 fid2021 pid2021 relation2021 year province a1 a2 a3 a4 a5
1 1 1 1 2021 1 1 1971 1 11 10000
1 1 2 1 2021 1 2 2004 1 10 4800
1 1 3 2 2021 1 1 1996 0 . .
1 1 4 5 2021 1 2 1941 0 . .
1 2 5 1 2021 1 1 1956 1 8 12000
1 2 6 3 2021 1 2 1960 1 8 30000
1 2 7 5 2021 1 2 1981 1 11 42000
2 3 8 3 2021 2 1 1969 1 4 25000
2 3 9 2 2021 2 2 1971 1 11 20000
2 3 10 4 2021 2 2 1993 0 . .
save "$Raw\hh_year2021.dta",replace
browse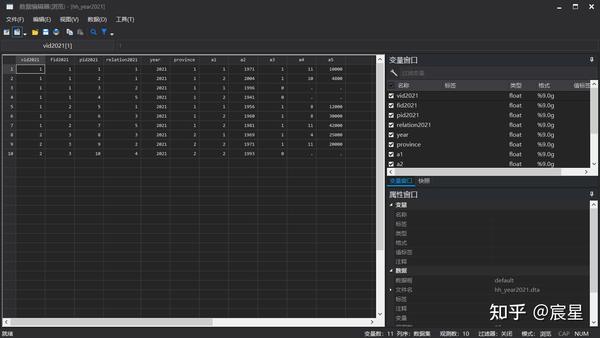

- 读取/生成两期(2001and2021)的村庄数据
* 生成村庄数据
/* c1 表示村庄内劳动力数量,c2 表示村庄人口数量 */
clear
input vid year c1 c2
1 2001 1000 1300
2 2001 2100 2300
3 2001 99999 2500
4 2001 4352 4600
5 2001 3210 3210
1 2021 2023 2300
2 2021 3105 3000
3 2021 3391 3912
4 2021 4310 4319
5 2021 3150 5000
1 2001 1000 1300
save "$Raw\village_data",replace
browse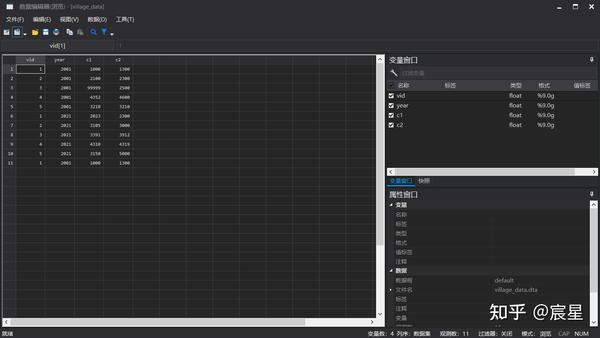

2.提取变量
导入数据后,由于数据库中存在大量的变量,我们尽量提取我们可能需要的变量并对其进行清理,省去很多不必要的麻烦。
在开始处理数据前,一定要对原始数据进行备份(在不同地方多做几个备份!)。一定要养成这样的好习惯。
- 保留或删除变量
* 保留或删除变量
use "$Raw\hh_year2001",clear
keep vid-year a1-a3 //保留 vid-year 以及 a1-a3 之间所有变量,等价于命令"drop province a4 a5"
keep in 2/10 //保留第 2 个到第 10 个之间的所有观测值 ,等价于命令"drop in 1"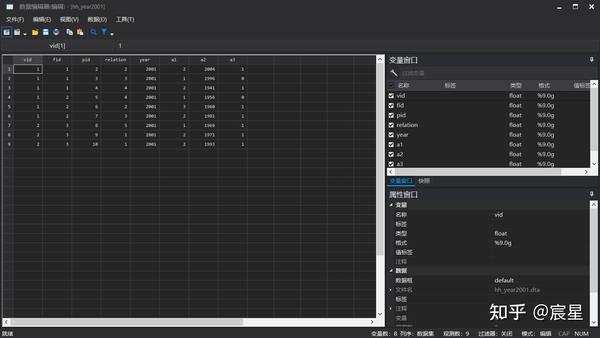

一定要注意删除变量是不可逆的操作,谨慎操作。
- 查看变量
* 变量的查看
use "$Raw\hh_year2001",clear
summarize a1-a5
codebook a1
inspect a2首先是选中的变量的描述性统计
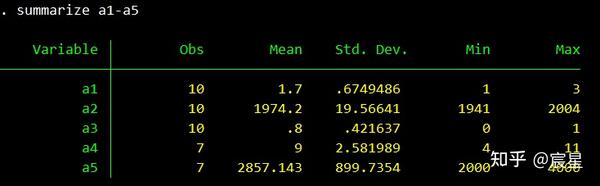

其次是对a1变量的属性的详细查看
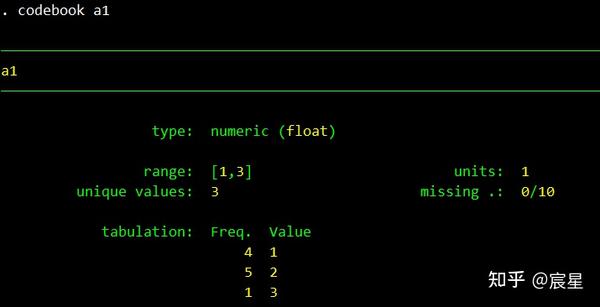

type说明是数值型,range说明其取值区间,missing说明10个观测值得缺失值为0
最后是对a2变量的属性的查看
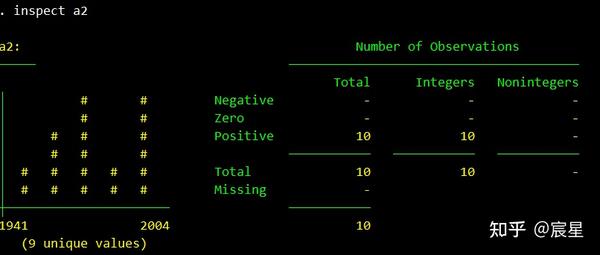

左边说明a2是从1941年到2004年的数据,Positive为10说明10个数都是正数,Missing后是-说明不存在缺失值
数据的合并与转换
- 纵向添加数据
增加数据的样本量就会涉及到数据的合并,即命令append(纵向添加)、merge(横向合并),merge比较复杂,可以先append再merge。
append常常用于增加时间、地点的数据。比如对象在2001年被访问,并于2021年被再次访问,需要将2021年的数据添加至2001年的原始数据上。
在添加数据之前,我们必须以2001原始数据的格式为基准,将2021年的新数据格式改为与2001年格式保持一致。
前面我们已经运行了use "$Raw\hh_year2001",clear
现在运行2021的数据如下:(不过在运行之前可能有的伙伴没有renvars命令相关的包,解决办法如下):
* 纵向添加数据 append
use "$Raw\hh_year2021.dta",clear //打开上面保存的数据
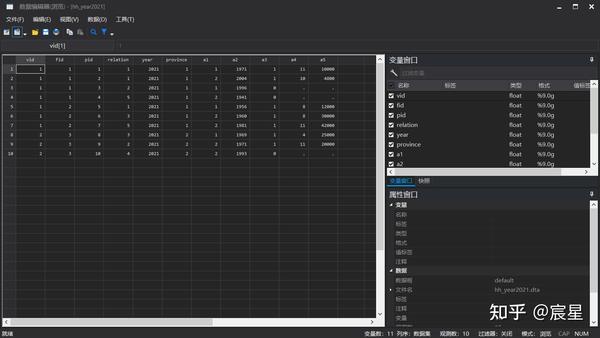
/* 数据对应,如图所示 */
renvars vid2021 fid2021 pid2021 relation2021 \ vid fid pid relation //修改变量名,以便于合并
browse
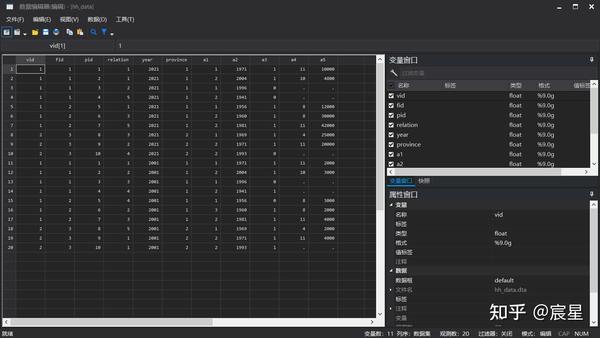
append using "$Raw\hh_year2001.dta" //合并之后应打开数据窗口检查变量对应情况
save hh_data.dta,replace *renvars命令出错时的解决办法:
方法一:
在Stata命令窗口输入命令:search renvars
点击下图中的链接
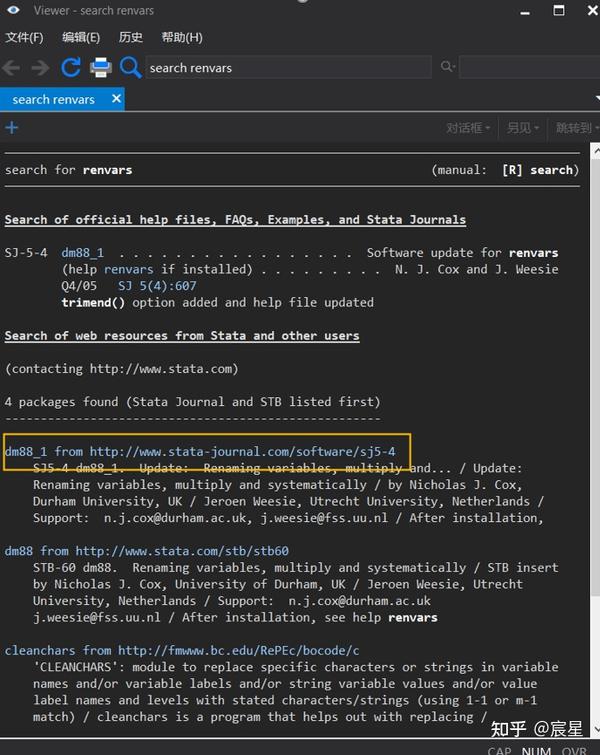

点击下图的下载选项即可
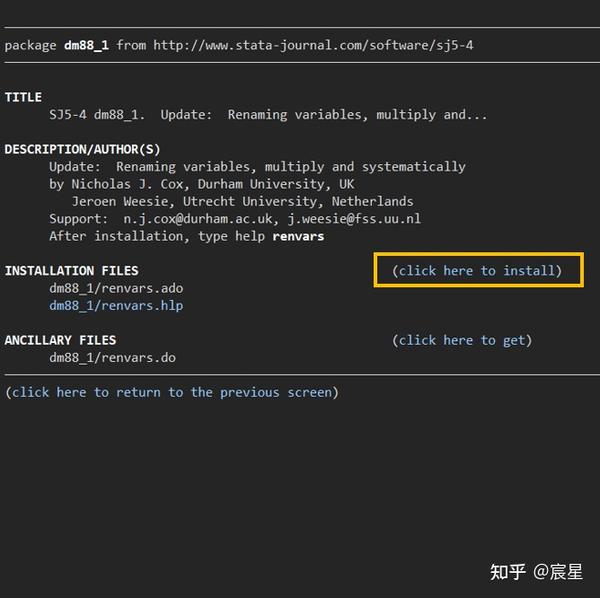

方法二:
用rename替代renvars,其语法是:


更改之后的数据如下:

合并之后的数据如下,注意此时的文件名也已完成更改:

- 横向添加数据
如果说纵向添加数据是增加观测值,那么横向添加数据是指增加新的控制变量或者说增加研究对象的其他属性。
横向合并类似于Arcgis属性表的关联,即两份表格(主数据与匹配数据)中至少有一项列变量是完全相同且唯一识别的。
merge命令的详细解释请见: merge命令 — 合并数据集
现将村庄数据和农户数据进行合并,一个村对应多个农户即一对多,现在需要查看村庄数据里的标识变量能否唯一识别每一条观察值。
关于duplicates命令的内容详见: [原创]stata寻找重复数据(duplicates) - 研究、学习、分享
* 横向合并数据 merge
use "$Raw\village_data.dta",clear //村庄数据
list in 2/5 //显示第2至5行的观测值
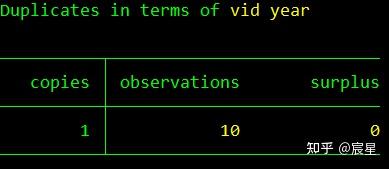
duplicates report vid year //查重,发现有两条信息重复
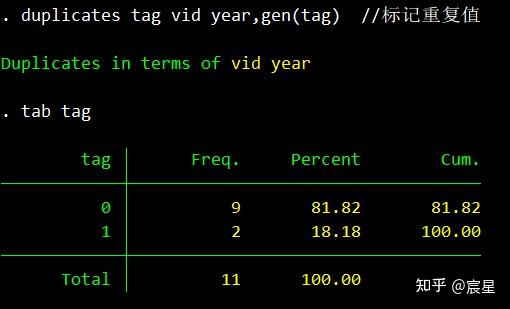
duplicates tag vid year,gen(tag) //标记重复值
tab tag
list _all if tag!=0 //发现是录入重复,只需要任意删掉其中一条
duplicates drop vid year,force //删除重复值,force将非数字字符串转换为缺失值
//drop if tag!=0
merge 1:m vid year using hh_data.dta
/*将主文件(村数据)根据 vid 和 year 与匹配文件(农户数据)
进行对应,一个村庄观察值将对应多个家庭观察值*/
keep if _merge==3
//保留成功匹配上的数据,1 表示仅来自主文件,2 表示仅来自子文件,3 代表被匹配上的观察值
drop _merge
save vill_hh.dta ,replace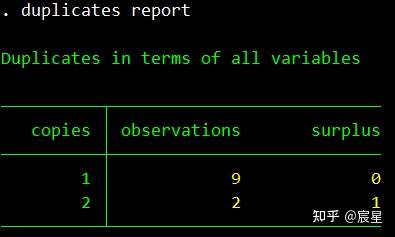
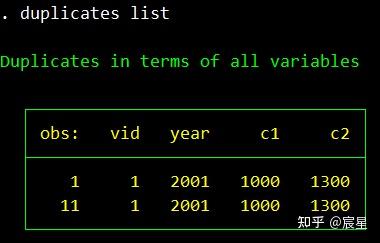
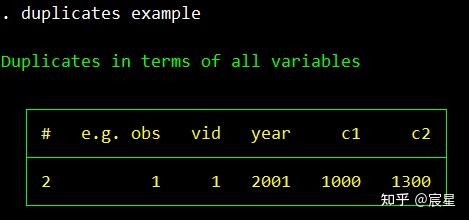

duplicates命令的使用参考上面三张图片即可。
do文件中的duplicates相关命令的运行结果如下所示:

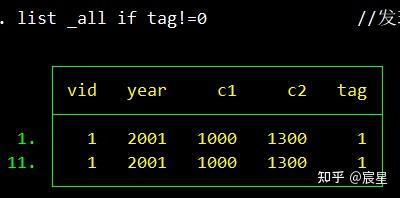
下面是正式的merge的运行结果:
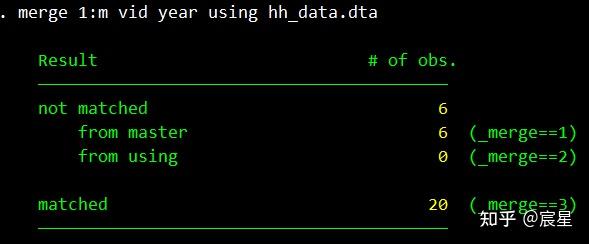

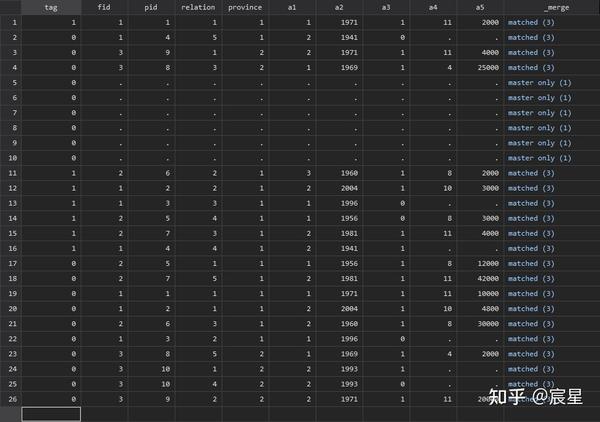

_merge=3表示两个数据集中成功对应的观测值有20个,_merge=1表示没有匹配上的观测值是来源于主数据,merge=2表示没有匹配的观测值来源于匹配数据。
_merge变量只是合并过程中的一个中间变量,合并成功即可drop删除掉。合并成功的数据显示如下:

刚才是讲述“数据的合并”,本文对于“数据的转换”不做太多解释,读者可以按照下列命令进行学习:
ssc install lianxh //lianxh是连享会的简称,可以下载这个包学习
lianxh reshape //在lianxh这个包里可以学习reshape命令

检查数据
- 查看标识变量
* 查看标识变量的命令 isid unique duplicates
use hh_data,clear
isid pid year //方法一:运行结果为空表明标识变量唯一且不重复
*ssc install unique //可能你的stata没有安装这个包,把*号去掉即可
unique pid year //方法二:显示非重复值个数
duplicates report pid year //方法三:显示标识变量的重复次数
duplicates list pid year //方法四:展示重复值
duplicates tag pid year, gen(tag1) //方法五:标记重复值
tabulate tag1
drop tag1这里用的是农户面板数据hh_data,另外ssc install unique命令可能需要运行。
其中,下图的意思是20个观测值均只出现了一次。
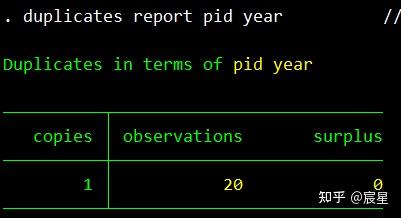
下图中的tab是指列表的形式显示。


- 检查变量基本情况
* 检查变量基本情况
describe //对所有变量进行展示,des也可以
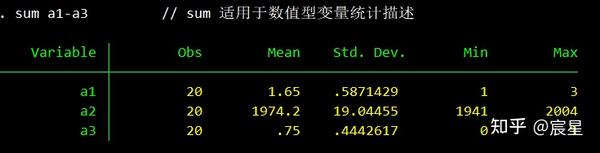
sum a1-a3 // sum 适用于数值型变量统计描述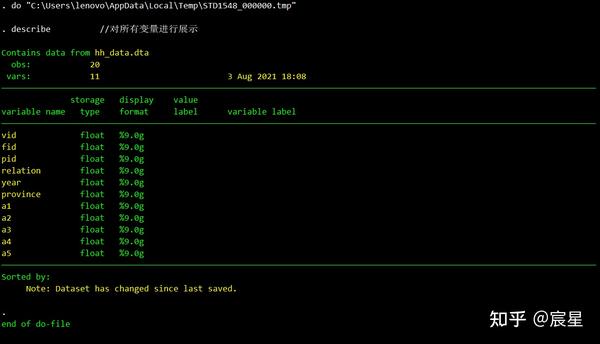


- 格式转换
由于在stata数据处理中,要求数据均为数值型,那么就会涉及到数据的格式转换。
* 格式转换
tostring a1,replace //将 a1 变量转换成字符型变量
browse
destring a1,replace //将字符型变量转换为数值型变量,如果字符型是汉字,那么会显示缺失值
tostring province,replace //将省代码转换为字符型变量
replace province="湖南" if province=="1"
replace province="山东" if province=="2"
list province in 1/10
encode province,gen(provid) //转换之后会自动生成与原文字对应的值标签
label list provid //label list可查看转换之后的数字文字对应表可以从下图看到,数值型转为字符型时,字体颜色有变化。
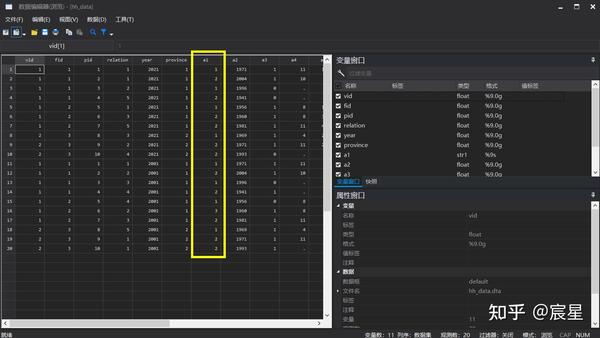

上述代码的最后两行结果显示如下:
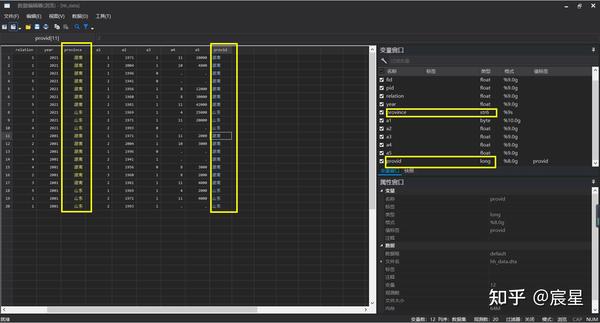

上图清楚地看到,province变量的观测值是字符型,而provid变量的观测值是长整型,也就是说,provid变量的观测值虽然是显示汉字,但其实汉字只是标签,而其实质是可以进行计算的长整型数值。
数据清理
前面的步骤只是数据的预处理,包括读取数据、提取变量、数据的合并、数据的检查。下面开始进入正式的数据清理步骤。
- 单变量的清理
一方面,考虑分类变量的清理过程。
其实就是变量的查看des、添加标签label、异常值的查看、新建变量对异常值修改并保存。
* 分类变量的清理和生成
* 举例1:a1 变量的清理
* 清理目标:检查 a1(性别)变量,查找并修改异常值,生成性别变量(虚拟变量)
use hh_data.dta,clear
describe a1 //检查变量标签
label var a1 "受访者的性别" //构建标签
des a1 //检查是否改对变量标签
label define a1lab 1"男" 2"女" //为 a1 变量定义一个值标签,命名为 a1lab
label values a1 a1lab //将值标签 a1lab 赋给变量 a1
label list a1lab //查看其值标签
tabulate a1,missing //查看变量的所有取值及频数,附加选项missing可以查看其缺失值数量(包括系统缺失值)
/*发现a1存在取值为1和2之外的观察值,这里用list列出取值为3的观察值进行查看,
并在生成新变量的基础上对异常值进行修改或设置为缺失值。*/
list pid a1 a2 a3 a4 a5 if a1==3 //第一种检查方法,查看这条异常值
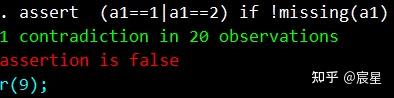
assert (a1==1|a1==2) if !missing(a1) //!miss(a1)是不存在a1的缺失值
//第二种检查方法,报告非法值,结果为空表示assert后所列条件为真。由于a1不存在缺失值,故这条命令等价于assert (a1==1|a1==2)
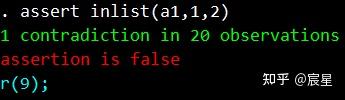
assert inlist(a1,1,2)
//和上面那条命令等价,inlist函数表示a1变量取值为1或者2则返回,否则为0
count if (a1!=1) & (a1!=2) & !missing(a1)
//第三种检查方法,列示出符合if条件后的样本值个数,相当于assert命令的逆操作
*我们要新建一个新变量,对原变量修改异常值,这样就可以保留原变量
recode a1 ( 2=0 "女" ) ( 1=1 "男" )( 3=. ), gen (gender)
/*根据原始变量生成新变量,不要直接在原始变量上进行改动*/
label var gender "受访者的性别" //为新生成的变量附加标签
sum a1 gender //对更改结果进行查看,确保变量生成正确上述代码中又一次出现了label的命令,我们可以通过下图更直观学习该命令:
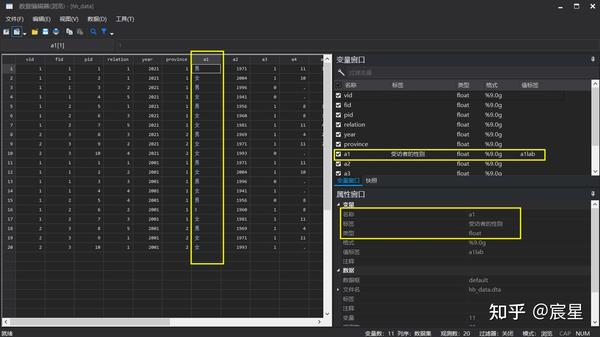

根据下图可以看到表示性别的a1变量居然存在异常值3,因为性别必须是二值变量的。
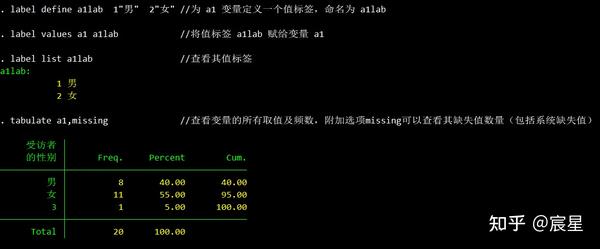

下面提供几种查看异常值方法的显示结果。
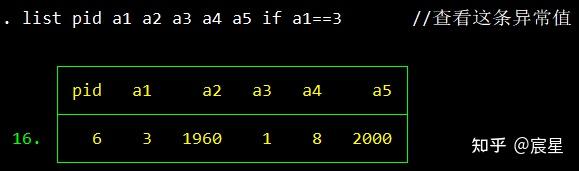



- 连续变量的清理
另一方面,考虑连续变量的清理步骤。
其实就是变量的查看des、添加标签label、查看异常值、生成新变量更改异常值、新变量的标签。
* 连续变量的清理和生成
* 举例2:a2 变量的清理
* 清理目标:检查变量a2(出生年份),生成连续变量、有序变量
des a2
label var a2 "受访者的出生年份"
des a2
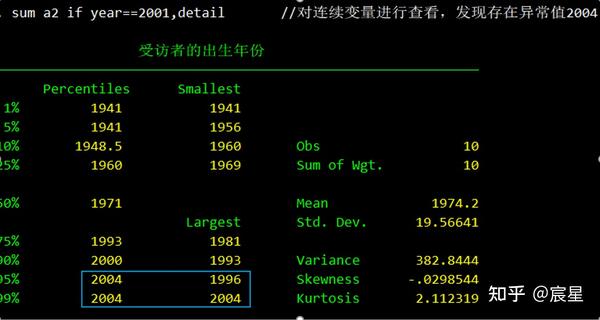
sum a2 if year==2001,detail //对连续变量进行查看,发现存在异常值2004
sum a2 if year==2021,detail
generate age=year-a2 if a2!=2004 //根据原始变量生成新的年龄变量(调查年份-出生年份)
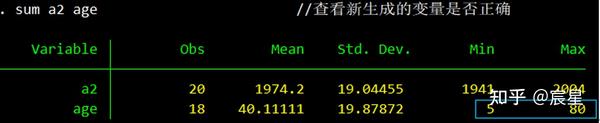
sum a2 age //查看新生成的变量是否正确
recode age (5/17=1 "儿童组") (18/59=2 "成年组") (60/80=3 "老年组"), gen (agegroup) lab(labagegroup)
//根据age变量生成agegroup变量,并将值标签命名为labagegroup
label list labagegroup //查看值标签
sum age agegroup //检查变量是否生成正确
/*如果要把不同年龄段的人平分成不同的组,可以采用 cohort 命令或者 autocode 命令*/
sort age
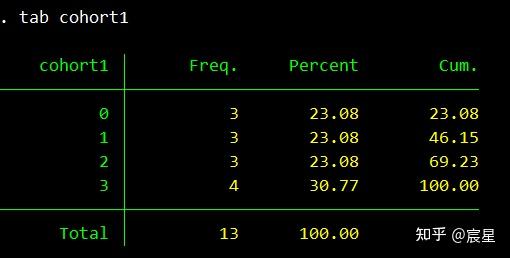
egen cohort1=cut(age) if inrange(age,18,60), group(4) //将18-60岁的人平分成4个组
tab cohort1
replace cohort1=cohort1+1
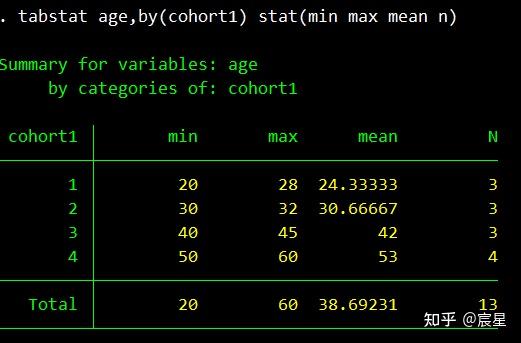
tabstat age,by(cohort1) stat(min max mean n) //对不同组别受访者的年龄进行描述统计
save "hh_data_new",replace //清洗完的数据应该被保存在一份新的data文件中下图可以很清楚看到2001年的采访是不可能存在2004年出生的农户,可能是录入数据错误或者其他原因。

下图初步查看修改后的age似乎没什么问题。



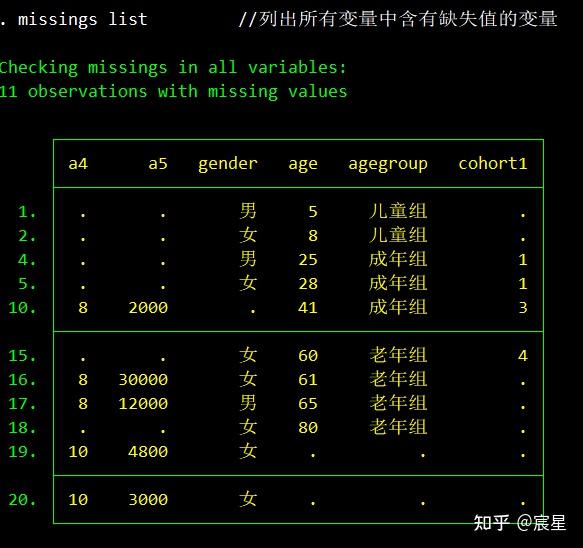
- 缺失值、极端值的查验和处理
* 缺失值、极端值的查验和处理
* 对于缺失值的查看
use "hh_data_new",clear
misstable pattern //列示缺失值的模式
misstable sum a4 //查看a4变量缺失值的基本统计
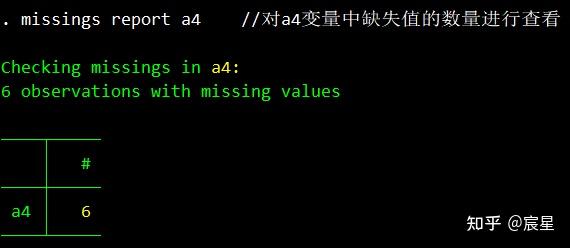
missings report a4 //对a4变量中缺失值的数量进行查看,运行之前可能需要search missings
missings list //列出所有变量中含有缺失值的变量
missings dropobs a1 a2 a3,force
/* 对a1,a2,a3都存在缺失值的样本值进行删除(若某一观察值对应的
所有变量取值都为缺失值,则将该条观察值从样本中进行删除。) */
missings dropvars a1 a2 a3 //若某一变量中所有取值都为缺失值,则删除该变量
/* 缺失值在stata中被当做最大值来保存,在计算变量的时候要格外注意这一点 */
*******************************************************************************
* 缺失值的处理(仅作为参考)
/* 构造数据:两个县城(cid)三个村(vid) 2001 年 - 2020 年的销售量(b1)、
销售单价(b2)、总产量(b3)与种植面积(b4),假设种的是一种作物 */
clear
set seed 10000
set obs 60
gen vid=1
replace vid=2 in 21/40
replace vid=3 in 41/60
gen cid=1
replace cid=2 in 41/60
egen year=seq(),from(2001) to (2020)
gen b1=int(100*runiform())
gen b2=int(10*runiform())
recode b1(0=.)
recode b2(0=.)
gen b3=b1+20
gen b4=runiform()
replace b2=-3 in 5
replace b2=. in 26
replace b2=. in 45
replace b2=100 in 60
replace b1=. if b2==.
list vid cid year b1 b2 b3 b4 in 37/41 //查看数据
save "$Raw\sale_data",replace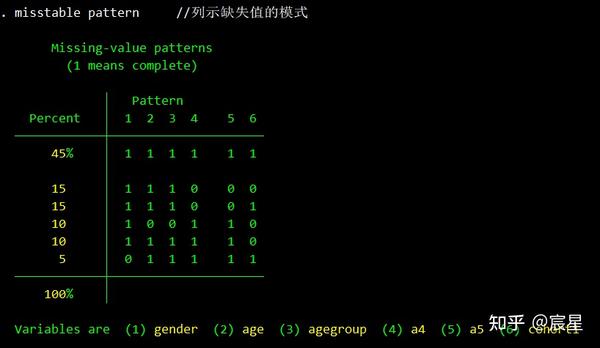





上述是检查缺失值,下面介绍如何处理缺失值。
单变量清理
运行命令后,可以看到销售单价(b2)出现了异常值。
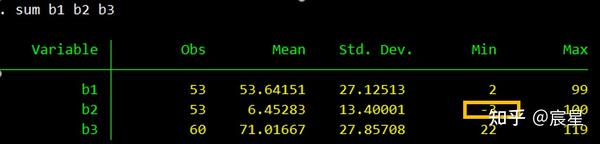
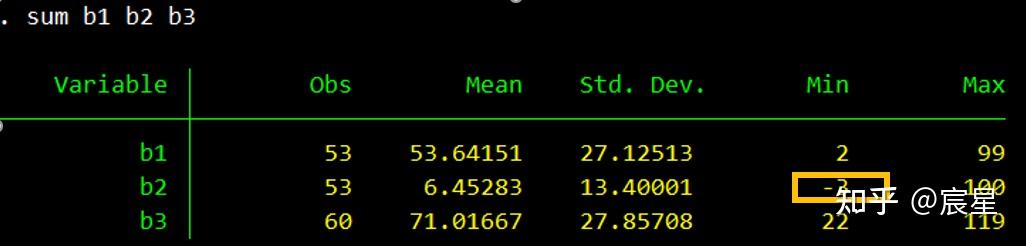
* 单变量清理
sum b1 b2 b3
gen sale=b1
recode b2(-3=.),gen (price) //修改异常值,生成新变量
gen output=b3
sum b1 sale b2 price b3 output //对比新生成的变量和原变量
gen income_sale=sale*price //生成销售收入(销售量*价格)
list sale price output in 43/46 - 单变量清理的方法一
* 方法一:通过统计值进行推断
* 举例3:计算销售收入和总收入
gen newprice=price //在生成新变量的基础上进行补漏
foreach i in vid cid{
bysort `i':egen mean_`i'_price=mean(price) //按村庄/县城生成价格均值数据
bysort `i':egen sd_`i'_price=sd(price) //按村庄/县城生成价格标准差数据
replace newprice =. if (abs(newprice - mean_`i'_price)>3* sd_`i'_price) //对极端值的处理
replace newprice =mean_`i'_price if newprice==. & mean_`i'_price!=.
drop mean_`i'_price sd_`i'_price
label var newprice "销售价格(处理了极端值和缺失值)"
sum newprice price //将处理了异常值和进行了缺失值补漏的价格数据与原价格数据进行对比
gen income_total=newprice*output //生成总收入(总产量*价格)- 单变量清理的方法二
* 方法二:插值补漏
sum b4
gen plantarea=b4
list vid year plantarea in 1/5 //查看前五个样本数据
drop in 23/25 //构造一份不完整的数据
list vid year plantarea in 22/25
xtset vid year
tsfill,full //根据标识变量对数据进行填充,补充成完整面板数据
list vid year plantarea in 22/25
list vid year plantarea if missing(plantarea) //查看缺失值
gen plantarea_new=plantarea //在新变量基础上进行补漏
bysort vid:ipolate plantarea year,gen(temp_plantarea) epolate
/* 使用 ipolate 时,第一年和最后一年的数据无法进行插补,
加epolate命令表示根据数据进行外推 */
replace plantarea_new=temp_plantarea if plantarea_new==. & !missing(temp_plantarea)
drop temp_plantarea
sum plantarea_new plantarea //补漏后进行查验对比
label var plantarea_new "种植面积(补漏后)"- 单变量清理的方法三
* 方法三:采用周围非缺失值进行弥补
gen plantarea2=plantarea
by vid :replace plantarea2=plantarea[_n-1] if missing(plantarea2)
//其中两个缺失值的前一年取值也为缺失值
list vid year plantarea plantarea2 in 22/25
sum plantarea2 plantarea //补漏后进行查验*采用上一年非缺失值进行弥补
save "sale_data_reg",replace //完成数据清理,进行保存供分析所用- 极端值的查验
* 对于极端值的查验
/*如何发现极端值?一是通过画散点图或箱线图来识别,
二是通过描述统计进行判断*/- 极端值的处理思路
* 极端值的处理思路
/*对于极端值的处理上文有所提及,可以考虑遵循以下步骤进行处理:
一是查验极端值是否是因为数据输入错误造成的并进行相应更正。
二是考虑极端值的生成是否与研究主题有关,必要时可以删除存在极端值的样本
(在进行数据的删除时一定要慎重!)
三是可以通过取对数、缩尾(winsor2)等方法进行处理。
四是在对极端值进行处理前,可以先试着跑一下回归结果,
对比下处理与未处理极端值的回归结果。*/- 极端值的发现及处理(举例)
* 发现极端值
* 举例4:查看和处理外出务工收入(a4)变量的极端值
use hh_data_new.dta,clear
sum a5,detail
gen outincome=a5
histogram outincome //第一种方法,画直方图查看变量是否存在左偏(有偏)的情况
graph box outincome //第二种方法,画箱线图,将展示数据的最大值最小值、上下四分位数、中位数
* 对极端值的处理
gen logincome=log(outincome) //取对数
hist logincome
winsor2 outincome, cuts(1 99)
/* 小于 1% 分位和大于 99% 分位的观察值分别被 1% 分位和 99% 分位上的观察值替代,
缩尾后的变量将以"_w"结尾命名 */
winsor2 outincome, suffix(_t) cuts(1 99) trim
/* 小于 1% 分位和大于 99% 分位的观察值将被替换为缺失值,
截尾后的变量以"_t”结尾命名 */
save hh_data_new,replace
多变量清理
- 用分类变量检查分类变量
* 用分类变量检查分类变量
/*marriedornot 表示是否结过婚(0-1 变量),
marriednow 表示当下是否处于婚姻状态(0-1 变量)*/
clear
input marriedornot marriednow
tabulate marriednow marriedornot,missing
count if marriednow==1 & marriedornot==0
list marriednow marriedornot if marriednow==1 & marriedornot==0- 用连续变量检查分类变量
* 用连续变量检查分类变量
* 举例5:用外出务工时长(a4)检查是否外出务工(a3)
use hh_data_new.dta,clear
des a3 a4
sum a3
gen outornot=a3
label var outornot "是否外出务工"
sum a4
gen outtime=a4
label var outtime "外出务工时长"
bysort outornot: sum outtime //根据 outornot 不同取值对 outtime 进行描述统计
sort pid year
list pid year relation age outornot outtime outincome if outornot==0 & !missing(outtime)>0
//找出这些不符合逻辑的观察值(未外出务工的受访者不应该有外出务工时长)
/*联合其他变量对异常值进行更改:发现第9个观察值存在外出务工时间和收入,故将此受访者的 outornot 更改为1*/
replace outornot=1 if pid==5 & year==2001
list pid year relation age outornot outtime outincome if outornot==0 & !missing(outtime)>0 //查看更改是否正确
/*另外,在有外出务工(outornot==1)的类别里,是否存在被访者外出务工时长(outtime)却为缺失值呢?*/
list pid year relation age outornot outtime outincome if outornot==1 & outtime==.
/*发现第 19 个观察值外出务工时长(outtime)为缺失值且不存在外出务工收入(outincome),
同时其年龄(age)为 8 岁,不太可能外出务工,故把 outornot 更改为 0,并把 outtime 改为 0*/
replace outornot=0 if pid==10 & year==2001
list pid year relation age outornot outtime outincome if outornot==1 & outtime==. //检查更改结果
/*第 7 个观察值外出务工时长(outtime)为缺失值且不存在外出务工收入(outincome),
但没有其他辅助信息,是否外出务工仍不能确定,可以选择将该观察值设为缺失值或者不进行处理*/
save "hh_data_new",replace
- 用连续变量检查连续变量
* 用连续变量检查连续变量 sum count assert
* 举例6:用村总人口数(c2)检查村劳动人口数(c1)
use "$Raw\village_data",clear
sum c1 c2
tab c1 //发现存在异常值99999
recode c1 (99999=.) ,gen(v_labor)
sum c1 v_labor //检查更改结果
label var v_labor "村庄劳动力数量"
gen v_pop=c2
label var v_pop "村庄总人口数"
count if v_labor>v_pop & !missing(v_labor) //村劳动人口不应超过村总人口数
assert v_labor<=v_pop if v_labor!=. //上一条命令的等价命令,运行结果为空表示为真
list vid year v_labor v_pop if (v_labor>v_pop) & !missing(v_labor) //列出不符合实际的数据
replace v_pop=v_labor if vid==2 & year==2021 //将劳动力人口数据更改为人口数据,或者设置为缺失值
list vid year v_labor v_pop if (v_labor>v_pop) & !missing(v_labor) //检查更改结果
save "village_data_new",replace综合变量生成
例1
* 举例7:检查户主是否唯一
use hh_data_new.dta,clear
browse fid pid year relation head
gen head=cond(relation==1,1,0)
//如果该条观察值是户主,head变量取值为1,否则取值为 0
/*cond是条件函数,如果符合第一个逗号前的判断条件,即返回第二个逗号前的值,否则返回最后一个值。*/
bysort fid year:egen headnum=sum(head) //计算每年每户的户主数量
tab headnum,m //取值为1表明一户有一个户主
/*对于没有户主家庭,指派成年男性为户主(还可以是指派成年女性或者被访问的第一人为户主等等)*/
gen relation2=relation
replace relation2=1 if headnum==0 & agegroup==2 & gender==1
/*对于有多位户主的家庭,指派年龄最小的成年男性为户主*/
bysort fid year:egen min_male_age=min(age) if (gender==1) & (agegroup==2)
browse fid pid year relation relation2 head headnum min_male_age age
//识别出一个家庭最小成年男性的年龄
replace relation2=. if (headnum==2) & (relation==1)
//将存在多个户主的家庭的关系变量设置为缺失值
replace relation2=1 if (headnum==2) & (age==min_male_age) & !missing(age)
//当成年男性受访者年龄为家庭最小时,被指派为户主
list fid pid year age relation2 relation headnum if headnum==0|headnum==2
//对修改后的关系变量relation2进行查看例2
* 举例8:综合变量生成-家庭18岁以上人口比例和抚养系数比
/* 抚养系数比指的是人口中非劳动年龄人口数与劳动年龄人口数之比,
这里定义非劳动年龄人口指14岁及以下和65岁及以上人口。*/
bysort fid year:gen hnum1=_N //计算每组中观察值个数,包括缺失值
bysort fid year:egen hnum2=count(pid) //计算每组中的非缺失值观察值个数
gen child=cond(age<=14,1,0) //如果受访者在14岁及以下,取值为1,否则取值为0
gen old=cond(age>=65,1,0)
gen adult=cond(age>14 & age<65,1,0)
gen adult18=cond(age>=18,1,0)
list fid pid year age child old adult adult18 in 1/4
foreach i in child old adult adult18 {
bysort fid year:egen n_`i'=sum(`i')
//分组计算每个家庭每年的 child 等人数
gen adult18_ratio=n_adult18/hnum2
gen dependency_ratio=(n_child+n_old)/n_adult
sum adult18_ratio dependency_ratio //检查生成的变量
观测值组间计算-根据观测值分组
bysort gender: sum outincome //按性别查看收入变量
bysort gender:egen income_mean=mean(outincome) //按性别生成收入均值
//等价于egen income_mean=mean(outincome),by(gender)
bysort gender:egen income_max=max(outincome) //按性别生成收入最大值
bysort gender:egen income_min=min(outincome) //按性别生成收入最小值
bysort gender:egen income_sd=sd(outincome) //按性别生成收入标准差
bysort gender:egen income_sum=sum(outincome) //按性别生成加总值
bysort gender:egen income_total=sum(outincome) //按性别生成加总值
bysort gender:gen income_sum2=sum(outincome)
/*命令egen通过函数创建新变量,在egen命令前使用bysort选项,表明按照该变量进行排序并分组操作。*/
/*在egen命令后使用sum和total函数都能计算每个组别的加总值,并且计算时将缺失值自动视为0。*/
/*在使用sum函数时,采用egen命令和gen命令操作不同,前者是对组内所有观察值进行加总,而后者是进行累加。*/
sum outincome
gen income_standard=outincome-r(mean)/r(sd) //将income标准化观测值组内计算-变量分组
/* 按列进行计算一般不加 by (sort) var 选项,常用的选项包括生成行均值 rowmean、
行方差 rowsd、行最大值 rowmax、行最小值 rowmin、行中位数 rowmedian、行加总 rowtotal。 */
egen rowtotal=rowtotal(age a5) //仅作为举例,不考虑变量实际含义
gen plus=age+a5
list age a5 rowtotal plus in 1/10
/*直接对变量相加生成新的变量时,若为存在至少一个缺失值,
那么整个加总值都将为缺失值,而 rowtotal 将缺失值视 0 进行加总*/
/* rownomiss: 计算一组变量中非缺失值的数量
anycount: 查看变量列表中元素的个数
anymatch: 变量列表中若否存在某个元素返回1,否则返回0
anyvalue: 指定变量若存在某个元素则返回该元素值,否则返回缺失值
diff: 查看变量是否相等
group: 根据变量进行分组 */
egen female1=anymatch(gender),value(0) //性别变量若取值为 0 则返回 1,否则返回 0
egen female2=anyvalue(gender),value(0) //性别变量若取值为 0 则返回 0,否则生成缺失值
list pid gender female1 female2 in 9/14,sepby (gender)
数据清理收尾工作
keep fid year gender age adult18_ratio dependency_ratio //保存分析需用到的变量
order fid year gender age adult18_ratio dependency_ratio //给变量排序
* 提取家庭数据
collapse gender age adult18_ratio dependency_ratio,by(fid year)
label data "数据清理20210615" //给数据添加标签
save data_reg,replace //保存清洗过的数据,为分析所用
log close //关闭log文件心得与学习资料推荐
* 两个注意
* 两个查看
* 数据清理是一个不断重复的过程
* 实践出真知
* 多用help,巧用搜索
* 不要等所有的菜都齐了才下锅
* CFPS中国家庭追踪调查官方网站
* 连享会及各公众号系列推文
* 两个Stata命令:lianxh songbl
* B站up主:silencedream ;小志小视界 ;胖成球的小方块 ;差点没头 ……
* 迈克尔·N·米歇尔. Stata环境下的数据管理实务手册[M]. 中国人民大学出版社, 2016.
* 唐丽娜. 社会调查数据管理:基于Stata14管理CGSS数据[M]. 人民邮电出版社, 2016.
* 斯考特·隆恩. 基于 Stata 的数据分析流程[M]. 中国人民大学出版社, 2019.本文全部的原do文件代码如下,但是本人运行发现部分代码可能运行出错,建议读者按照上述的长篇大论先尝试浏览清楚:
**********************************************
***********微观数据库清理经验分享************
***********作者:浙江大学-涂冰倩*************
***********时间:2021-07-14*******************
**********************************************
**********************************************
**************数据清理流程提要****************
**********************************************
*-课程主页:发布视频回放链接等
view browse "https://gitee.com/arlionn/dataclean"
*-连享会主页
view browse "https://www.lianxh.cn"
view browse "https://www.zhihu.com/people/arlionn/"
*-b 站
view browse "https://space.bilibili.com/546535876"
*-连享会公众号:
* Name: 连享会
* ID: lianxh_cn
* step 1 设置工作路径与生成log文件
cd "E:\stata\连享会" //设置工作路径(可以自行进行修改)
capture log close //关闭以前的log文件,加capture不会报错
log using datacleaning, replace //新建一个名为datacleaning的log文件
* step 2 读取数据+熟悉数据
* step 3 整理和提取变量
//保留数据通过保留列(变量)和保留行(观测值)两种方式实现 keep drop
//主要清洗可能使用到的数据
* step 4 数据的合并与转换
//一般来说,先append再merge比较合适
**纵向添加数据append
//append需变量名及变量格式对应
**横向合并数据merge
//至少保证其中一方数据能被识别变量唯一识别
**长宽数据转换reshape
**数据堆叠gather spread stack
* step 5 检查数据
**检查重复数据(标识变量 + 数据)
**检查变量整体情况
* step 6 数据清理
**单变量清理
//在生成新变量的基础上进行修改,更改后要查验
***分类变量的清理
***连续变量的清理
***缺失值查验和处理
***极端值查验和处理
**多变量清理
***用分类变量检查分类变量
***用连续变量检查分类变量
***用连续变量检查连续变量
* step 7 综合变量生成
**观测值组间计算-根据观测值分组
**观测值组内计算-变量分组
* step 8 筛选变量 + 另存为新数据 + 关闭 log 文件
keep var //保存分析需用到的变量
order var1 var2 //给变量排序
label data "数据清理20210615" //给数据添加标签
save data_reg,replace //保存清洗过的数据,为分析所用
log close //关闭log文件
**********************************************
**************数据清理:准备环节**************
**********************************************
*******************读取数据*******************
* 建立路径
global Do "E:\stata\连享会\数据清理经验分享\DoFiles" //存放各类do文件
global Raw "E:\stata\连享会\数据清理经验分享\RawData" //存放原始数据
global Work "E:\stata\连享会\数据清理经验分享\WorkingData" //存放清理后的数据
global Out "E:\stata\连享会\数据清理经验分享\OutFiles" //存放分析结果
global Ref "E:\stata\连享会\数据清理经验分享\Reference" //存放各种参考资料、文献等
* 设置 Stata 环境
cd "$Work" //设置工作路径(可以自行进行修改)
capture log close //关闭以前的log文件,加capture不会报错
log using "$Work\datacleaning", replace //新建一个名为datacleaning的log文件
set more off //关闭持续翻屏
/* log 文件可以完整保存 Stata 界面的分析过程,以防没有及时保存或者想回溯之前的清理工作。*/
/* 读取数据常用的四种方法 */
use xx.dta //读取本地数据
sysuse xx,clear //读取系统数据
webuse xx,clear //直接读取网络数据
import excel xx.xlsx,clear //可读取除stata格式以外的其他数据(如xlsx数据)
* 生成农户数据(仅为举例所用,不具有实际意义)
/* vid 为村庄编号;fid 为家庭编号;pid 为个人编号;
relation 为和受访者的家庭关系(1 为户主);
year 为调查年份;province 为省份 */
/* a1 性别;a2 出生年份;a3 是否外出务工;a4 外出务工时长(月);a5 外出务工收入(元) */
clear
input vid fid pid relation year province a1 a2 a3 a4 a5
1 1 1 1 2001 1 1 1971 1 11 2000
1 1 2 2 2001 1 2 2004 1 10 3000
1 1 3 3 2001 1 1 1996 0 . .
1 1 4 4 2001 1 2 1941 1 . .
1 2 5 4 2001 1 1 1956 0 8 3000
1 2 6 2 2001 1 3 1960 1 8 2000
1 2 7 3 2001 1 2 1981 1 11 4000
2 3 8 5 2001 2 1 1969 1 4 2000
2 3 9 1 2001 2 2 1971 1 11 4000
2 3 10 1 2001 2 2 1993 1 . .
save "$Raw\hh_year2001.dta",replace
browse
clear
input vid2021 fid2021 pid2021 relation2021 year province a1 a2 a3 a4 a5
1 1 1 1 2021 1 1 1971 1 11 10000
1 1 2 1 2021 1 2 2004 1 10 4800
1 1 3 2 2021 1 1 1996 0 . .
1 1 4 5 2021 1 2 1941 0 . .
1 2 5 1 2021 1 1 1956 1 8 12000
1 2 6 3 2021 1 2 1960 1 8 30000
1 2 7 5 2021 1 2 1981 1 11 42000
2 3 8 3 2021 2 1 1969 1 4 25000
2 3 9 2 2021 2 2 1971 1 11 20000
2 3 10 4 2021 2 2 1993 0 . .
save "$Raw\hh_year2021.dta",replace
* 生成村庄数据
/* c1 表示村庄内劳动力数量,c2 表示村庄人口数量 */
clear
input vid year c1 c2
1 2001 1000 1300
2 2001 2100 2300
3 2001 99999 2500
4 2001 4352 4600
5 2001 3210 3210
1 2021 2023 2300
2 2021 3105 3000
3 2021 3391 3912
4 2021 4310 4319
5 2021 3150 5000
1 2001 1000 1300
save "$Raw\village_data",replace
browse
*****************提取变量*******************
/*在开始处理数据前,一定要对原始数据进行备份(在不同地方多做几个备份!)*/
* 保留或删除变量
use "$Raw\hh_year2001",clear
keep vid-year a1-a3 //保留 vid-year 以及 a1-a3 之间所有变量,等价于命令"drop province a4 a5"
keep in 2/10 //保留第 2 个到第 10 个之间的所有观测值 ,等价于命令"drop in 1"
* 变量的查看
use "$Raw\hh_year2001",clear
summarize a1-a5
codebook a1
inspect a2
***************数据的合并与转换****************
* 纵向添加数据 append
use "$Raw\hh_year2021.dta",clear //打开上面保存的数据
/* 数据对应,如图所示 */
renvars vid2021 fid2021 pid2021 relation2021 \ vid fid pid relation //修改变量名,以便于合并
browse
append using "$Raw\hh_year2001.dta" //合并之后应打开数据窗口检查变量对应情况
save hh_data.dta,replace
* 横向合并数据 merge
use "$Raw\village_data.dta",clear //村庄数据
list in 2/5
duplicates report vid year //发现有两条信息重复
duplicates tag vid year,gen(tag) //标记重复值
tab tag
list _all if tag!=0 //发现是录入重复,只需要任意删掉其中一条
duplicates drop vid year,force //删除重复值
//drop if tag!=0
merge 1:m vid year using hh_data.dta
/*将主文件(村数据)根据 vid 和 year 与匹配文件(农户数据)
进行对应,一个村庄观察值将对应多个家庭观察值*/
keep if _merge==3
//保留成功匹配上的数据,1 表示仅来自主文件,2 表示仅来自子文件,3 代表被匹配上的观察值
drop _merge
save vill_hh.dta ,replace
******************检查数据******************
* 查看标识变量 isid unique duplicates
use hh_data,clear
isid pid year //方法一:运行结果为空表明标识变量唯一且不重复
unique pid year //方法二:显示非重复值个数
duplicates report pid year //方法三:显示标识变量的重复次数
duplicates list pid year //方法四:展示重复值
duplicates tag pid year, gen(tag1) //方法五:标记重复值
tabulate tag1
drop tag1
* 检查变量基本情况
describe //对所有变量进行展示
sum a1-a3 // sum 适用于数值型变量统计描述
* 格式转换
tostring a1,replace //将 a1 变量转换成字符型变量
browse
destring a1,replace //将字符型变量转换为数值型变量
tostring province,replace //将省代码转换为字符型变量
replace province="湖南" if province=="1"
replace province="山东" if province=="2"
list province in 1/10
encode province,gen(provid) //转换之后会自动生成与原文字对应的值标签
label list provid //label list可查看转换之后的数字文字对应表
**********************************************
*******************数据清理*******************
**********************************************
******************单变量清理******************
* 分类变量的清理和生成
* 举例1:a1 变量的清理
* 清理目标:检查 a1(性别)变量,查找并修改异常值,生成性别变量(虚拟变量)
use hh_data.dta,clear
describe a1 //检查变量标签
label var a1 "受访者的性别" //构建标签
des a1 //检查是否改对变量标签
label define a1lab 1"男" 2"女" //为 a1 变量定义一个值标签,命名为 a1lab
label values a1 a1lab //将值标签 a1lab 赋给变量 a1
label list a1lab //查看其值标签
tabulate a1,missing //查看变量的所有取值及频数,附加选项missing可以查看其缺失值数量(包括系统缺失值)
/*发现a1存在取值为1和2之外的观察值,这里用list列出取值为3的观察值进行查看,
并在生成新变量的基础上对异常值进行修改或设置为缺失值。*/
list pid a1 a2 a3 a4 a5 if a1==3 //查看这条异常值
assert (a1==1|a1==2) if !missing(a1)
//第二种检查方法,报告非法值,结果为空表示assert后所列条件为真
assert inlist(a1,1,2)
//和上面那条命令等价,inlist函数表示a1变量取值为1或者2则返回,否则为0
count if (a1!=1) & (a1!=2) & !missing(a1)
//第三种检查方法,列示出符合if条件后的样本值个数,相当于assert命令的逆操作
recode a1 ( 2=0 "女" ) ( 1=1 "男" )( 3=. ), gen (gender)
/*根据原始变量生成新变量,不要直接在原始变量上进行改动*/
label var gender "受访者的性别" //为新生成的变量附加标签
sum a1 gender //对更改结果进行查看,确保变量生成正确
* 连续变量的清理和生成
* 举例2:a2 变量的清理
* 清理目标:检查变量a2(出生年份),生成连续变量、有序变量
des a2
label var a2 "受访者的出生年份"
des a2
sum a2 if year==2001,detail //对连续变量进行查看,发现存在异常值2004
sum a2 if year==2021,detail
generate age=year-a2 if a2!=2004 //根据原始变量生成新的年龄变量(调查年份-出生年份)
sum a2 age //查看新生成的变量是否正确
recode age (5/17=1 "儿童组") (18/59=2 "成年组") (60/80=3 "老年组"), gen (agegroup) lab(labagegroup)
//根据age变量生成agegroup变量,并将值标签命名为labagegroup
label list labagegroup //查看值标签
sum age agegroup //检查变量是否生成正确
/*如果要把不同年龄段的人平分成不同的组,可以采用 cohort 命令或者 autocode 命令*/
sort age
egen cohort1=cut(age) if inrange(age,18,60), group(4) //将18-60岁的人平分成4个组
tab cohort1
replace cohort1=cohort1+1
tabstat age,by(cohort1) stat(min max mean n) //对不同组别受访者的年龄进行描述统计
save "hh_data_new",replace //清洗完的数据应该被保存在一份新的data文件中
* 缺失值、极端值的查验和处理
* 对于缺失值的查看
use "hh_data_new",clear
misstable pattern //列示缺失值的模式
misstable sum a4 //查看a4变量缺失值的基本统计
missings report a4 //对a4变量中缺失值的数量进行查看
missings list //列出所有变量中含有缺失值的变量
missings dropobs a1 a2 a3,force
/* 对a1,a2,a3都存在缺失值的样本值进行删除(若某一观察值对应的
所有变量取值都为缺失值,则将该条观察值从样本中进行删除。) */
missings dropvars a1 a2 a3 //若某一变量中所有取值都为缺失值,则删除该变量
/* 缺失值在stata中被当做最大值来保存,在计算变量的时候要格外注意这一点 */
* 缺失值的处理(仅作为参考)
/* 构造数据:两个县城(cid)三个村(vid) 2001 年 - 2020 年的销售量(b1)、
销售单价(b2)、总产量(b3)与种植面积(b4),假设种的是一种作物 */
clear
set seed 10000
set obs 60
gen vid=1
replace vid=2 in 21/40
replace vid=3 in 41/60
gen cid=1
replace cid=2 in 41/60
egen year=seq(),from(2001) to (2020)
gen b1=int(100*runiform())
gen b2=int(10*runiform())
recode b1(0=.)
recode b2(0=.)
gen b3=b1+20
gen b4=runiform()
replace b2=-3 in 5
replace b2=. in 26
replace b2=. in 45
replace b2=100 in 60
replace b1=. if b2==.
list vid cid year b1 b2 b3 b4 in 37/41 //查看数据
save "$Raw\sale_data",replace
* 单变量清理
sum b1 b2 b3
gen sale=b1
recode b2(-3=.),gen (price) //修改异常值,生成新变量
gen output=b3
sum b1 sale b2 price b3 output //对比新生成的变量和原变量
gen income_sale=sale*price //生成销售收入(销售量*价格)
list sale price output in 43/46
* 方法一:通过统计值进行推断
* 举例3:计算销售收入和总收入
gen newprice=price //在生成新变量的基础上进行补漏
foreach i in vid cid{
bysort `i':egen mean_`i'_price=mean(price) //按村庄/县城生成价格均值数据
bysort `i':egen sd_`i'_price=sd(price) //按村庄/县城生成价格标准差数据
replace newprice =. if (abs(newprice - mean_`i'_price)>3* sd_`i'_price) //对极端值的处理
replace newprice =mean_`i'_price if newprice==. & mean_`i'_price!=.
drop mean_`i'_price sd_`i'_price
label var newprice "销售价格(处理了极端值和缺失值)"
sum newprice price //将处理了异常值和进行了缺失值补漏的价格数据与原价格数据进行对比
gen income_total=newprice*output //生成总收入(总产量*价格)
* 方法二:插值补漏
sum b4
gen plantarea=b4
list vid year plantarea in 1/5 //查看前五个样本数据
drop in 23/25 //构造一份不完整的数据
list vid year plantarea in 22/25
xtset vid year
tsfill,full //根据标识变量对数据进行填充,补充成完整面板数据
list vid year plantarea in 22/25
list vid year plantarea if missing(plantarea) //查看缺失值
gen plantarea_new=plantarea //在新变量基础上进行补漏
bysort vid:ipolate plantarea year,gen(temp_plantarea) epolate
/* 使用 ipolate 时,第一年和最后一年的数据无法进行插补,
加epolate命令表示根据数据进行外推 */
replace plantarea_new=temp_plantarea if plantarea_new==. & !missing(temp_plantarea)
drop temp_plantarea
sum plantarea_new plantarea //补漏后进行查验对比
label var plantarea_new "种植面积(补漏后)"
* 方法三:采用周围非缺失值进行弥补
gen plantarea2=plantarea
by vid :replace plantarea2=plantarea[_n-1] if missing(plantarea2)
//其中两个缺失值的前一年取值也为缺失值
list vid year plantarea plantarea2 in 22/25
sum plantarea2 plantarea //补漏后进行查验*采用上一年非缺失值进行弥补
save "sale_data_reg",replace //完成数据清理,进行保存供分析所用
* 对于极端值的查验
/*如何发现极端值?一是通过画散点图或箱线图来识别,
二是通过描述统计进行判断*/
* 极端值的处理思路
/*对于极端值的处理上文有所提及,可以考虑遵循以下步骤进行处理:
一是查验极端值是否是因为数据输入错误造成的并进行相应更正。
二是考虑极端值的生成是否与研究主题有关,必要时可以删除存在极端值的样本
(在进行数据的删除时一定要慎重!)
三是可以通过取对数、缩尾(winsor2)等方法进行处理。
四是在对极端值进行处理前,可以先试着跑一下回归结果,
对比下处理与未处理极端值的回归结果。*/
* 发现极端值
* 举例4:查看和处理外出务工收入(a4)变量的极端值
use hh_data_new.dta,clear
sum a5,detail
gen outincome=a5
histogram outincome //第一种方法,画直方图查看变量是否存在左偏(有偏)的情况
graph box outincome //第二种方法,画箱线图,将展示数据的最大值最小值、上下四分位数、中位数
* 对极端值的处理
gen logincome=log(outincome) //取对数
hist logincome
winsor2 outincome, cuts(1 99)
/* 小于 1% 分位和大于 99% 分位的观察值分别被 1% 分位和 99% 分位上的观察值替代,
缩尾后的变量将以"_w"结尾命名 */
winsor2 outincome, suffix(_t) cuts(1 99) trim
/* 小于 1% 分位和大于 99% 分位的观察值将被替换为缺失值,
截尾后的变量以"_t”结尾命名 */
save hh_data_new,replace
*****************多变量清理******************
* 用分类变量检查分类变量
/*marriedornot 表示是否结过婚(0-1 变量),
marriednow 表示当下是否处于婚姻状态(0-1 变量)*/
clear
input marriedornot marriednow
tabulate marriednow marriedornot,missing
count if marriednow==1 & marriedornot==0
list marriednow marriedornot if marriednow==1 & marriedornot==0
* 用连续变量检查分类变量
* 举例5:用外出务工时长(a4)检查是否外出务工(a3)
use hh_data_new.dta,clear
des a3 a4
sum a3
gen outornot=a3
label var outornot "是否外出务工"
sum a4
gen outtime=a4
label var outtime "外出务工时长"
bysort outornot: sum outtime //根据 outornot 不同取值对 outtime 进行描述统计
sort pid year
list pid year relation age outornot outtime outincome if outornot==0 & !missing(outtime)>0
//找出这些不符合逻辑的观察值(未外出务工的受访者不应该有外出务工时长)
/*联合其他变量对异常值进行更改:发现第9个观察值存在外出务工时间和收入,故将此受访者的 outornot 更改为1*/
replace outornot=1 if pid==5 & year==2001
list pid year relation age outornot outtime outincome if outornot==0 & !missing(outtime)>0 //查看更改是否正确
/*另外,在有外出务工(outornot==1)的类别里,是否存在被访者外出务工时长(outtime)却为缺失值呢?*/
list pid year relation age outornot outtime outincome if outornot==1 & outtime==.
/*发现第 19 个观察值外出务工时长(outtime)为缺失值且不存在外出务工收入(outincome),
同时其年龄(age)为 8 岁,不太可能外出务工,故把 outornot 更改为 0,并把 outtime 改为 0*/
replace outornot=0 if pid==10 & year==2001
list pid year relation age outornot outtime outincome if outornot==1 & outtime==. //检查更改结果
/*第 7 个观察值外出务工时长(outtime)为缺失值且不存在外出务工收入(outincome),
但没有其他辅助信息,是否外出务工仍不能确定,可以选择将该观察值设为缺失值或者不进行处理*/
save "hh_data_new",replace
* 用连续变量检查连续变量 sum count assert
* 举例6:用村总人口数(c2)检查村劳动人口数(c1)
use "$Raw\village_data",clear
sum c1 c2
tab c1 //发现存在异常值99999
recode c1 (99999=.) ,gen(v_labor)
sum c1 v_labor //检查更改结果
label var v_labor "村庄劳动力数量"
gen v_pop=c2
label var v_pop "村庄总人口数"
count if v_labor>v_pop & !missing(v_labor) //村劳动人口不应超过村总人口数
assert v_labor<=v_pop if v_labor!=. //上一条命令的等价命令,运行结果为空表示为真
list vid year v_labor v_pop if (v_labor>v_pop) & !missing(v_labor) //列出不符合实际的数据
replace v_pop=v_labor if vid==2 & year==2021 //将劳动力人口数据更改为人口数据,或者设置为缺失值
list vid year v_labor v_pop if (v_labor>v_pop) & !missing(v_labor) //检查更改结果
save "village_data_new",replace
**********************************************
*****************综合变量生成*****************
**********************************************
* 举例7:检查户主是否唯一
use hh_data_new.dta,clear
browse fid pid year relation head
gen head=cond(relation==1,1,0)
//如果该条观察值是户主,head变量取值为1,否则取值为 0
/*cond是条件函数,如果符合第一个逗号前的判断条件,即返回第二个逗号前的值,否则返回最后一个值。*/
bysort fid year:egen headnum=sum(head) //计算每年每户的户主数量
tab headnum,m //取值为1表明一户有一个户主
/*对于没有户主家庭,指派成年男性为户主(还可以是指派成年女性或者被访问的第一人为户主等等)*/
gen relation2=relation
replace relation2=1 if headnum==0 & agegroup==2 & gender==1
/*对于有多位户主的家庭,指派年龄最小的成年男性为户主*/
bysort fid year:egen min_male_age=min(age) if (gender==1) & (agegroup==2)
browse fid pid year relation relation2 head headnum min_male_age age
//识别出一个家庭最小成年男性的年龄
replace relation2=. if (headnum==2) & (relation==1)
//将存在多个户主的家庭的关系变量设置为缺失值
replace relation2=1 if (headnum==2) & (age==min_male_age) & !missing(age)
//当成年男性受访者年龄为家庭最小时,被指派为户主
list fid pid year age relation2 relation headnum if headnum==0|headnum==2
//对修改后的关系变量relation2进行查看
* 举例8:综合变量生成-家庭18岁以上人口比例和抚养系数比
/* 抚养系数比指的是人口中非劳动年龄人口数与劳动年龄人口数之比,
这里定义非劳动年龄人口指14岁及以下和65岁及以上人口。*/
bysort fid year:gen hnum1=_N //计算每组中观察值个数,包括缺失值
bysort fid year:egen hnum2=count(pid) //计算每组中的非缺失值观察值个数
gen child=cond(age<=14,1,0) //如果受访者在14岁及以下,取值为1,否则取值为0
gen old=cond(age>=65,1,0)
gen adult=cond(age>14 & age<65,1,0)
gen adult18=cond(age>=18,1,0)
list fid pid year age child old adult adult18 in 1/4
foreach i in child old adult adult18 {
bysort fid year:egen n_`i'=sum(`i')
//分组计算每个家庭每年的 child 等人数
gen adult18_ratio=n_adult18/hnum2
gen dependency_ratio=(n_child+n_old)/n_adult
sum adult18_ratio dependency_ratio //检查生成的变量
*****************观测值组间计算-根据观测值分组******************
bysort gender: sum outincome //按性别查看收入变量
bysort gender:egen income_mean=mean(outincome) //按性别生成收入均值
//等价于egen income_mean=mean(outincome),by(gender)
bysort gender:egen income_max=max(outincome) //按性别生成收入最大值
bysort gender:egen income_min=min(outincome) //按性别生成收入最小值
bysort gender:egen income_sd=sd(outincome) //按性别生成收入标准差
bysort gender:egen income_sum=sum(outincome) //按性别生成加总值
bysort gender:egen income_total=sum(outincome) //按性别生成加总值
bysort gender:gen income_sum2=sum(outincome)
/*命令egen通过函数创建新变量,在egen命令前使用bysort选项,表明按照该变量进行排序并分组操作。*/
/*在egen命令后使用sum和total函数都能计算每个组别的加总值,并且计算时将缺失值自动视为0。*/
/*在使用sum函数时,采用egen命令和gen命令操作不同,前者是对组内所有观察值进行加总,而后者是进行累加。*/
sum outincome
gen income_standard=outincome-r(mean)/r(sd) //将income标准化
*****************观测值组内计算-变量分组******************
/* 按列进行计算一般不加 by (sort) var 选项,常用的选项包括生成行均值 rowmean、
行方差 rowsd、行最大值 rowmax、行最小值 rowmin、行中位数 rowmedian、行加总 rowtotal。 */
egen rowtotal=rowtotal(age a5) //仅作为举例,不考虑变量实际含义
gen plus=age+a5
list age a5 rowtotal plus in 1/10
/*直接对变量相加生成新的变量时,若为存在至少一个缺失值,
那么整个加总值都将为缺失值,而 rowtotal 将缺失值视 0 进行加总*/
/* rownomiss: 计算一组变量中非缺失值的数量
anycount: 查看变量列表中元素的个数
anymatch: 变量列表中若否存在某个元素返回1,否则返回0
anyvalue: 指定变量若存在某个元素则返回该元素值,否则返回缺失值
diff: 查看变量是否相等
group: 根据变量进行分组 */
egen female1=anymatch(gender),value(0) //性别变量若取值为 0 则返回 1,否则返回 0
egen female2=anyvalue(gender),value(0) //性别变量若取值为 0 则返回 0,否则生成缺失值
list pid gender female1 female2 in 9/14,sepby (gender)
**********************************************
***************数据清理收尾工作***************
**********************************************
keep fid year gender age adult18_ratio dependency_ratio //保存分析需用到的变量
order fid year gender age adult18_ratio dependency_ratio //给变量排序
* 提取家庭数据
collapse gender age adult18_ratio dependency_ratio,by(fid year)
label data "数据清理20210615" //给数据添加标签
save data_reg,replace //保存清洗过的数据,为分析所用
log close //关闭log文件
**********************************************
**************心得与学习资料推荐**************
**********************************************
* 两个注意
* 两个查看
* 数据清理是一个不断重复的过程
* 实践出真知
* 多用help,巧用搜索
* 不要等所有的菜都齐了才下锅
* CFPS中国家庭追踪调查官方网站
* 连享会及各公众号系列推文