SELECT first_name, last_name, date_of_birth
FROM employees
WHERE date_of_birth >= "1971-01-01"
AND date_of_birth <= "1971-01-09"
AND subsidiary_id = 27;
若要在这两列建立索引,根据之前"1.2 concatenated index"中的介绍,列的先后顺序会影响性能。
1)若索引顺序先date_of_birth,后subsidiary_id
先按date_of_birth 排序,若相同,则按subsidiary_id 排序。可以说subsidiary_id整体看是无序的,因此扫描范围是date_of_birth的范围。
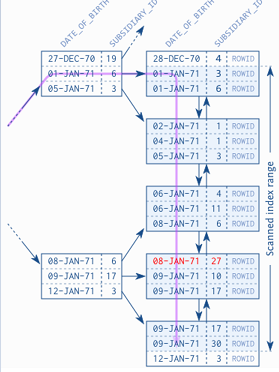
2)若索引顺序先subsidiary_id,后date_of_birth
subsidiary_id=1限制了索引第一索引是单值。在第一索引值相同情况下,第二列有序。"27 26-SEP-72"指针是小于26-SEP-72的,可以有;"27 26-SEP-72"的范围是26-SEP-72至26-SEP-72的,无需所有。搜索范围只有"27 26-SEP-72"的子page。从而只需扫描一个叶子节点即可。

经验:index for equality first—then for ranges.
3.2Indexing LIKE Filters
LIKE filters can only use the characters before the first wild card during tree traversal. The remaining characters are just filter predicates that do not narrow the scanned index range. A single LIKE expression can therefore contain two predicate types: (1) the part before the first wild card as an access predicate; (2) the other characters as a filter predicate.
LIKE过滤器只能在树遍历期间使用第一个通配符之前的字符。其余字符只是过滤谓词,不会缩小扫描索引范围。LIKE表达式可以包含两种谓词类型:(1)第一个通配符之前的部分作为访问谓词;[确定范围](2)其他字符作为过滤谓词。
所以,第一个通配符前的字符越明确,则扫描索引的范围越小,从而使索引更快。

是否区别大小写和collation有关。
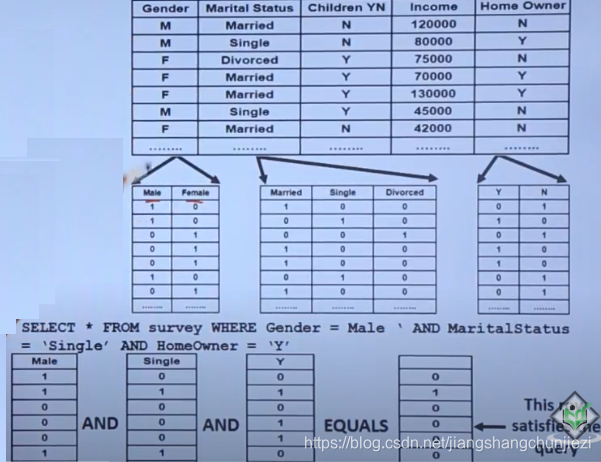
3.3 bitmap index(mysql不支持,oracle支持)
可以创建两个单独的索引,每列一个。然后,数据库先扫描两个索引,然后再合并结果。(需要大量的内存和CPU时间来组合中间结果)
在软件中经常会有将任意条件组合作为筛选的条件。如下图:

在实际中,不可能穷尽所有的筛选条件,即使可以成本太高。位图索引就是在单独列创建索引可以取得较好的性能。若事先知道查询,可以定制多列的联合查询,它比组合查询要快。
适用条件:①更新少或只读的表,因为维护位图会占用大量资源
②列是枚举类型,经常这些列组合查询
并发写必会造成死锁。
更详细例子
参考:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-join-types.
An index lookup requires three steps:(1) the tree traversal;(2) following the leaf node chain;(3) fetching the table data.The tree traversal is the only step that has an upper bound for the number...
不过这个恰好今天被我撞见了,一个慢查询把整个网站搞挂了
先看看这个SQL张撒样子:
# Query_time: 70.472013 Lock_time: 0.000078 Rows_sent: 7915203 Rows_examined: 15984089 Rows_affected: 0
# Bytes_sent: 1258414478
use js_sku;
SET timestamp=1465850117;
SELECT
ss_id, ss_sa_id, ss_si_id, ss_av_zid, s
MySQL死锁问题是很多程序员在项目开发中常遇到的问题,现就MySQL死锁及解决方法详解如下:
1、MySQL常用存储引擎的锁机制
MyISAM和MEMORY采用表级锁(table-level locking)
BDB采用页面锁(page-level locking)或表级锁,默认为页面锁
InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
2、各种锁特点
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高
页面锁:开销和加锁时间界于表锁和行锁之
索引无效原因
最近遇到一个Oracle SQL语句的性能问题,修改功能之前的运行时间平均为0.3s,可是添加新功能后,时间达到了4~5s。虽然几张表的数据量都比较大(都在百万级以上),但是也都有正确创建索引,不知道到底慢在了哪里,下面展开调查。
经过几次排除,把问题范围缩小在索引上,首先在确定索引本身没有问题的前提下,考虑索引有没有被使用到,那么新的问题来了,怎么知道指定索引是否被启用。
判断索引是否被执行
1. 分析索引
即将索引至于监控状态下,对索引进行分析。如下对 ID_TT_SHOHOU_HIST_002 索引进行分析
alter index ID_TT_SHOHOU_HIST_
对于排查问题找出性能瓶颈来说,容易发现并解决的问题是MYSQL的慢查询以及没有得用索引的查询。
=========================================================
方法一: 这个方法我正在用,呵呵,比较喜欢这种即时性的。
Mysql5.0以上的版本可以支持将执行比较慢的SQL语句记录下来。
mysql> show variables like 'long%'; 注:这个long_query_time是用来定义慢于多少秒的才算“慢查询”
+—————–+———–+
| Variable_name |
根据表主键id删除一条数据,在PL/SQL上执行commit后执行时间都大于5秒。!!!
问题分析:
需求是删除一个主表A,另有两个附表建有此表的主键ID的外键。删除A表的数据级联删除另两个表的关联数据。增删改查使用hibernate实现。
一开始一直以为是hibernate的内部处理上有关联操作导致的删除和更新数据缓慢。所以将原先使用hibernate的saveOrupdate方法,改查jdbc的
sql语句来处理update和delete数据操作。但是依然没效果!!!
怀疑数据库出问题了!~
于是拿sql语句在PL/SQL客户端执行,查看执行计划。删除和更新都能使用到索引
会经常发现开发人员查一下没用索引的语句或者没有limit n的语句,这些没语句会对数据库造成很大的影响,例如一个几千万条记录的大表要全部扫描,或者是不停的做filesort,对数据库和服务器造成io影响等。这是镜像库上面的情况。 而到了线上库,除了出现没有索引的语句,没有用limit的语句,还多了一个情况,mysql连接数过多的问题。说到这里,先来看看以前我们的监控做法 1. 部署zabbix等开源分布式监控系统,获取每天的数据库的io,cpu,连接数 2. 部署每周性能统计,包含数据增加量,iostat,vmstat,datasize的情况 3. Mysql slowlog收集,列出top
1. 无
索引、
索引失效导致
慢查询
如果在一张几千万数据的表中以一个没有
索引的列作为查询条件,大部分情况下查询会非常耗时,这种查询毫无疑问是一个
慢SQL查询。所以对于大数据量的查询,需要建立适合的
索引来优化查询。
虽然很多时候建立了
索引,但在一些特定的场景下,
索引还有可能会失效,所以
索引失效也是导致
慢查询的主要原因之一。
2. 锁等待
常用的存储引擎有 InnoDB 和 MyISAM,前者支持行锁和表锁,后者只支持表锁。
如果数据库操作是基于表锁实现的,试想下,如果一张订单表在更新时,需要锁住整张表,那么其它大量数据库操作(包括查询)都将处于等待状态,这将严重影响到系统的并发性能。
MySQL凭借着出色的性能、低廉的成本、丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库。虽然性能出色,但所谓“好马配好鞍”,如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如“精通MySQL”、“SQL语句优化”、“了解数据库原理”等要求。我们知道一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重。
本人从13年7月份起,一直在美团核心业务系统部做慢查询的优化工作,共计十余个系统,累计解决和积累了上百个慢查询案例。随着业务的复杂性提
MySQL凭借着出色的性能、低廉的成本、丰富的资源,已经成为绝大多数互联网公司的关系型数据库。虽然性能出色,但所谓“好马配好鞍”,如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如“精通MySQL”、“SQL语句优化”、“了解数据库原理”等要求。我们知道一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到多的,也是容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重。
本人从13年7月份起,一直在美团核心业务系统部做慢查询的优化工作,共计十余个系统,累计解决和积累了上百个慢查询案例。随着业务的复杂性提升
参看网址:https://www.elastic.co/guide/en/elasticsearch/reference/2.3/index-modules-slowlog.html
1、通过修改elasticsearch.yml来启用慢查询:
vim elasticsearch.yml
###Search Slow Log :查询慢日志配置,日志记录在以“_index_isearc



