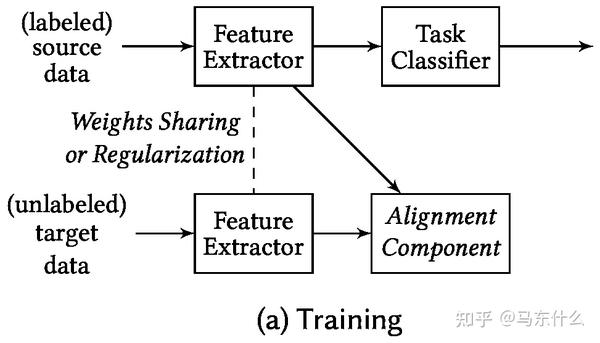
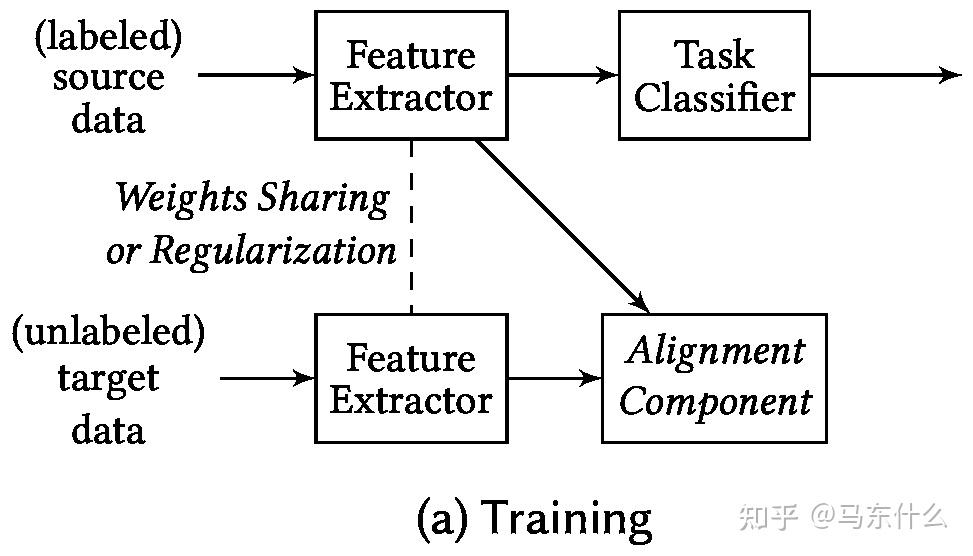
domain adaptation的一些记录

Awesome系列
Deep visual domain adaptation: A survey
找了半天,感觉就这篇survey讲的比较清晰有条理一点。
基础背景
可见这篇前面的部分
domain adaptation和transfer learning的关系
domain adaptation是transfer learning的一个分支, 他们一般被认为是transductive的 ,即将一个source domain adapt 到一个target domain之后,出现了新的target domain需要重新training一遍,而不像domain generalization一样具有可推广的能力。
What is domain shift?


domain adaptation主要关注的是输入空间X的shift 导致的domain shift,当然也有少量工作会关注y和P(y|x)的分布变化,不过主要的研究方向集中在X的shift上。
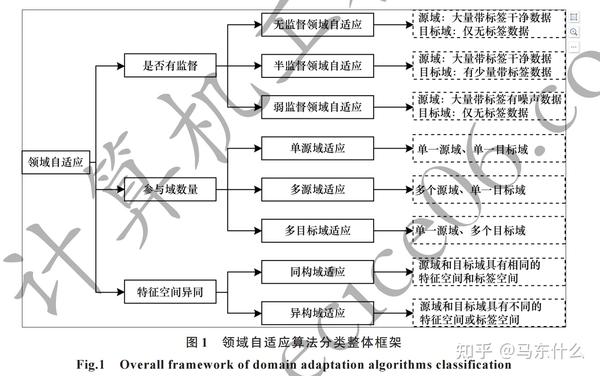
一个high level的划分
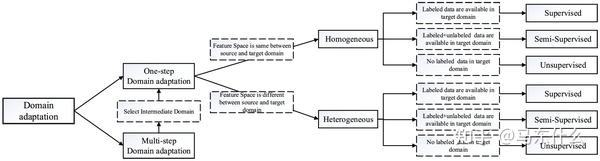
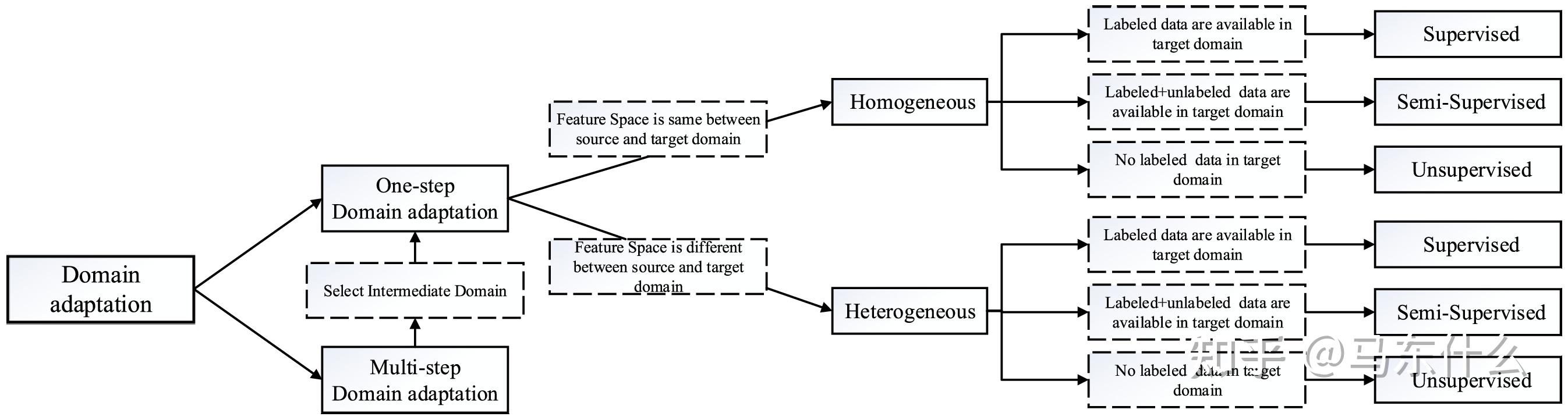
循序渐进。
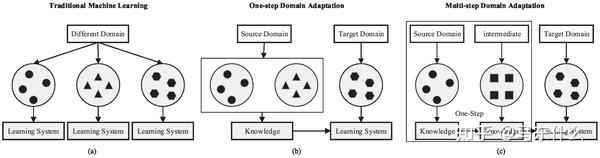
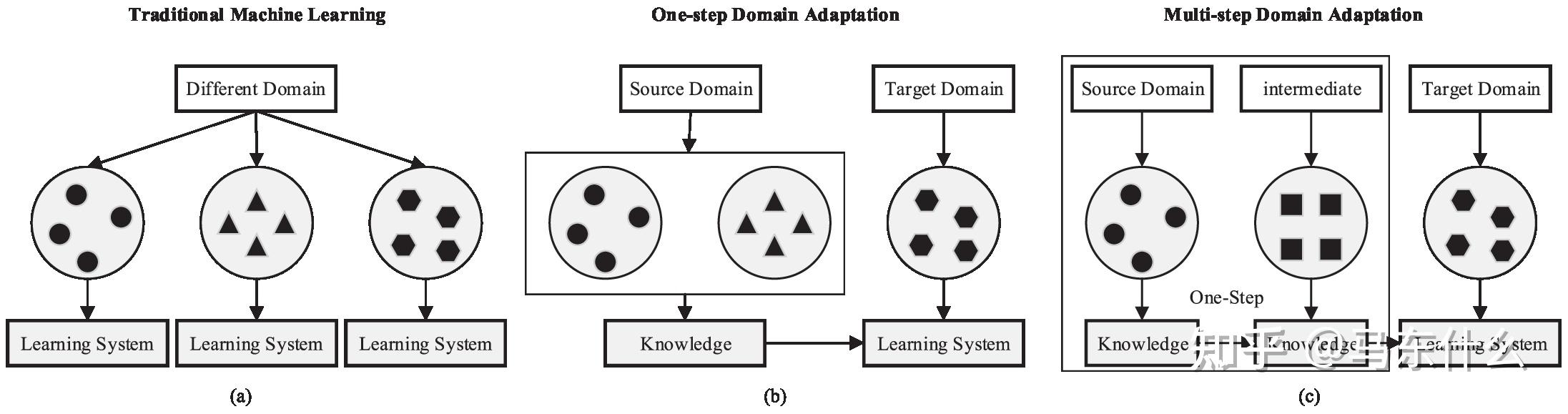
所有上述DA设置都假设源和目标域直接相关;因此,传递知识可以一步完成。我们称之为一步法DA。然而,实际上,这种假设有时是不可用的。两个域之间存在轻微的重叠,执行一步DA将无效。幸运的是,有一些中间域能够比原始距离更接近源和目标域。因此,我们使用一系列中间桥来连接两个看似不相关的域,然后通过这个桥执行一步DA,称为多步(或过渡)DA [24,25]。例如,由于不同的形状或其他方面,面部图像和车辆图像彼此不同,因此,一步DA将失败。然而,一些中间图像,例如“橄榄球头盔”,可以被引入作为中间领域并且具有平滑的知识转移。图3显示了一步法和多步骤DA技术的学习过程之间的差异。
1 source domain是多个还是单个,单个的话走onestep,多个的话走multi step
多步领域自适应(multistep domain adaptation)和单步领域自适应(onestep domain adaptation),
单步领域自适应指的是将一个源域和一个目标域之间的差异通过一个模型映射或转换到目标域中。这个方法通常涉及到训练一个模型,使用源域数据训练这个模型,然后再将其应用于目标域。这个方法比较简单,domain的过程是直接从source 到 target domain,但是实际应用中对于某些特殊的场景可能是不work的,即如果source domain和target domain之间存在很少的overlap,则one step的方法可能会GG。例如face image domain和car image domain彼此之间差异很大,因此,直接执行one step的DA很容易失败,但是通过一些特殊的中间的domain,即intermediate domain,例如橄榄球头盔domain,其可以作为中间的domain 来平滑source 到target的adapt的过程。(这个例子还真是挺奇怪的。。)
2 source domain和target domain的features是否同构
异构DA可能在tabular 上会比较常见,image的话,shape一般都是3维的张量,简单resize之后,feature matrix的大小很轻松就能保持相同,因此可能涉及到异构DA的情况比较少,tabular data的话,加入新features或者减少了部分老的features很容易导致source domain和target domain的feature space发生一定变化。
3 target domain的label情况
可以分为有监督,半监督和无监督的DA,无监督的DA是DA中比较多的research 方向,因为现实世界中,target
domain的label少设置没有的场景比较多一些;
一个low level的细分
由于onestep和multistep的差异主要在于中间是否引入intermediate domain来辅助 source 到 target domain的knowledge transfer,所以其实底层本质上还是从一个source 到 一个target domain的逻辑。
这里具体的domain adaptation的方法可以划分为。
(1)instantce-based的domain adaptation
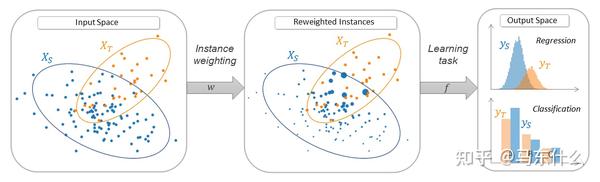

这类方法主要focus在为source domain的samples 找到一个合适的权重(重要性采样),简单来说,source domain中的sample如果和target domain中的data 越接近则sample weight 越大,许多经典的data shift的方法都是基于instance的方法,例如kliep,kmm,tradaboost等,样本选择本身也可以视为一种特殊的重要性采样方法;
这些基于样本的领域自适应方法的主要优势在于计算效率高、容易实现和解释。然而,它们通常需要足够的领域重叠以及有意义的样本级相似性度量。在实际应用中,基于样本的方法通常会与基于特征的方法(feature-based)和基于对抗性训练的方法(adversarial training-based)结合使用,以获得更好的领域自适应效果。
除此之外,在上一篇
里提到的 domain data augment 实际上也是可以作为一种instantce-based的方法来缓解domain adaptation的问题的 .和经典的重要性采样方法不同,data augment的目的主要在于产生新的和target domain分布类似的样本加入source domain的training过程中来,感觉这种方法可能会更好一点。
(2)feature-based的domain adaptation
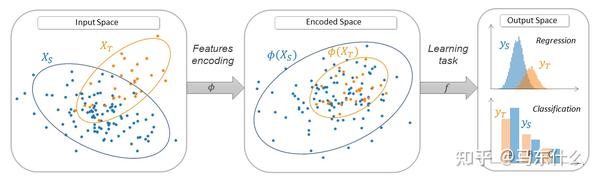
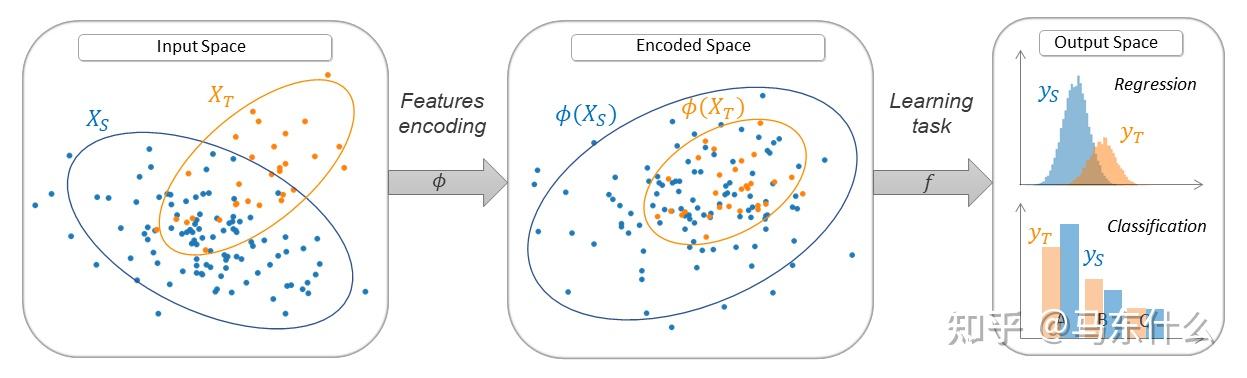
算是Deep DA领域的主要研究方向,大部分的DA的工作都是围绕feature based的方法展开的,这也是本文主要的论述方法(感觉很多DA的survey都写的严重不足,真裂开)
feature-based的方法抽象来看,就是
feature-based的方法可以进一步细分为
A. 基于差异的方法
整体的思路很简单,范式类似于metric learning,即我们使用feature extractor对source和target domain的input进行representations,然后将这两个representation之间进行比较,通过某种用于衡量分布差异的metric 进行对比,得到一个附加的loss function 然后去优化这个loss function即可。
那么这里用于衡量分布差异的metric的选择就比较重要了,有下面4种metric的大类划分:
分类标准 :使用类标签信息作为在不同领域之间传递知识的向导。当目标域的标记样本在监督DA中可用时,软标记和度量学习总是有效的。当这些样本不可用时,可以采用其他一些技术来替代类标记数据,如伪标签和属性表示。举个例子,假设我们有一个手写数字识别的任务,源域是 MNIST 数据集,目标域是 USPS 数据集。源域和目标域的图像在视觉风格上有差异,例如笔画粗细、背景等。我们的目标是利用源域的知识(包括标签)来提高目标域的分类性能。
在这个例子中,按照分类标准的metric,我们可以采用以下策略:
a) 软标签 :首先在源域上训练一个模型,然后用这个模型预测目标域的图像,得到每个图像的类别概率分布(即软标签)。接着,将这些软标签与source domain的真实标签结合起来,对模型进行微调,以提高目标域的分类性能。
b) 度量学习 :通过学习一个距离度量(例如欧氏距离或余弦相似度),使得同一类别的图像在特征空间中距离更近,不同类别的图像距离更远。这种方法可以在源域和目标域之间建立一个统一的特征空间,从而提高领域自适应性能。
需要注意的是,通过metric learning的方法(伪标签不需要)需要目标域数据有足够的标签,这是一个比较尴尬的问题,如果target domain有足够的label,实际上直接用target domain的数据train一个model的效果可能也ok,那么其实就没有必要使用source domain的data了,只能说当手头的数据更多的时候,可以都试试吧。一般domain adaptation应用的场景更多的是target domain没有标签的场景。
补充的一点是,在完成分类问题的时候,鼓励对softmax使用temperature使得其产生的预测结果平滑,从而保持不同class之间的相似的信息,这对于target domain的应用是被证明存在帮助的,因为例如数字识别的问题中,黑白图像的1和7之间的相似的概念在彩色图片的1和7之间也存在;
统计标准 :使用某些机制对齐源和目标域之间的 统计分布变化 。比较和减少分布偏移最常用的方法是最大平均差异(maximum mean差值,MMD),相关对齐(correlation alignment, CORAL), Kullback-Leibler (KL)散度和H散度等,即这里我们直接去优化某些衡量分布差异的统计指标,如果统计指标本身是可微的则直接优化,否则就需要选择一些近似的可微的function来优化了;
例如基于mmd的loss function的设计
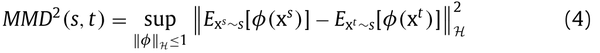
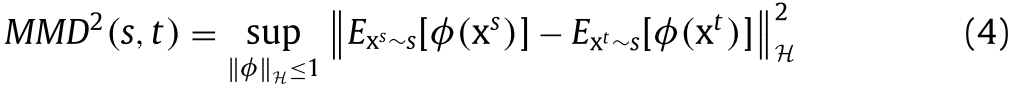

常见的统计标准有

结构标准 :目的是通过调整深度网络的结构来提高学习可迁移特征的能力。被证明具有良好效果的技术包括自适应批处理归一化(BN)、弱相关权重、领域引导的dropout等。
1 自适应批处理归一化(Adaptive Batch Normalization, BN): 批量归一化(Batch Normalization)是一种常用的技术,用于加速神经网络训练并降低梯度消失和梯度爆炸问题。它通过对每个批次的数据进行归一化,使特征分布保持稳定。在领域自适应中,可以使用自适应批量归一化来独立地对源域和目标域进行归一化,从而减小分布差异。例如,在训练过程中,可以为源域和目标域分别计算均值和方差,然后分别应用归一化操作。这有助于提高领域自适应性能。
2 弱相关权重: 弱相关权重的思想是减少神经网络不同层之间的参数相关性,以提高特征的可迁移性。在领域自适应任务中,可以通过在网络结构中添加正则化项来实现弱相关权重。例如,可以在损失函数中加入一个参数相关性惩罚项,以减小不同层之间参数的相关性。这种方法有助于训练出更具泛化能力的特征表示,从而提高领域自适应性能。
3 领域引导的 Dropout: Dropout 是一种常用的正则化技术,通过在训练过程中随机丢弃神经元来防止过拟合。在领域自适应中,可以使用领域引导的 Dropout 来针对不同的领域独立地应用 Dropout。具体地说,可以为源域和目标域分别设置不同的 Dropout 概率,从而在训练过程中独立地优化不同领域的特征表示。这有助于减小源域和目标域之间的分布差异,提高领域自适应性能。
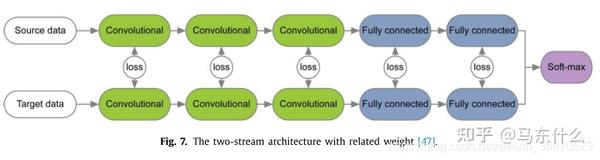
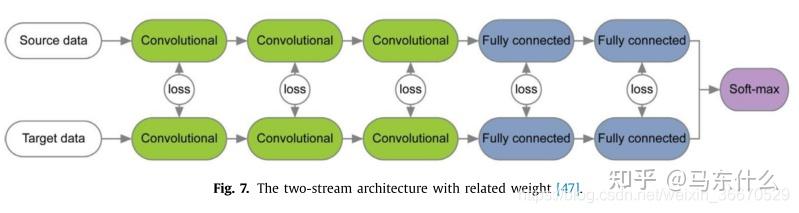
还有一些方法对网络结构进行优化,使分布差异最小化。这种适应行为可以在大多数深度DA模型中实现,比如监督和非监督设置。Rozantsev等人[47]认为对应层中的权重不共享,而是通过权重调节器r w(·)进行关联,以考虑两个域之间的差异(图7)。权值调节器
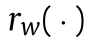
可以表示为指数损失函数:
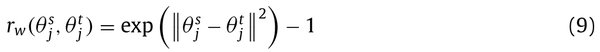

式中,
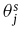
和
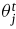
分别为源模型和目标模型的第j层参数。为了进一步放宽这一限制,它们允许一个流中的权重进行线性变换:
哎,好麻烦直接贴这篇翻译的地址好了
几何标准 :根据源域和目标域的几何特性建立连接。该判据假设几何结构之间的关系可以减小畴移。
几何标准通过对从源域到目标域的几何路径上的中间子空间进行积分,从而减轻了域的位移。构造了一个几何流曲线,将源域与目标域连接起来。源和目标子空间是格拉斯曼流形上的点。通过沿着测地线对固定的[86]或无限的[87]子空间进行采样,我们可以形成中间子空间,以帮助找到域之间的相关性。然后将源数据和目标数据投影到得到的中间子空间中,对分布进行对齐。受几何路径的中间表示的启发,Chopra等人[50]提出了一种称为深度学习的DA在域间插值(DLID)模型。DLID生成中间数据集,从所有源数据样本开始,逐步将源数据替换为目标数据。每个数据集是源和目标域之间插入路径上的单个点。一旦中间数据集被产生,一个使用预测稀疏分解的深层非线性特征提取器被训练在无监督的方式。
一些具体的工作
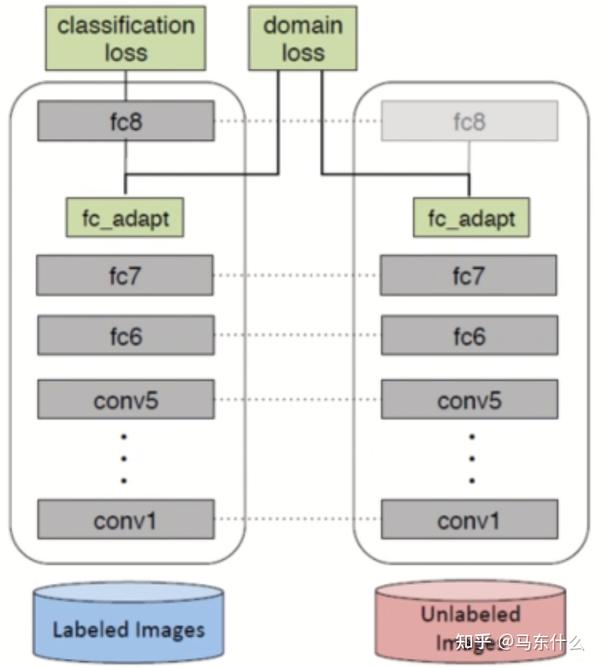

例如经典的用于无监督DA的DDC方法,它是使用MMD(Maximum Mean Discrepancy) ,即找一个核函数,将源域和目标域都映射到一个再生核的Hilbert空间上,在这个空间上取这个两个域数据分别作均值之后的差,然后将这个差作为距离。用这个方法训练网络的Loss是:
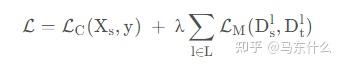
其中第一项就是源域之前的模型的Loss(比如分类任务就是分类Loss),然后第二项是在指定层l ll上的MMD距离之和,乘了个表示重要性的系数λ。在训练时有两个网络,一边是源域的,一边是目标域的,它们共享参数,然后在较深的某些层去计算MMD距离,然后按上面的公式那样加在一起作为整个模型的Loss。
DAN(ICML,2015) 就是用了多个核函数的线性组合,并且在多个层上计算MMD距离
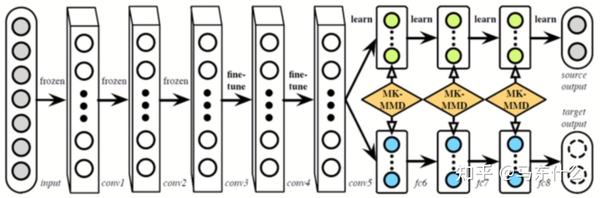
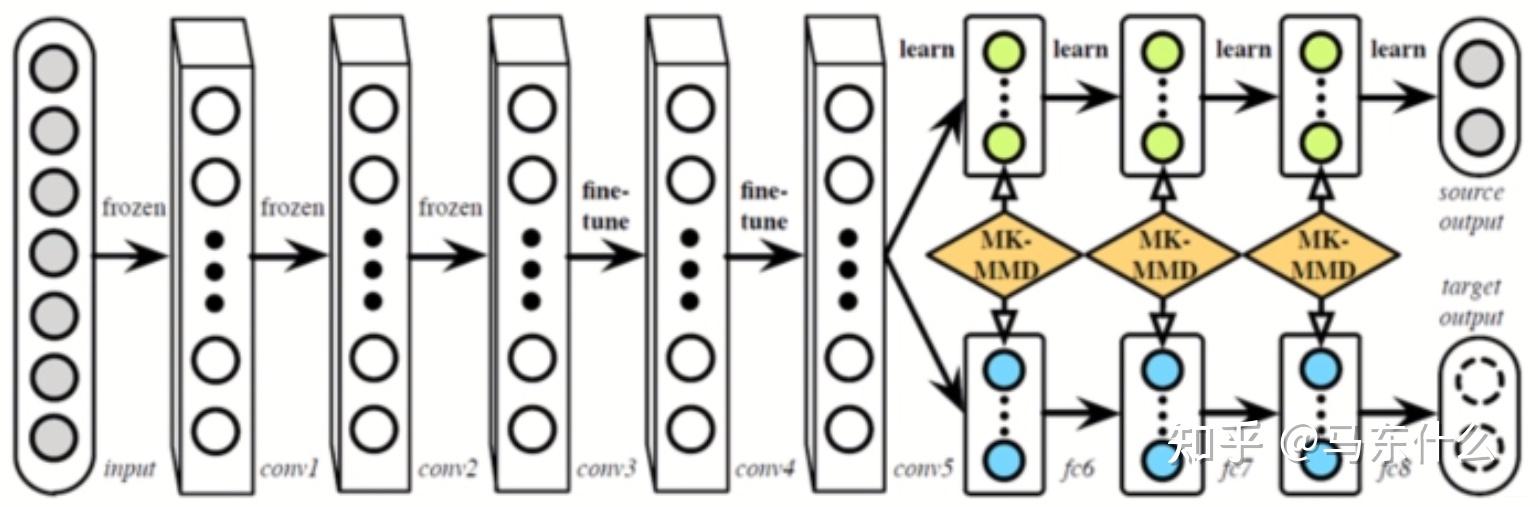
而 RTN(NIPS,2016) 前半部分还是DAN,但是光靠DAN特征未必能对齐的那么好,所以在之前直接接源域分类器的地方改成了一个残差结构,用来学习源域和目标域分类器的差异。


还有 JAN(arXiv,2016) 里提出了一个 JMMD(联合分布的MMD) ,通过优化这个JMMD能让源域和目标域特征和标签的联合分布更近,这样效果更好。
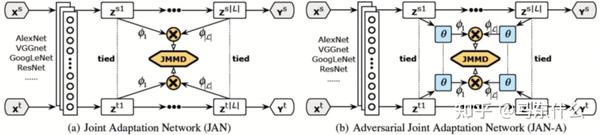

B. domain adversarial training
gan和domain adaptation结合的酷炫工作,灵活度要更高,基于gan的经典方法,例如daan和addn中,我们不需要去预定义一个用于评估分布差异的metric,分布差异的评估直接通过一个二分类的discriminator来做,早期在kaggle上的对抗验证就是基于这种思想,我们直接通过一个二分类器来判定train和test 的 data的分布是否相同。
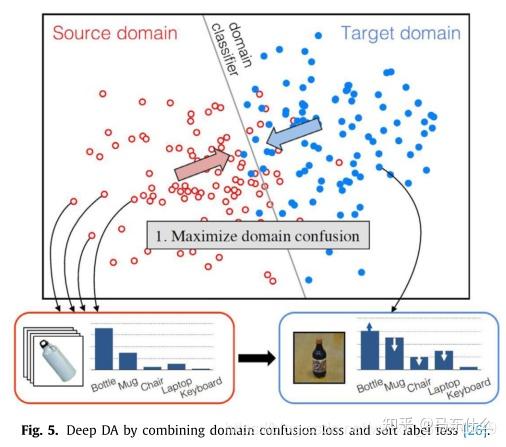
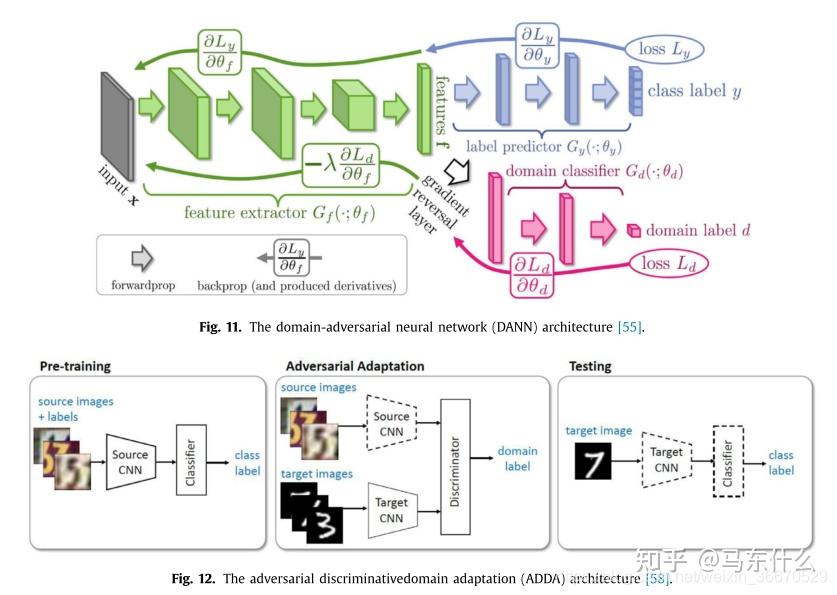
如RevGrad(ICML,2015) 的基本思路就是用GAN去让生成器生成特征,然后让判别器判别它是源域的还是目标域的特征,如果判别不出来就说明在这个特征空间里源域和目标域是一致的。
下图中绿色部分是一个特征提取器,源域和目标域数据都扔进去,它就是用来生成(或者叫提取)特征的,然后紫色部分是对源域数据的特征做分类的分类器,红色部分是对源域数据和目标域数据的特征做判别的判别器,这个判别器要不断增强(能很好的判别是源域的还是目标域的特征),同时生成器也要增强,让生成出来的特征能混淆判别器的判别,这样最后生成(提取)出的特征就是源域和目标域空间里一致的了。
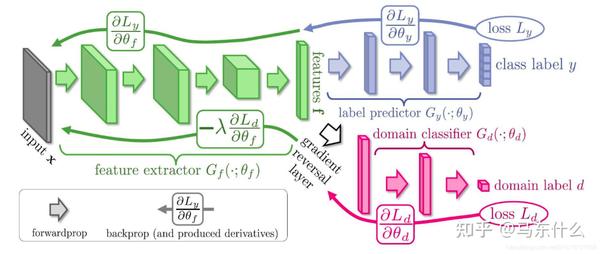

这个可以用GAN的最小化-最大化的思想去训练,也可以用论文中的梯度反转层(Gradient Reversal Layer) 的方法,就是在上图中白色空心箭头的位置加了个梯度反转层,在前向传播的过程中就是正常的网络,即最小化Loss让红色部分的判别器性能更好,再反向传播的过程中把梯度取负,即优化绿色部分的特征提取器,来尽量让红色部分的判别器分不清特征是源域的还是目标域的。这个方法就是一个训练技巧 。
对于它的改进有CAN(CVPR,2018),它把深度网络连续的若干层作为一个block,这样划分成几个block,然后对每个block加一个判别器。它提出希望在网络高层的block中的特征和域的信息无关,因为最后要得到的就是不区分源域和目标域数据的网络;而希望在网络的低层的block中的特征和域的信息有关,因为底层在提取边缘信息,希望这些边缘信息能更好提取目标域的特征。
还有MADA(AAAI,2018)。之前的方法都是源域和目标域的类别都是相同的这些,但是有时候源域和目标域类别不一定相同,比如目标域类别可以是源域类别的子集。这个方法就是提出不应该是域到域的对齐,而是应该精细到类别到类别的对齐。这种方式就是只在最后一层用判别器,但是对于每个类别都单独使用一个判别器,这种就是引入语义信息(类别信息)的对齐,能让特征空间对齐的更好。但是因为在无监督的DA里目标域样本没有标签,所以这里要用源域分类器去对目标域样本输出属于每个类的概率,属于哪个类的概率更大就让那个类的判别器发挥更大的作用。这种方法就是相当于在RevGrad上补充了5中基于实例的自适应方法。
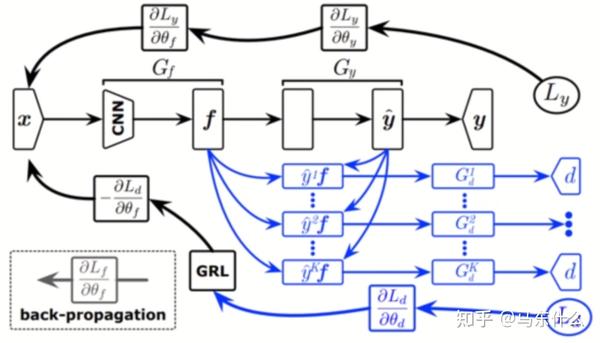

domain adversarial training是一个非常好的领域,因为一方面要对gan的training有足够的经验,一方面又要能够将gan应用到domain的对齐上,可谓是一次性玩两个领域的东西,收获大大的。
这里也有两个思路
(1)生成模型:
带有ground truth注释的合成目标数据是解决缺乏训练数据问题的一个很有吸引力的选择。首先,在源数据的帮助下, 生成器呈现无限数量的合成目标数据 ,这些目标数据与合成源数据配对共享标签,或者看起来好像它们是在维护标签时从目标域采样的。 然后,使用带标签的合成数据来训练目标模型,就像不需要DA一样 。具有生成模型的基于对抗性的方法能够以一种基于GAN的无监督方式学习这种转换。CoGAN的核心思想是生成与合成源数据配对的合成目标数据(如下图)。
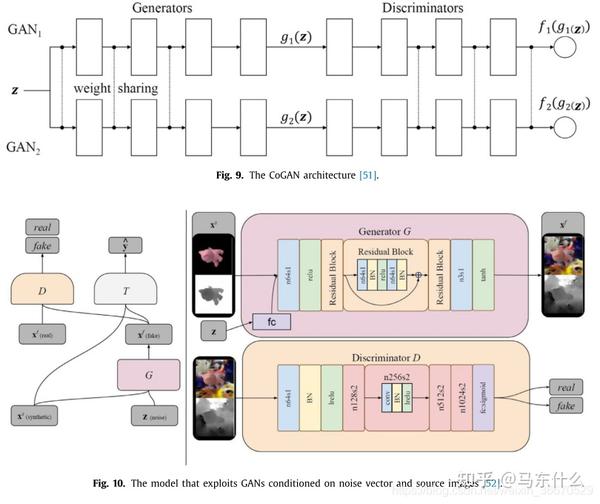

它由一对GANs组成:用于生成源数据的GAN 1和用于生成目标数据的GAN 2。生成模型中前几层的权重与判别模型中最后几层的权重是绑定的。这种权重共享约束允许CoGAN在没有对应监督的情况下实现域不变特征空间。经过训练的CoGAN可以将输入的噪声向量调整到来自两个分布的成对图像上,并共享标签。因此,可以利用合成目标样本的共享标签来训练目标模型。
更多的工作集中在生成与目标数据相似的合成数据,同时利用到source domain中的标签。Yoo等人利用GANs将源域的知识转移到像素级目标图像。一个域鉴别器保证了内容对源域的不变性,一个真/假鉴别器监督生成器产生与目标域相似的图像。Shrivastava等人开发了一种用于模拟+无监督(S + U)学习的方法,该方法结合了最小化对抗性损失和自正则化损失的目标,其目标是使用未标记的真实数据提高合成图像的真实性。与其它工作中只对噪声矢量或源图像设置条件的生成器不同,Bousmalis等人提出了一种利用对噪声矢量或源图像均设置条件的GANs的模型(图10)。训练分类器预测源图像和合成图像的类标签,训练鉴别器预测目标图像和合成图像的领域标签。此外,为了期望从相同的源图像得到具有相似前景和不同背景的合成图像,使用内容相似性来惩罚源和合成图像之间的巨大差异,仅通过一个掩蔽的双均方误差。网络的目标是通过求解优化问题来学习G, D, T:
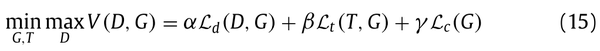



大体的思路就是用gan的结构来生成目标域的样本,有点类似于前面提到的instance-based里的domain data augment,只不过这里是通过model来产生增强图片的
(2)非生成式模型:
不是产生新样本,而是直接generator 作为 feature extractor 产生input的表示,discriminator 用于鉴别source和target domain的这个表示是否是容易鉴别的;
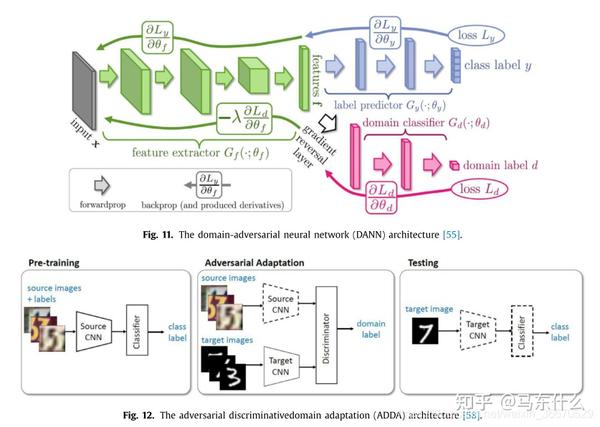
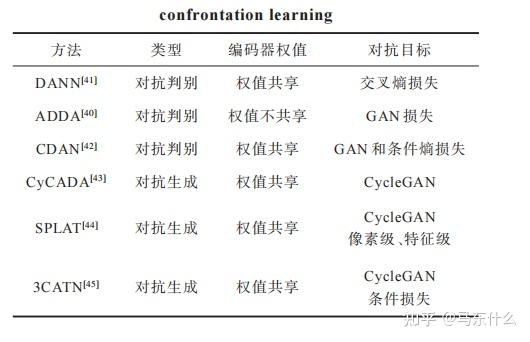
深度数据挖掘的关键是从源样本和目标样本中学习领域不变表示。有了这些表示,两个域的分布可以足够相似,即使分类器是在源样本上训练的,也可以被愚弄并直接用于目标域。因此,表示形式是否混乱是知识传递的关键。受GAN的启发,引入鉴频器产生的域混淆损失,以提高无发生器深度DA的性能。领域对抗性神经网络(DANN)将一个梯度反转层(GRL)集成到标准架构中,以确保两个领域上的特征分布相似(图11)。该网络由共享特征提取层和两个分类器组成。DANN通过使用GRL将域混淆损失最大化,同时最小化域混淆损失(对于所有样本)和标签预测损失(对于源样本)。与上述方法相比,ADDA通过解权值考虑了独立的源和目标映射,目标模型的参数由预先训练好的源初始化(图12)。这更加灵活,因为可以学习更多特定于领域的特性提取。ADDA通过迭代最小化以下函数来最小化源和目标表示距离,这与最初的GAN最相似:
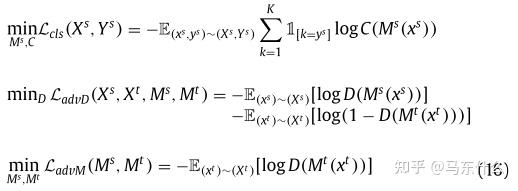
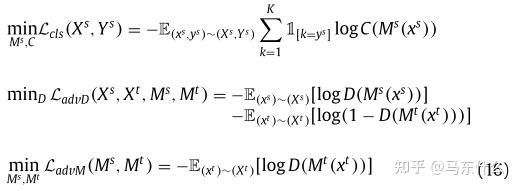


Tzeng等人提出增加一个执行二进制域分类的域分类层,并设计了一个域混淆损失,以鼓励其预测尽可能接近二进制标签上的均匀分布。与以往匹配整个源和目标域的方法不同,Cao等人引入了选择性对敌网络(SAN)来解决大域到小域的部分转移学习,该方法假设目标标签空间是源标签空间的一个子空间。同时通过滤除离群源类来避免负转移,通过将域鉴别器分割成多个逐类域鉴别器来匹配共享标签空间中的数据分布,从而促进正转移。Motiian等人对域标签和类标签进行编码,生成四组对,并将典型的二值对抗性鉴别器替换为四类鉴别器。Volpi等训练了一个特征生成器(S)在源特征空间中进行数据增强,并通过对S中的特征进行极大极小博弈得到了一个域不变量特征。受Wasserstein GAN的启发,Shen等人利用判别器估计源样本与目标样本之间的经验Wasserstein距离,并优化特征提取器网络以对抗的方式使距离最小。在[97]中,我们将两个分类器作为鉴别器,训练它们最大化差异来检测源支持范围之外的目标样本,而训练一个特征提取器通过在支持范围附近生成目标特征来最小化差异。
一些相关的工作

C 基于重构的方法
自编码器重构 :
通过使用自编码器,重构方法将用于表示学习的编码器网络与用于数据重构的解码器网络结合起来。
自编码器的基本框架是一个前馈神经网络,包括编码和解码过程。自动编码器首先将输入编码为一些隐藏的表示,然后将这个隐藏的表示解码为重建的版本。基于编码器-解码器重构的DA方法通常通过共享编码器学习域不变表示,并通过在源和目标域中丢失重构来维护域特殊表示。Glorot等人提出了基于堆叠去噪自动编码器(SDA)提取高级表示。通过在同一网络中重构各域数据的并集,高级表示可以同时表示源域和目标域数据。因此,在源域标记数据上训练的线性分类器可以用这些表示对目标域数据进行预测。尽管它们取得了显著的结果,但SDAs受到其高计算成本和缺乏高维特性的可伸缩性的限制。为了解决这些关键的限制,Tsai和Chien提出了边缘化SDA (mSDA),它通过线性去噪来边缘化噪声;因此,参数可以以封闭形式计算,而不需要随机梯度下降。[60]中提出的深度重构分类网络(DRCN)学习一种共享的编码表示,该表示为跨域目标识别提供了有用的信息(图13)。DRCN是一种CNN架构,它结合了两个管道和一个共享编码器。在编码器提供一个表示之后,第一个管道(即CNN)使用源标签进行监督分类,而第二个管道(即反卷积网络)使用目标数据进行非监督重建。



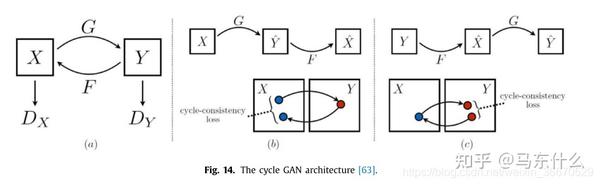
对抗式重构 :重构误差是通过GAN鉴别器得到的循环映射来测量每个图像域内重构图像与原始图像的差值,如dual GAN[62]、cycle GAN和disco GAN
首先由He等人提出,用于减少自然语言处理中对标记数据的要求。双元学习训练了两个“对立”的语言翻译者,如A到B和B到A。两个翻译者代表一个原对偶对,评估翻译的句子属于目标语言的可能性有多大,而闭环则衡量重构的句子与原译文之间的差异。受对偶学习的启发,利用对偶甘斯算法在深度数据挖掘中采用对偶重构。Zhu等人提出了一种循环GAN,在没有任何成对训练示例的情况下,可以将一个图像域的特征转换为另一个图像域(图14)。与对偶学习相比,cycle GAN使用了两个生成器而不是翻译器,它们学习映射G: X→Y和逆映射F: Y→X。两个鉴别器,D D X和Y,衡量实际生成的图像(G (X)≈Y或G (Y)≈X)由一个敌对的损失和原始的输入是如何重建后的序列两代(F (G (X))≈X或G (F (Y))≈Y)通过一个周期的一致性损失(损失重建)。因此,G (X)(或F (Y))的图像分布与Y(或X)的分布是不可区分的。
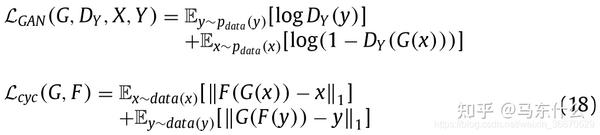




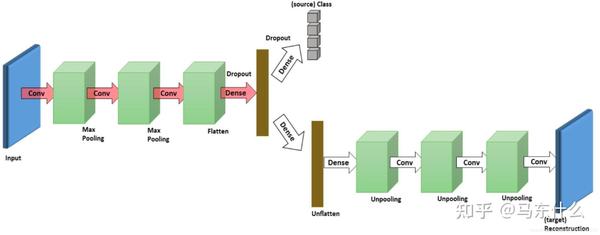
DRCN(2016,ECCV) 如下图结构 ,左侧是一个Encoder,也是将源域和目标域样本都扔进去生成特征用的,然后对于源域特征用一个分类器去分类,这样使得Encoder生成的特征能够很好的区分源域的样本(即是一个比较好的特征),对于目标域特征用一个Decoder去解码,使得能尽量还原目标域的样本。这样下来生成的特征所在的特征空间在源域和目标域样本上比较近。

(3) parameter-based的domain adaptation
这种基本上范式和finetune类似了,finetune本身也可以视为一种简单的parameter-based的domain adaptation方法。
基于参数的(Parameter-based)领域自适应方法主要关注调整模型参数,以便在源域和目标域之间共享知识。这些方法通常在训练过程中调整模型权重或使用正则化策略来提高模型在目标领域的泛化能力。
比如bert pretrain之后的finetune就是经典的做法了~
(4) 混合方法
为了获得更好的性能,一些上述方法被同时使用。Tzeng等人结合了域混淆损失和软标签损失,而使用了统计量(MMD)和架构标准(残差函数适应分类器)来进行无监督DA。Yan等将伪标签分配的类特异性辅助权重引入到原始MMD中。在DSN, encoder-decoder重建方法单独表示到私有和共享表示,虽然多准则或域混乱有助于使共享表示类似的损失和软子空间正交约束确保私有和共享表征之间的不同。Rozantsev等人使用了学习源和目标表示之间的MMD,并允许相应层的权重不同。Zhuang等人学习了通过编码器-解码器重构方法和KL散度的域不变表示。
其它的不感兴趣了,感谢这位大佬写的翻译,省了我好多时间~
中文综述