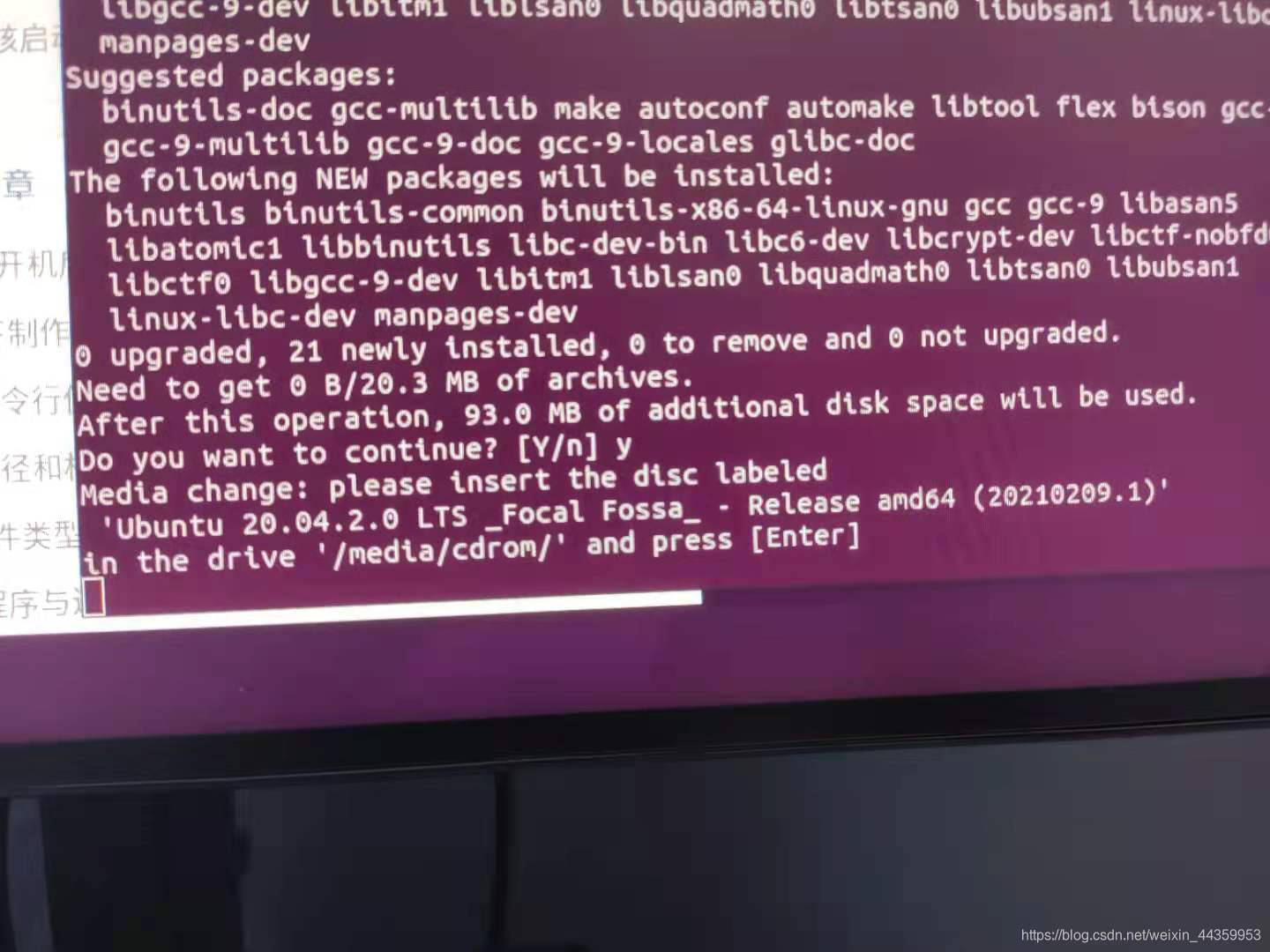
看完教程,其实貌似用deb安装方式更好,因为后面验证是否安装成功的教程感觉是基于deb安装方式才有的,换句话说,tar安装方式你不知道如何去验证安装成功了没,,,。
https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing-pip
至此大功告成!
当然以上是基于deb包的安装方式,第一步deb安装好了c++ 第二步安装对于python tensorrt的支持
网上搜到的:
1、使用TensorRT生成.engine文件时报错:
TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.0
问题原因:CUDA版本不对
解决,重新安装对应版本。
我遇到的只是警告:
[W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.4.1
估计是装的时候,cuda和tnesorrt还是对应上了的,只是不是最佳的对应所以有这么个警告
网上搜到的:
2、本机GPU为gtx 960M,目标机器GPU为P2000,程序在目标机器运行报错:
[E] [TRT] …/rtSafe/coreReadArchive.cpp (41) - Serialization Error in verifyHeader: 0 (Version tag does not match)
问题原因:猜测是显卡类型不一致导致目标机无法反序列化.engine文件
解决:在目标机器上编译生成.engine文件
我遇到的:转换文件是在rtx3080ti,tensorrt是8.0.1.6-1+cuda11.3 用在nx上跑,结果报错如下:
[TensorRT] ERROR: coreReadArchive.cpp (38) - Serialization Error in verifyHeader: 0 (Version tag does not match)
[TensorRT] ERROR: INVALID_STATE: std::exception
[TensorRT] ERROR: INVALID_CONFIG: Deserialize the cuda engine failed.
官网解决方案是升级到tensorrt版本一致最好,我打算升级到一致试一试,如果不行就尴尬了,可能还真跟设备扯上关系就只能在目标设备编译生成engine文件了。
测试结果,最后板卡和服务器的tensorrt环境一致了,结果报错:
[TensorRT] ERROR: 6: The engine plan file is generated on an incompatible device, expecting compute 7.2 got compute 8.6, please rebuild.
最后查资料:
https://111qqz.com/2020/03/tensorrt-model-compatibility-notes/
https://forums.developer.nvidia.com/t/problem-loading-trt-engine-plan-on-another-machine/68592
Engine plan 的兼容性依赖于GPU的compute capability 和 TensorRT 版本, 不依赖于CUDA和CUDNN版本.
简单来说,在使用同样TensorRT版本的前提下,在具有相同compute capability 的GPU上的模型是可以通用的.
但是cuda版本是依赖于GPU的compute capability的. 也就是比较新的GPU(对应较高的compute capability)无法使用低版本的cuda.
tensorrt 的序列化和反序列化操作只能在特定硬件上做,两个操作最好在同一硬件,至于compute capability一致的硬件行不行我也没试过,,,
哎愁啊
git clone https://github.com/jkjung-avt/tensorrt_demos.git
在环境配置好的基础上,50、ubuntu18.04/20.04进行TensorRT环境搭建和YOLO5部署(含安装vulkan)_sxj731533730-CSDN博客
(1)将库文件
/home/ubuntu/NVIDIA_CUDA-11.1_Samples/TensorRT-7.2.2.3/li
1.TensorRT内存泄漏问题
最近遇到一个bug,TensorRT4.0.4没有办法进行内存释放,这个官网也有提到,大意就是调用destory函数(内存销毁的函数),一片内存会被释放两次,然后代码就崩溃了.这个参考文献在这里:
(注意:bug产生的条件就是不停调用TensorRT,对其进行初始化,初始化结束后再销毁,反复操作,就能看到相应的内存泄漏)
问题描述:error tensorR...
yolov5_tensorrt_int8
tensorrtx
[TensorRT int8 量化部署 yolov5s 5.0 模型](https://www.cnblogs.com/KdeS/p/15119831.html)
Tensorrt环境安装及yolov5模型转换以及量化部署INT8
二、重要说明
github源码: tensorrtx
三、可能出现的问题
dnn未安装
/home/yichao/MyDocuments/tensorrtx/yolov5/calibrator.c
构建YOLOV5s模型,并试图使用trt推理服务上,出现错误
[TensorRT] ERROR: ../rtSafe/coreReadArchive.cpp (38) - Serialization Error in verifyHeader: 0 (Version tag does not match)
[TensorRT] ERROR: INVALID_STATE: std::exception
[TensorRT] ERROR: IN
反序列化模型的时候遇到以下提示问题:
Serialization Error in nvinfer1::rt::CoreReadArchive::verifyHeader: 0 (Magic tag does not match)
原因:模型是在TensorRT5上面序列化得到的,但是目前项目我切换到了TensorRT7,因此用TensorRT7的代码试图去加载TensorRT5的序列化得到的模型就会出现以上错误
在启动triton inference server的时候报
I0701 02:42:42.028366 1 cuda_memory_manager.cc:103] CUDA memory pool is created on device 0 with size 67108864
I0701 02:42:42.031240 1 model_repository_manager.cc:1065] loading: resnet152:1
E0701 02:43:00.935893 1 loggin
1.碰到如下报错:
[TensorRT] ERROR: INVALID_CONFIG: The engine plan file is generated on an incompatible device, expecting compute 7.5 got compute 8.6, please rebuild.
[TensorRT] ERROR: engine.cpp (1646) - Serialization Error in deserialize: 0 (Core engine deseri
给tensorrt写插件的时候,报错:
interpolate.cpp:63:93: error: invalid new-expression of abstract class type ‘torch2trt::InterpolatePlugin’
因为还有父类的虚函数没有实现。
可以通过一个简单的类实现进行测试,所有的函数不需要实现,这样看有哪些虚函数。比如:
class InterpolatePlugin : public IPluginV2
public:
您好,我可以回答这个问题。要在 Ubuntu 20.04 上安装 CUDA 和 cuDNN,您需要按照以下步骤进行操作:
1. 下载 CUDA 和 cuDNN 的安装包,并解压缩到您想要安装的目录中。
2. 安装 CUDA,运行安装程序并按照提示进行操作。
3. 安装 cuDNN,将解压缩后的文件复制到 CUDA 安装目录中,并按照 cuDNN 安装指南进行操作。
4. 配置环境变量,将 CUDA 和 cuDNN 的路径添加到 PATH 和 LD_LIBRARY_PATH 环境变量中。
完成以上步骤后,您就可以在 Ubuntu 20.04 上使用 CUDA 和 cuDNN 了。希望这个回答对您有帮助。