


理解图的拉普拉斯矩阵

对机器学习数学知识的系统讲解可以阅读 《机器学习的数学》 ,人民邮电出版社, 雷明
理解图的拉普拉斯矩阵
SIGAI
2021.04.05
谱图理论是图论与线性代数相结合的产物,它通过分析图的某些矩阵的特征值与特征向量而研究图的性质。拉普拉斯矩阵是谱图理论中的核心与基本概念,在机器学习与深度学习中有重要的应用。包括但不仅限于:流形学习数据降维算法中的拉普拉斯特征映射、局部保持投影,无监督学习中的谱聚类算法,半监督学习中基于图的算法,以及目前炙手可热的图神经网络等。还有在图像处理、计算机图形学以及其他工程领域应用广泛的图切割问题。理解拉普拉斯矩阵的定义与性质是掌握这些算法的基础。在今天的文章中,我们将系统地介绍拉普拉斯矩阵的来龙去脉。
拉普拉斯算子
理解图的拉普拉斯矩阵,要从微积分中的拉普拉斯算子说起。多元函数
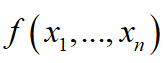
的拉普拉斯算子是所有自变量的非混合二阶偏导数之和
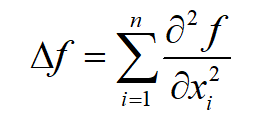
例如对于三元函数 f(x,y,z)
,其拉普拉斯算子为
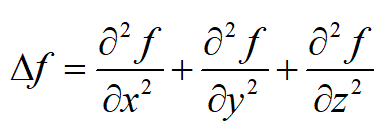
很多时候我们之只能近似计算导数值,称为数值微分。如果 \Delta x 的值接近于0,则在 x 点处
的导数可以用下面的公式近似计算
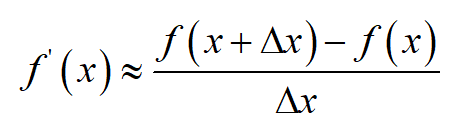
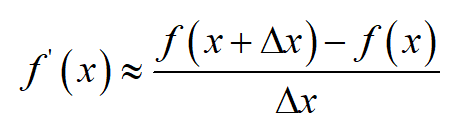
称为单侧差分公式。对于二阶导数,有
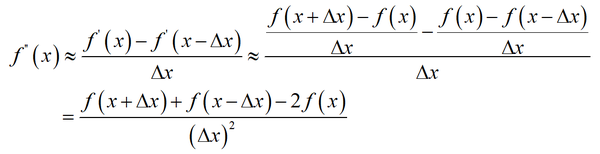
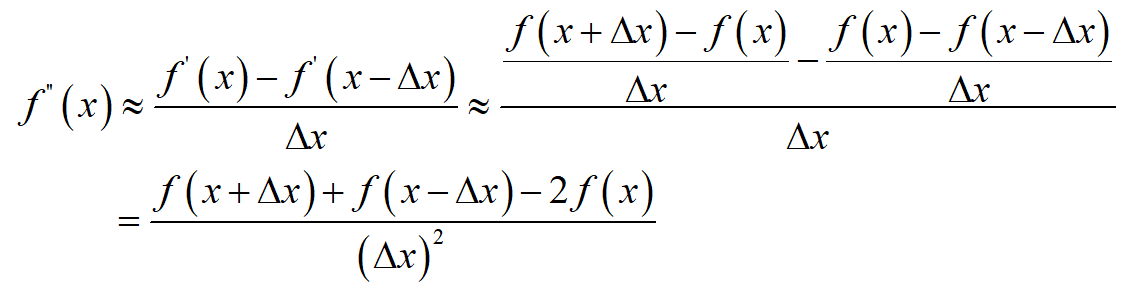
下面考虑多元函数的偏导数。对于二元函数 f(x,y) ,其拉普拉斯算子可以用下面的公式近似计算
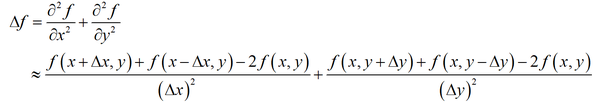
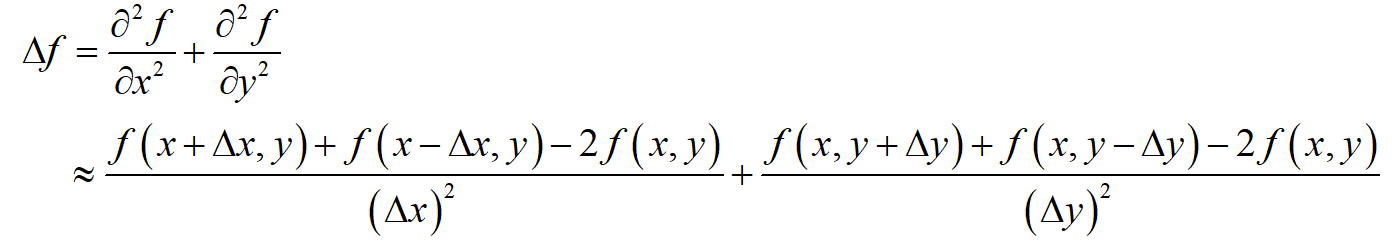
如果上面的二元函数进行离散化,对自变量的一系列点处的函数值进行采样,得到下面一系列点处的函数值,构成一个矩阵
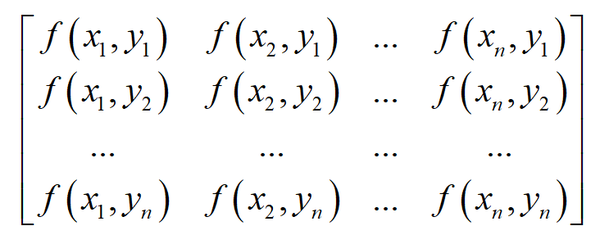
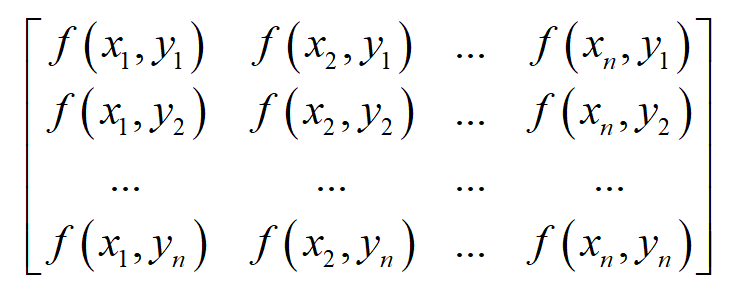
在这里 x 为水平方向, y 为垂直方向。为了简化,假设 x 和 y 的增量即步长全为1,即
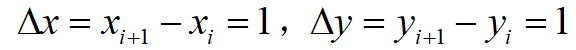
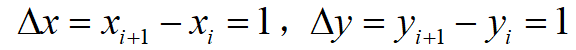
。则点 (x_{i},y_{j}) 处的拉普拉斯算子可以用下面的公式近似计算
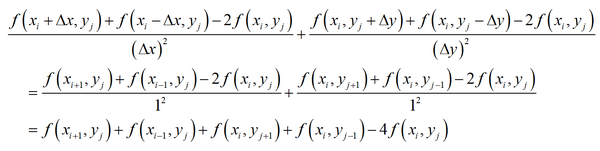
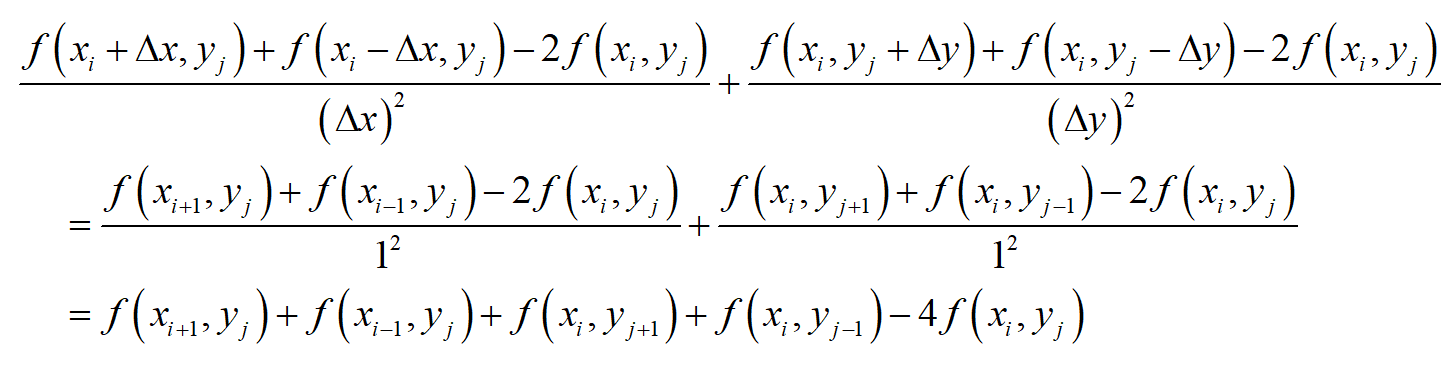
这是一个非常优美的结果,它就是 (x_{i},y_{j}) 的4个相邻点处的函数值之和与 (x_{i},y_{j}) 点处的函数值乘以4后的差值。如下图所示
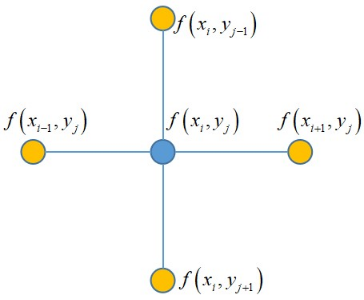
基于这种表示,拉普拉斯算子的计算公式可以写成
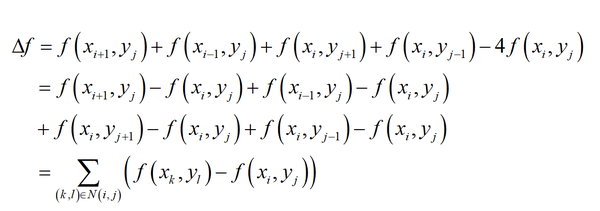
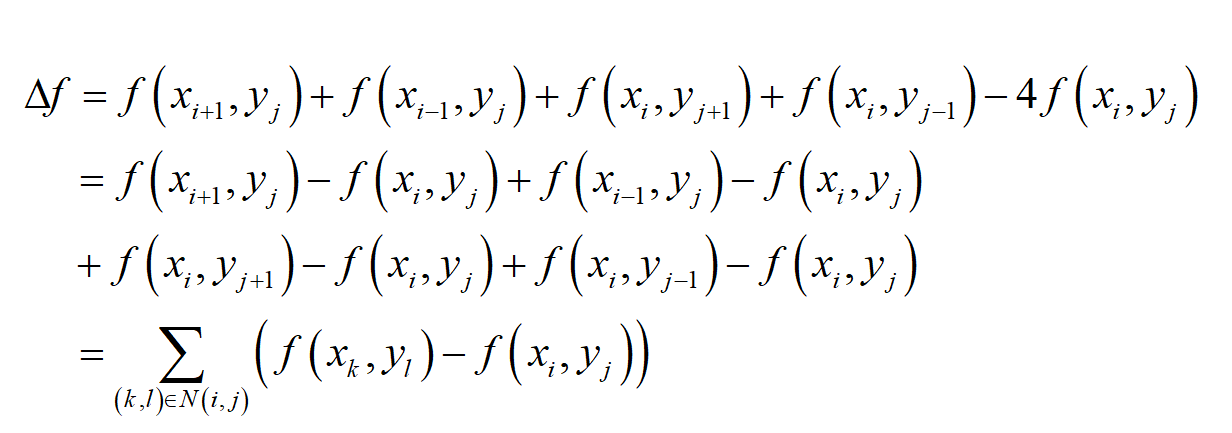
其中 N(i,j) 是 (x_{i},y_{j}) 邻居节点的集合。
图的邻接矩阵与加权度矩阵
图是一种几何结构,对它的研究起源于古老的哥尼斯堡七桥问题。一个图 G 由顶点和边构成,通常将顶点的集合记为 V ,边的集合记为 E 。边由其连接的起点和终点表示。下面是一个典型的图
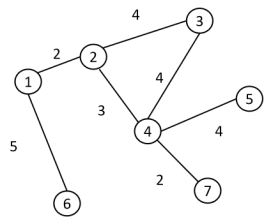
图的边可以是有方向的,也可以是没有方向的,前者称为有向图,后者称为无向图。邻接矩阵是图的矩阵表示,借助它可以方便地存储图的结构,用线性代数的方法研究图的问题。如果一个图有 n 个顶点,其邻接矩阵 W 为 n\times n 的矩阵,矩阵元素 w_{ij} 表示边 (i,j) 的权重。如果两个顶点之间没有边连接,则在邻接矩阵中对应的元素为0。对与上面的图,它的邻接矩阵为


无向图的邻接矩阵为对称矩阵。
对于无向图,顶点的加权度是与该顶点相关的所有边的权重之和。如果无向图的邻接矩阵为 W ,则顶点 i 的加权度为邻接矩阵第 i 行元素之和
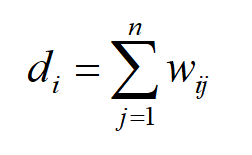
加权度矩阵 D 是一个对角矩阵,其主对角线元素为每个顶点的加权度,其他位置的元素为0
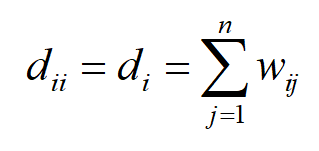
对于上面的无向图,它的加权度矩阵为


拉普拉斯矩阵
在前面二元函数的例子种,一个点只与上下左右4个采样点相邻。图的顶点的连接关系可以是任意的,下面将拉普拉斯算子推广到图。如果将图的顶点处的值看作是函数值,则在顶点 i 处的拉普拉斯算子为
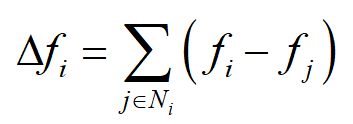
其中 N_{i} 是顶点 i 的所有邻居顶点的集合。这里我们调换了 f_{i} 和 f_{j} 的位置,和之前的拉普拉斯算子相比,相当于多了一个负号。由于图的边可以带有权重,我们可以在上面的计算公式中加上权重
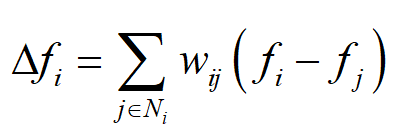
这以推广如下图所示,图中红色的顶点是 i ,蓝色的顶点是它的邻居顶点,灰色的顶点是其他顶点。
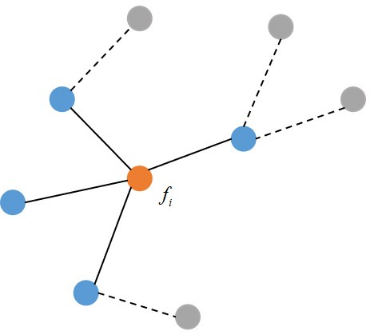
如果 j 不是 i 的邻居,则 w_{ij}=0 。因此上面的式子也可以写成
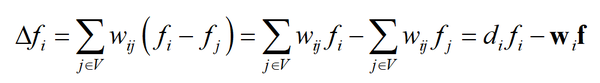
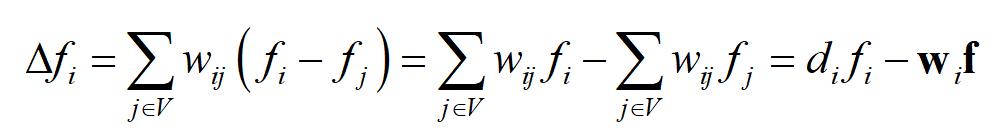
这里的 d_{i} 就是顶点 i 的加权度, w_{i} 邻接矩阵的第 i 行, f 是所有顶点的值构成的里列向量, w_{i}f 是二者的内积。对于图的所有顶点,有
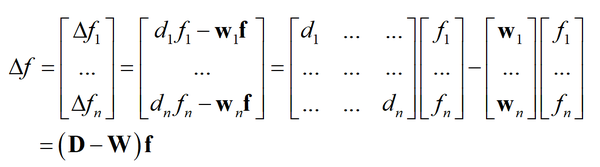
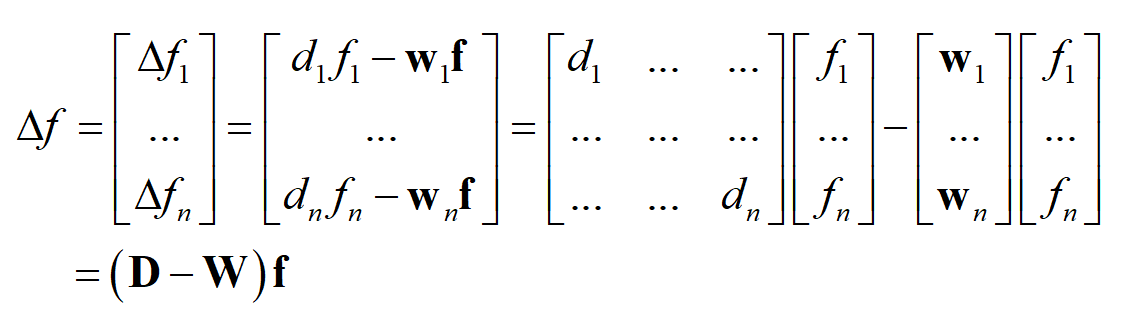
上面的结论启发我们,可以在邻接矩阵和加权度矩阵的基础上定义拉普拉斯矩阵。假设无向图 G 有 n 个顶点,邻接矩阵为 W ,加权度矩阵为 D 。拉普拉斯矩阵定义为加权度矩阵与邻接矩阵之差
L=D-W
由于 W 和 D
都是对称矩阵,因此拉普拉斯矩阵也是对称矩阵。根据前面的介绍,拉普拉斯矩阵实际代表了图的二阶导数。
以上面的图为例,它的拉普拉斯矩阵为
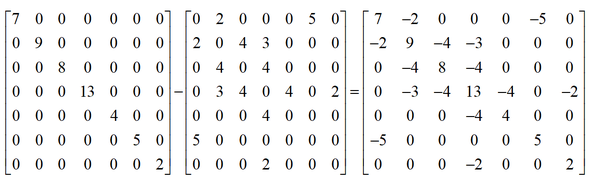
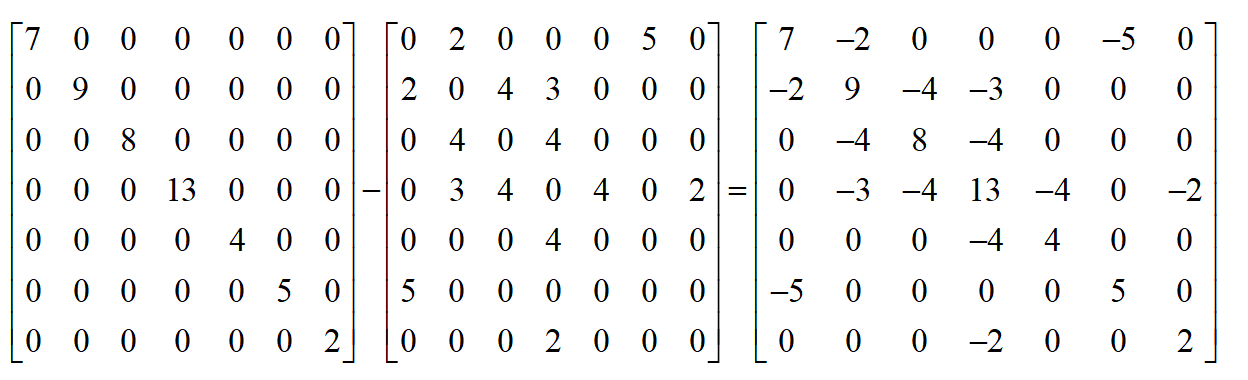
显然拉普拉斯矩阵每一行元素之和都为0。下面介绍拉普拉斯矩阵的若干重要性质。
1.对任意向量
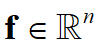
有
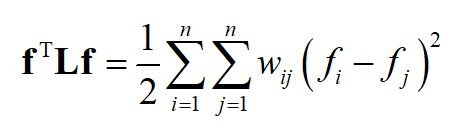
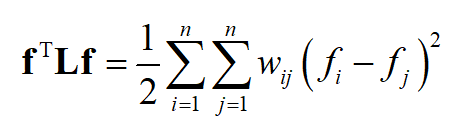
2.拉普拉斯矩阵是对称半正定矩阵;
3.拉普拉斯矩阵的最小特征值为0,其对应的特征向量为常向量 1 ,即所有分量为1;
4.拉普拉斯矩阵有 n 个非负实数特征值,并且满足
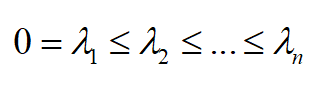
下面进行证明。根据加权度 d_{i} 的定义,有
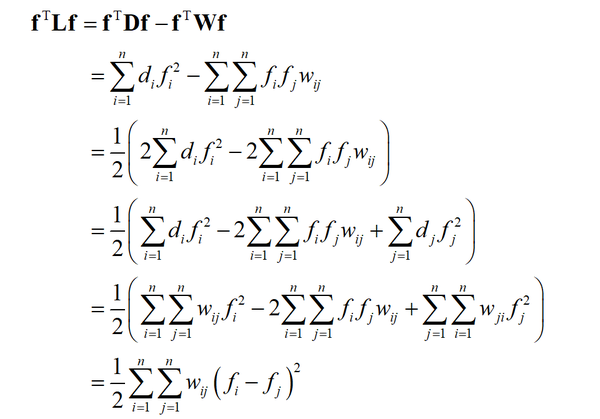
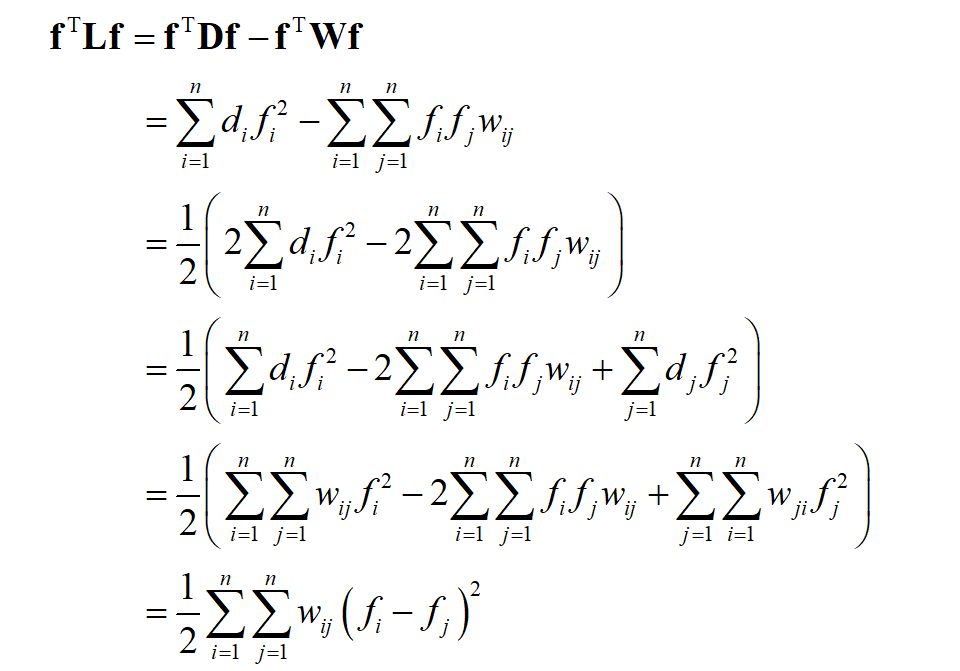
因此结论(1)成立。根据结论(1),对任意非0向量 f ,有
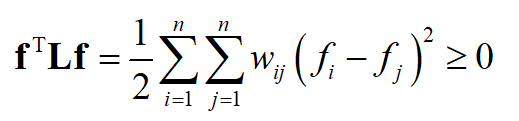
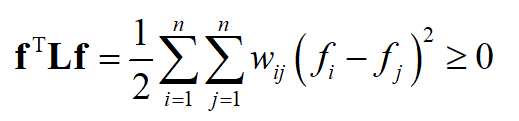
因此拉普拉斯矩阵是半正定的,结论2成立。由于
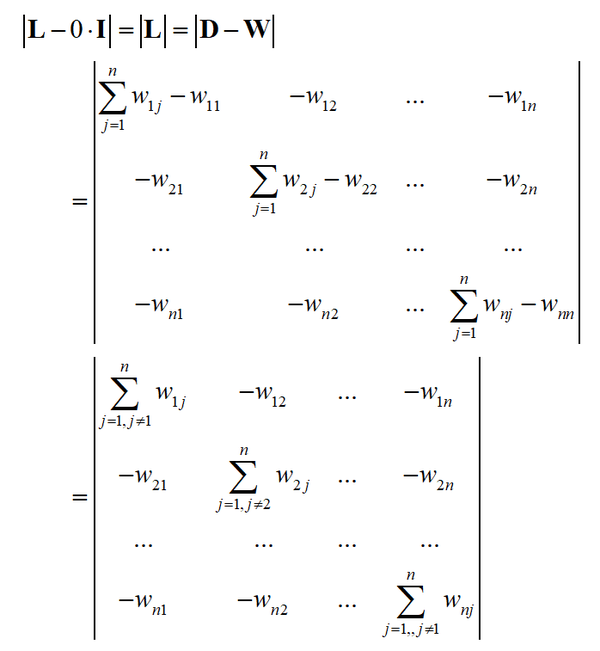
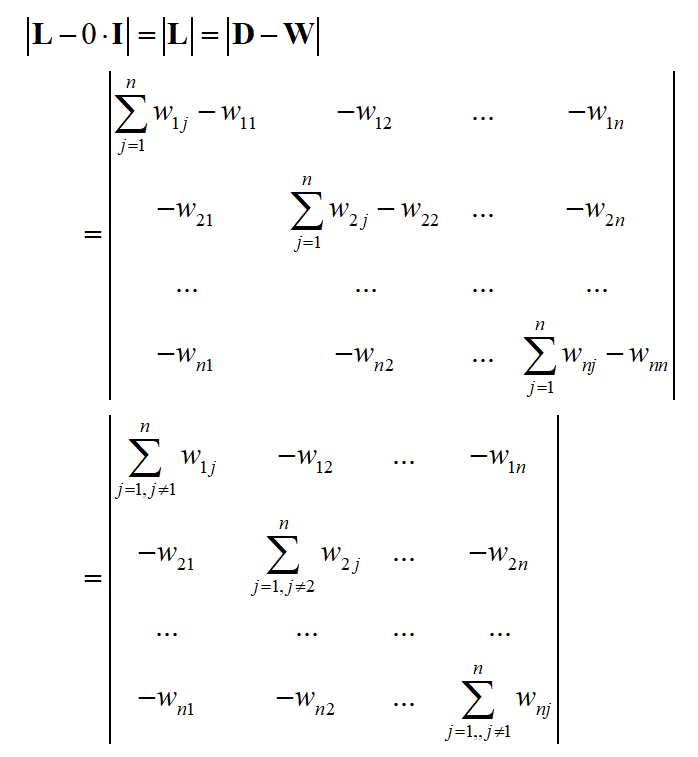
将行列式的第2~n列依次加到第1列,第1列的值全为0
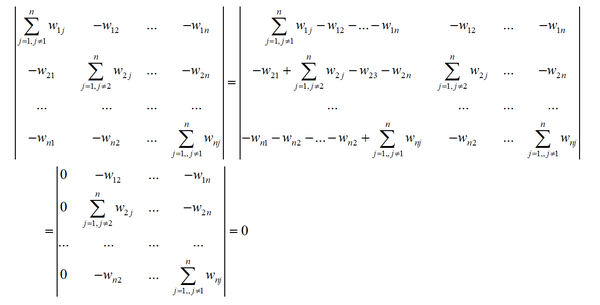
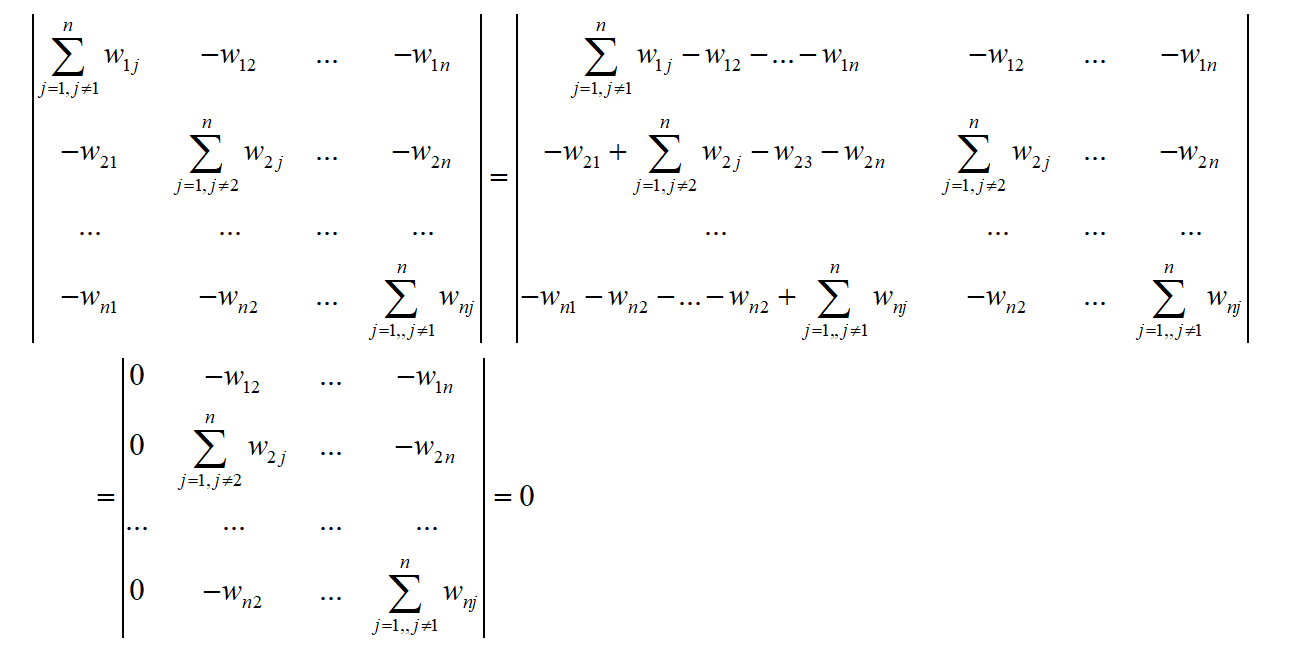
因此行列式丨 L 丨值为0,0是 L 的特征值。如果 f=1 ,则有
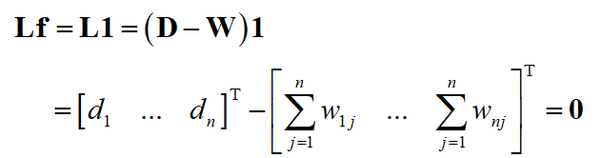
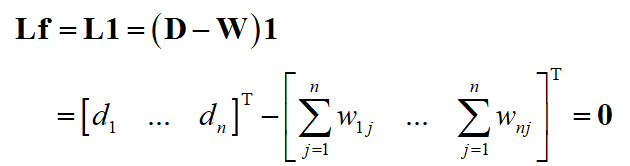
因此 1 是特征值0的特征向量,由于拉普拉斯矩阵半正定,其特征值非负,结论(3)成立。根据结论(2)和(3)可以得到结论(4)。
假设 G 是一个有非负权重的无向图,其拉普拉斯矩阵 L 的特征值0的重数 k 等于图的联通分量的个数
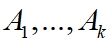
。特征值0的特征空间由这些联通分量所对应的特征向量
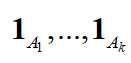
所张成。
下面进行证明。先考虑 k=1 的情况,图是联通的。假设 f 是特征值0的一个特征向量,根据特征值的定义有
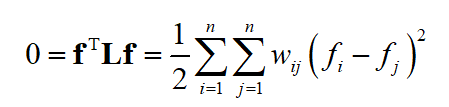
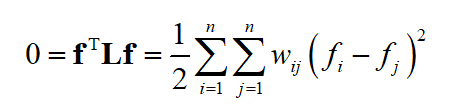
这是因为 Lf=0f=0 。因为图是联通的,因此所有的 w_{ij}>0 ,要让上面的值为0,必定有 f_{i}-f_{j}=0 。这意味着向量 f 的任意元素都相等,因此所有特征向量都是 1 的倍数,结论成立。
接下来考虑有 k 个联通分量的情况。不失一般性,假设顶点按照其所属的联通分量排序,这种情况下,邻接矩阵是分块矩阵,同样地,拉普拉斯矩阵也是这样的分块矩阵
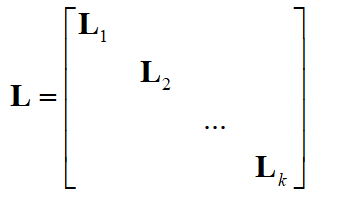
显然每个子矩阵 L_{i} 自身也是一个拉普拉斯矩阵,对应于这个联通分量。对于这些子矩阵,上面的结论也是成立的,因此 L 的谱由 L_{i} 的谱相并构成, L 的特征值0对应的特征向量是 L_{i} 的特征向量将其余位置填充0扩充形成的。具体的,特征向量中第 i 个联通分量的顶点所对应的分量为1,其余的全为0,为如下形式
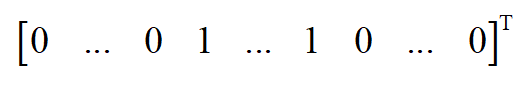
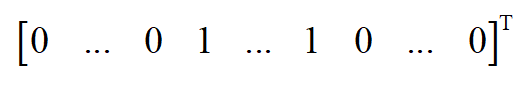
由于每个 L_{i} 都是一个联通分量的拉普拉斯矩阵,因此其特征向量的重数为1,对应于特征值0。而 L 中与之对应的特征向量在第 i 个联通分量处的值为常数,其他位置为0。因此矩阵 L 的0特征值对应的线性无关的特征向量的个数与联通分量的个数相等,并且特征向量是这些联通分量的指示向量。
下面举例说明。对于下面的图
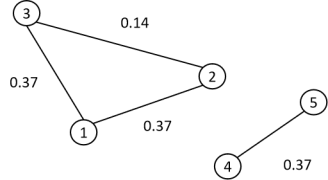
它有两个联通子图。其邻接矩阵为


其加权度矩阵为


拉普拉斯矩阵为
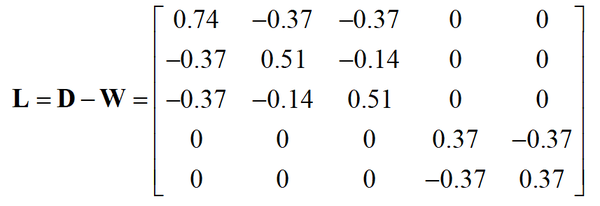

它由如下两个子矩阵构成


每个子矩阵对应于图的一个联通分量。0是每个子矩阵的1重特征值,由于有两个联通分量,因此0是整个图的拉普拉斯矩阵的2重特征值。两个线性无关的特征向量为
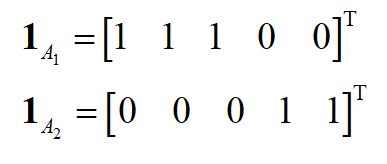
归一化拉普拉斯矩阵
对前面定义的拉普拉斯矩阵进行归一化从而得到归一化的拉普拉斯矩阵。通常有两种形式的归一化。
第一种称为对称归一化,定义为
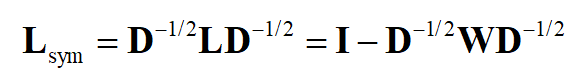
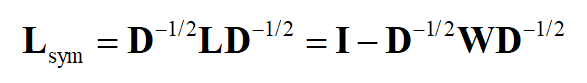
在这里 D^{1/2} 是 D 的所有元素计算正平方根得到的矩阵。位置 (i.j),i\ne j
的元素为将未归一化拉普拉斯矩阵对应位置处的元素 l_{ij} 除以
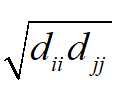
后形成的,主对角线上的元素为1,
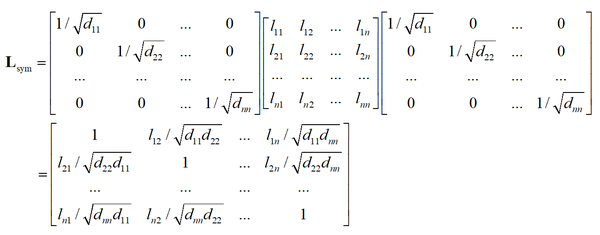
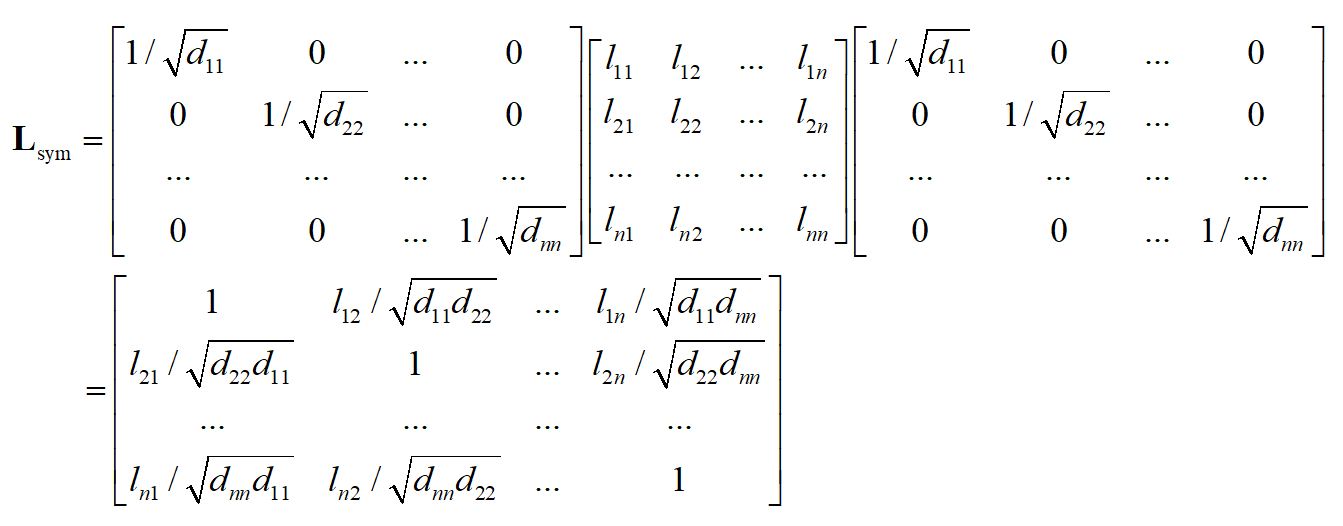
由于 D^{1/2} 和 L 都是对称矩阵,因此 L_{sym} 也是对称矩阵。如果图是联通的,则 D 和 D^{1/2} 都是可逆的对角矩阵,其逆矩阵分别为其主对角线元素的逆。
第二种称为随机漫步归一化,定义为
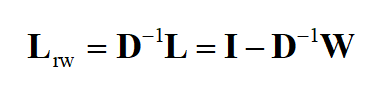
其位置 (i,j),i\ne j 的元素为将未归一化拉普拉斯矩阵对应位置处的元素 l_{ij} 除以 d_{ii} 后形成的,主对角线元素也为1
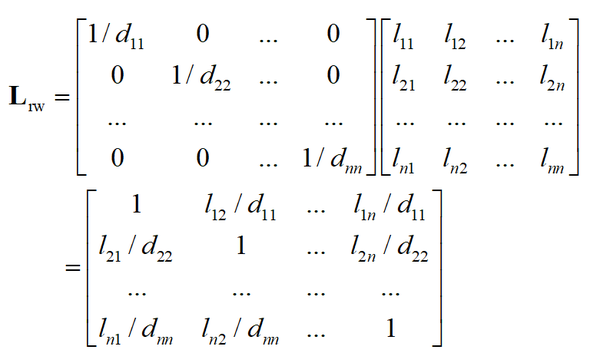
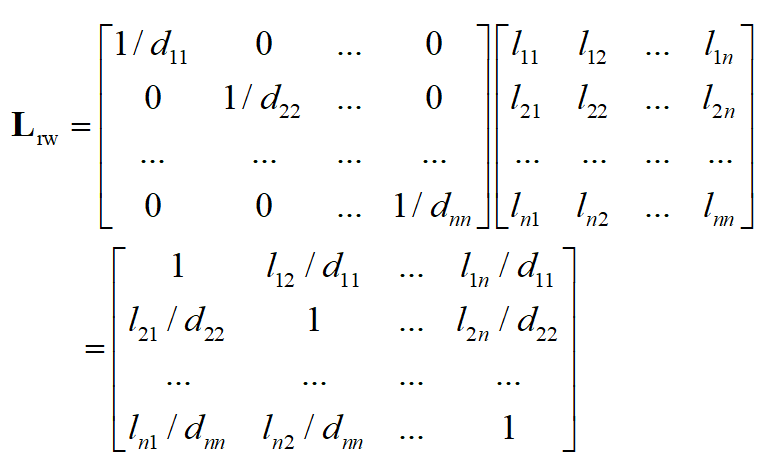
下面介绍这两种矩阵的若干重要性质。
1.对任意向量
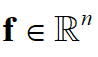
有
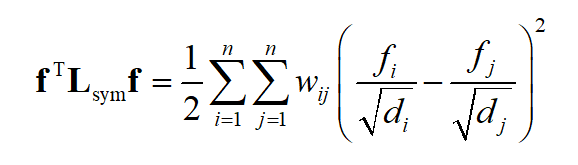
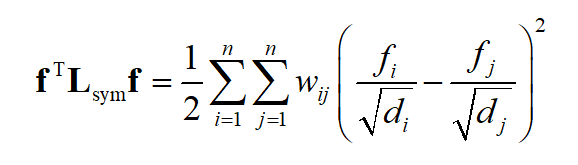
2. \lambda 是矩阵 L_{rw} 的特征值, \mu 是特征向量,当且仅当 \lambda 是 L_{sym} 的特征值且其特征向量为
w=D^{1/2}\mu
3. \mu 是矩阵 L_{rw} 的特征值, \mu 是对应的特征向量,当且仅当 \lambda 和 \mu 是下面广义特征值问题的解
Lu=\lambda Du
4. 0是矩阵 L_{rw} 的特征值,其对应的特征向量为常向量 1 ,即所有分量为1。0是矩阵 L_{sym} 的特征值,其对应的特征向量为 D^{1/2}1 。
5.矩阵 L_{sym} 和 L_{rw} 是半正定矩阵,有 n 个非负实数特征值,并且满足
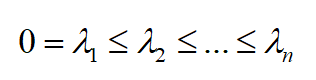
和未归一化的拉普拉斯矩阵类似,有下面的重要结论:假设 G 是一个有非负权重的无向图,其归一化拉普拉斯矩阵 L_{rw} 和 L_{sym} 的特征值0的重数 k 等于图的联通分量的个数 A_{1},...,A_{k} 。对于矩阵 L_{rw} ,特征值0的特征空间由这些联通分量所对应的向量 1_{A_{1}},...,1_{A_{k}} 所张成。 1_{A_{i}} 的定义与未归一化拉普拉斯矩阵0特征值的特征向量相同。对于矩阵 L_{sym} ,特征值0的特征空间由这些联通分量所对应的向量
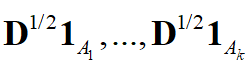
所张成。证明方法和未归一化拉普拉斯矩阵类似,感兴趣的读者可以阅读《机器学的数学》,人民邮电出版社,雷明著。
应人民邮电出版社的邀请,明天晚上8点钟(2021.4.6)将由《机器学的数学》的作者作“概率论在机器学习中的应用”的直播。为你讲述:
为什么在机器学习中需要概率论
机器学习中的概率模型概述
有监督学习中的概率模型,包括贝叶斯分类器,logistic回归,softmax回归,机器翻译问题
无监督学习中的概率模型,包括高斯混合模型,t-SNE数据降维算法,隐马尔可夫模型,概率图模型
强化学习中的概率模型,包括马尔可夫决策过程
数据生成模型中的概率模型,包括基本的随机数生成算法,生成对抗网络,变分自动编码器
我们将从数学的角度为你讲述这些方法的原理,剖析它们的本质。下面是观看直播的信息

