1 CPU高速缓存简单介绍
CPU高速缓存机制的引入,主要是为了解决CPU越来越快的运行速度与相对较慢的主存访问速度的矛盾。CPU中的寄存器数量有限,在执行内存寻址指令时,经常需要从内存中读取指令所需的数据或是将寄存器中的数据写回内存。而CPU对内存的存取相对CPU自身的速度而言过于缓慢,在内存存取的过程中CPU只能等待,机器效率太低。
为此,设计者在CPU与内存之间引入了高速缓存。CPU中寄存器的存储容量小,访问速度极快;内存存储容量很大,但相对寄存器而言访问速度很慢。而高速缓存的存储大小和访问速度都介于二者之间,作为一个缓冲桥梁来填补寄存器与主存间访问速度过大的差异。
引入高速缓存后,CPU在需要访问主存中某一地址空间时,高速缓存会拦截所有对于内存的访问,并判断所需数据是否已经存在于高速缓存中。如果缓存命中,则直接将高速缓存中的数据交给CPU;如果缓存未命中,则进行常规的主存访问,获取数据交给CPU的同时也将数据存入高速缓存。
但由于高速缓存容量远小于内存,因此在高速缓存已满而又需要存入新的内存映射数据时,需要通过某种算法选出一个缓存单元调度出高速缓存,进行替换。
由于对内存中数据的访问具有局部性,使用高速缓存能够极大的提高CPU访问存储器的效率。
靠近CPU的小的、快速的高速缓存存储器是内存上一部分数据和指令的缓冲区域。主存缓存磁盘上的数据,而这些磁盘又常常作为存储在通过网络连接的其他机器的磁盘或磁带上的数据的缓冲区域。存储层次如下:
2 缓存如何判断哪些数据是更常用的
缓存上存储的数据是那些计算机认为在接下来更有可能访问到的数据,计算机如何判断哪些数据接下来更有可能用到呢?系统对数据的访问频率有两种假设:
1. 时间局部性
时间局部性假设目前访问的数据在接下来也更有可能再次访问到,所以计算机会把刚刚访问过的数据放入缓存中;
2. 空间局部性
空间局部性假设与目前访问的数据相邻的那些数据接下来也更有可能访问到,所以会把当前数据周围的数据放入缓存中;
一个编写良好的代码往往符合时间局部性和空间局部性。
3 cpu如何访问数据
3.1 数据在存储器层次之间以块为单位进行传递
存储器层次结构的本质是,每一层存储设备都是较低一层的缓存。为了利用空间局部性,存储器上的数据都是按块划分的,每个块包含多个字节的数据。第k层的缓存包含第k+1层块的一个子集的副本。数据总是以块为传送单位在第k层和第k+1层来回复制的。在层次结构中任何一对相邻的层次之间块大小是一样的。不过不同的层次之间块大小可以不同,一般而言,越靠近底层,越倾向于使用较大的块。
当程序需要第k+1层的某个数据时,它首先在第k层的一个块中查找d,这里会出现两种情况:
1. 缓存命中
d刚好缓存在k层中,这里称之为缓存命中,该程序直接从k层读取d,根据存储器层次结构,这要比从k+1层取数据更快。
2. 缓存不命中
d没有缓存在k中,这种情况称之为缓存不命中,第k层的缓存从第k+1层中取出包含d的那个块,放在k层中,然后从k层读出d。这里涉及一个问题,即从k+1层中取出的块应如何放置在k层中,这里需要某种放置策略。可用的策略如下:
(1)随机放置,在k中随机选择一个位置进行放置,这种策略实现起来通常很昂贵,因为不好定位;
(2)分组放置,将第k+1层的某个块放置在第k层块的某个小组(子集)中;
1. 高速缓存的结构及与地址的映射关系
高速缓存使用分组放置策略,它把存储空间分为S组,每组E行,每行包含1个块,每个块的大小为B,它的结构可以用四元组(S,E,B,m)来表示,其中m代表地址位的个数。高速缓存的容量为C=S*E*B;
当访问数据时,我们唯一知道的是数据的地址。通过地址我们如何从缓存中找到数据所在的组号,块号和块中的位置呢?这里m个地址位分为了3个字段,其中高位的字段为t个标记位,它唯一的标记了组中的块,中间的字段为s个索引位,它标记了组号,最后的字段为块偏移,通过它可以访问块中具体的字节。另外缓存结构中每一行最前面还有一个有效位,它标志了这一行有没有存储块。缓存结构如下:
2. 一个简单的存储模型
下面定义一个简单的存储层次模型:
(1)cpu和内存之间只加了一层高速缓存;
(2)存储地址为4位,即内存中最多存16个字节;
4位的地址被分成了3段:最高位的1段为标记位,中间2位为索引组,最后1位为块偏移。从索引组的的位数可判断缓存被分成了4组,1位的块偏移说明块的大小为2个字节。这里设每组只有1行,这种情况称为直接映射高速缓存。从以上分段可知,缓存大小为 4*2*1=8 字节;
举例:地址0101;其中高位的0为标记位,标记组中的1个块,中间的两位10为组索引,通过组索引可知当前地址的块存在组2中,最后1位为偏移位,说明要取的字节存在块中的第2个位置。
3. 缓存过程
(1)初始状态缓存是空的,当cpu通过地址(假设为0001)要加载一个数据时,此时cpu会先查找高速缓存,通过中间的地址00找到第0组,通过缓存最前面的有效位判断缓存不命中,然后从内存中取得地址0001处的值。注意此时不会从内存中只取0001处的值,而是根据缓存的块的大小取得1个块,即2个字节,即0000和0001两处的值。然后会把这两个值存储在组索引为0,偏移量为0和1的地址处,并且把当前行的有效位设置为1,标记位设置为0,最后高速缓存返回新取出的高速缓存块[1]处的值;
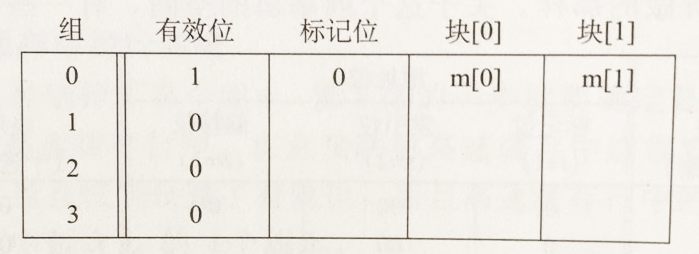
(2)接下来,cpu如果要取0000处的值,此时也会先查找缓存,通过中间2位00找到缓存的组数为0,通过第1个有效位(1)和标记位(0)判断缓存命中,此时会直接返回偏移量0处的值,不需要再查找内存;
(3)如果接下来cpu要取1000处的值,此时会查找到组0,由于地址的标记位为1,和缓存组0中行的标记位(0)不符合,所以缓存不命中,cpu会从内存中取得相应的块,并把缓存组0处的数据覆盖掉,此时会把组的标识位设置为1。
(4)接下来再读地址0000处的值,此时又会发生缓存不命中,因为上面引用地址1000时,把块替换掉了。这种情况称为冲突不命中,也就是说我们有足够的高速缓存空间,但是却交替地引用映射到同一个组的块;
cpu加载机制为,通过地址先查找缓存,查找过程为,先通过地址中间的组索引位,找到组,然后根据组中行的有效位和标记位判断是否缓存命中,如果命中,则直接从缓存中取数据;如果没命中,则从内存中取出1个块,并用某种放置策略放在缓存中,然后从缓存返回值。在直接映射高速缓中,内存中的空间和缓存中的空间是一种多对一的映射关系,比如本例中地址0和地址8所指的内存空间的内容,在缓存中都存在第0组偏移量为0的空间中;他们在缓存中的区分由地址的最高位即标记位决定。
4 高速缓存一致性问题
4.1 解决缓存冲突问题
1. 什么是缓存冲突
当每个组只有一行的情况下,映射为同一组的块在缓存中将占用同一个存储空间,当反复加载位于同一组的两个块时,由于每次加载都会把先前加载的块覆盖掉,导致cpu对缓存的命中率为0,虽然此时在其他组依然有大量的缓存空间。
2.组相联高级缓存
为了降低缓存冲突,可以把每个组分为多行,每行存储一个块。cpu通过组索引查找块所在的组,然后通过有效位和标记位检查多行来判断是否缓存命中。当缓存不命中时,会从内存中加载一个块到缓存相对应的组中,当组内有空行时,会直接加载到空的行,否则缓存会使用某种替换策略来换掉组内的一行。常用的替换策略有随机替换,最近最少使用原则,即替换掉组内最长时间未使用的行。当缓存中只有1个组,组中包含所有行时,称为全相联高速缓存。
4.2 高速缓存与内存的一致性问题
高速缓存在命中时,意味着内存和高速缓存中拥有了同一份数据的两份拷贝。CPU在执行修改内存数据的指令时如果高速缓存命中,只会修改高速缓存中的数据,此时便出现了高速缓存与内存中数据不一致的问题。
这个不一致问题在早期单核CPU环境下似乎不是什么大问题,因为所有的内存操作都来自唯一的CPU。但即使是单核环境下,为了减轻CPU在I/O时的负载、提高I/O效率,先进的硬件设计都引入了DMA机制。DMA芯片在工作时会直接访问内存,如果高速缓存首先被CPU修改和内存不一致,就会出现DMA实际写回磁盘的内容和程序所需要写入的内容不一致的问题。
为了更好的理解多核CPU环境下工作的MESI协议,这里先简单介绍单核环境下
高速缓存被首先改写而导致cache与主存不一致问题
的解决方案,简单来说有两种方法:
通写法
和
回写法
。
通写法(Write Through):
即CPU在
对cache写入数据时,同时也直接写入主存
,这样就能使得主存和cache中的数据始终保存一致。
通写法的优点是简单,硬件上容易实现,同时在调度缓存单元时不会有脏数据,调度速度快;缺点是每次cache写入操作时都增加了写主存的等待时间,效率较低。
回写法(Write Back):
回写法和通写法的主要区别在于,回写法在CPU
写cache时并不实时同步写主存,而是在进行调度被覆盖前整体的写回主存
。如果被调度出的cache单元并没有被写入过,则直接被覆盖无需写回主存。
回写法的优点是写入cache时无需同步主存,总体效率比通写法高。缺点是硬件实现较为复杂。
多核CPU高速缓存间的一致性问题
随着单核主频速度的增长受到制约,CPU的发展由单核逐渐过度到了多核,目前主流的CPU都是多核心的。但随着多核CPU提高计算机并发性能的同时,也带来了一系列的问题,这其中就包括了
多核CPU下的高速缓存一致性问题
。
在多核CPU的架构下,通常每一个核心都拥有着自己独有的高速缓存,每个核心能并发的读写自己的高速缓存。
高速缓存可以有多个,但其对应的内存数据逻辑上却只有一份,多核并发的修改其高速缓存中同一内存的映射数据就会出现高速缓存中的数据不一致的问题。
如果不对多核CPU下的高速缓存并发访问施加一定的约束,那么并发程序中对共享内存数据的存取就会出现问题,
并发程序的正确性将无法得到有效保障
。
4.3 高速缓存一致的存储系统定义
在讨论解决高速缓存一致性问题的方法前,我们需要更精确的定义
什么是高速缓存一致性。
内存系统的一个本质特征是:一个内存系统应该能提供一组保存值的存储单元,当对一个存储单元执行读操作时,应该能返回
“最近”
一个对该存储单元的写操作所写入的值。在串行程序中,程序员利用内存来将程序中某一点计算出来的值,传递到该值的使用点,实际上就是利用了上述基本性质。同样,运行在单处理器上的多个进程或线程利用共享地址空间进行通信,实际上也是利用了内存系统的这个性质。
一个读操作应返回最近的向那个位置的写操作所写的值,而不管是哪个线程写的。
当所有的线程运行在同一个物理处理器上时,它们通过相同的高速缓存层次来看内存,因此在这种情况下,高速缓存不会引起问题。当在共享存储的多处理器系统上运行一个具有多个线程的程序时,希望不管这些线程是运行在同一个处理器上,还是位于不同的处理器上,程序的运行结果都是相同的。
上面摘抄自书上的概念描述有些晦涩,我个人的理解是:
按照程序指令的运行顺序,对于同一内存单元内容(变量值)能够令后面的读操作读取到之前最近写操作后的结果,保证程序逻辑序的正确性
。这一顺序性的保证在单核环境下不是问题,因为所有的指令顺序都使用同一个高速缓存,但在多核多高速缓存副本的情况下运行某一程序的多个并发任务时就会出现问题,因为并没有约定多个处理器核心对同一存储单元并发操作时的
全局顺序
,即
“最近”
这一概念是模糊、不明确的。
因此,一个高速缓存一致的存储系统其首先要满足的一个条件便是:
根据一个程序的任意一次执行结果,都能够对每个内存单元的存取操作构造出逻辑上的全局串行序列(即使是多核体系下,对内存的存取逻辑上也要强制串行化)
。这一全局逻辑串行序列还需要满足额外的两个条件:
一是同一处理器所发出的程序内存存取指令顺序(程序逻辑序),与在全局逻辑串行序列中的先后顺序保持一致;二是每个读操作的值,返回的是在全局逻辑串行序列中最近的写操作之后的值。
上述高速缓存一致性的定义隐含了在多核环境下的两个重要性质:一是
写传播
,二是
写串行化
。
写传播(Write Propagation):
一个处理器对一个位置的所写入的值,最终对其它处理器是可见的。
写串行化(Write Serialization):
对同一内存单元的所有写操作(无论是来自一个处理器还是多个处理器)都能串行化。换句话说,所有的处理器能以相同的次序看到这些写操作。
4.4 MESI高速缓存一致性协议
通常多核并行架构的CPU,每个核虽然都独自工作,但与外部存储器的交互依然是共用同一总线进行的。通过总线,每个核心都能够监听、接收到来自其它核心的消息通知,这一机制被称为
总线侦听
或是
总线嗅探
。
基于总线侦听的写传播:
每个核心在对自己独有的高速缓存行进行修改时,需要将修改通知送至总线进行广播。其它核心在监听到总线上来自其它核心的远程写通知时,需要查询本地高速缓存中是否存在同样内存位置的数据。如果存在,需要选择将其设置为
失效
状态或是
更新
为最新的值。
基于总线侦听的写串行化:
总线上任意时间只能出现一个核的一个写通知消息。
多个核心并发的写事件会通过总线仲裁机制将其转换为串行化的写事件序列(可以简单理解为逻辑上的一个FIFO事件队列)
,在每个写事件广播时,必须得到每个核心对事件的响应后,才进行下一个事件的处理,这一机制被称作
总线事务
。
而本文的主角
MESI协议
便是
基于总线侦听机制,采用回写法、写传播失效策略的高速缓存一致性协议
,其另一个更精确的名称是
四态缓存写回无效协议。
随着多核CPU中并发程序的不断运行,高速缓存被反复的读写,缓存内存行的状态也会在MESI这四种状态间反复变化。
在MESI协议中,抽象出了四种会导致缓存内存行状态的变化缓存事件:
本地读、本地写、远程读
以及
远程写
。缓存事件针对的是某一内存缓存行的事件。
本地读(Local Read):
本地读事件指的是本地核心对自己的缓存行进行读取。
本地写(Local Write):
本地写事件指的是本地核心对自己的缓存行进行写入。
远程读(Remote Read):
远程读事件指的是总线上的其它核心对某一内存缓存行进行了读取,当前核心监听到的事件。
某一个核心的本地读事件,对于其他核心就是针对其对应内存缓存行的远程读事件。
远程写(Remote Write):
远程写事件指的是总线上的其它核心对某一内存缓存行进行了写入,当前核心监听到的事件。
某一个核心的本地写事件,对于其他核心就是针对其对应内存缓存行的远程写事件。
通过MESI协议,在强制串行化的总线事务帮助下能够始终保持一个全局高速缓存一致的稳定状态。
MESI协议依赖总线侦听机制,在某个核心发生本地写事件时,为了保证全局只能有一份缓存数据,要求其它核对应的缓存行统统设置为Invalid无效状态。为了确保总线写事务的强一致性,发生本地写的高速缓存需要等到远端的所有核心都处理完对应的失效缓存行,返回Ack确认消息后才能继续执行下面的内存寻址指令(阻塞)。
原始MESI协议实现时的性能问题:
1.对于进行本地写事件的核心,远端核心处理失效并进行响应确认相对处理器自身的指令执行速度来说是相当耗时的,在等待所有核心响应的过程中令处理器空转效率并不高。
2.对于响应远程写事件的核心,在其高速缓存压力很大时,要求实时的处理失效事件也存在一定的困难,会有一定的延迟。
不进行优化的MESI协议在实际工作中效率会非常的低下,因此CPU的设计者在实现时对MESI协议进行了一定的改良。
原文链接:
https://www.cnblogs.com/snsart/p/10700599.html
什么是
缓存
缓存
又叫
高速缓存
,是计算机存储器中的一种,本质上和硬盘是一样的,都是用来存储数据和指令的。它们最大的区别在于读取速度的不同。程序一般是放在
内存
中的,当CPU执行程序的时候,执行完一条指令需要从
内存
中读取下一条指令,读取
内存
中的指令要花费100000个时钟周期(
缓存
读取速度为200个时钟周期,相差500倍),如果每次都从
内存
中取指令,CPU运行时将花费大量的时间在读取指令上。这显然是一种资源浪费。
如何解决这个问题呢?有人肯定会问,直接把程序存储在
缓存
中不行吗?
答案是可以的。但是
高速缓冲存储器部件结构及原理解析
高速缓存
CACHE用途设置在 CPU 和 主存储器之间,完成高速与 CPU交换信息,尽量避免 CPU不必要地多次直接
访问
慢速的主存储器,从而提高计算机系统的运行效率。
高速缓存
CACHE实现原理把CPU最近最可能用到的少量信息(数据或指令)从主存复制到CACHE中,当CPU下次再用到这些信息时,它就不必
访问
慢速的主存,而直接从快速的CACHE中得到,从而提高了速度...
本文详细讲述的
高速缓存
的原理,分别介绍了:Cache基本结构新计算机体系之下的Cache结构、Cache的
工作
进程、新计算机体系之下的Cache结构、Cache的
工作
进程,并详细讲解的
高速缓存
的各种问题。
这里写自定义目录标题
高速缓存
系统概述存储器层次结构
高速缓存
基本原理
高速缓存
的设计
高速缓存
的存取物理地址还是虚拟地址写策略数据同步问题
高速缓存
系统概述
高速缓存
存储系统(cache memory system)是高速存储器,他能利用引用的局部性来提高系统性能。
存储器层次结构
高速缓存
(cache)保存有主存储器很小的一个自己的内容,利用局部引用特性来改善系统性能。
局部引用特性:大多说程序表现出...
多核CPU有很多好处,其中最重要的一个就是,它使得我们在不断提升CPU的主频之后,找到了另一种提供CPU吞吐率的方法。
多核CPU里的每一个CPU核,都有独立的属于自己的L1 Cache和L2 Cache。多个CPU之间,只是共用L3 Cache和主
内存
。
但是因为CPU的每个核都有各自的
缓存
,互相之间的操作又是各自独立的,就会带来
缓存
一致性问题。
ps:语言层面解决
缓存
不一致,可以使用volatile,强制CPU读写都直接
访问
主
内存
。(volatile的本意是告诉编译器,此变量的值是易变的,每次读写
高性能网站设计之
缓存
Prerequisite: Cache Memory and its levels
先决条件:
高速缓存
及其级别
缓存
性能 (Cache Performance)
When the CPU needs to read or write a location in the main memory that is any process requires some data,...
这里m个地址位分为了3个字段,其中高位的字段为t个标记位,它唯一的标记了组中的块,中间的字段为s个索引位,它标记了组号,最后的字段为块偏移,通过它可以
访问
块中具体的字节。(3)如果接下来cpu要取1000处的值,此时会查找到组0,由于地址的标记位为1,和
缓存
组0中行的标记位(0)不符合,所以
缓存
不
命中
,cpu会从
内存
中取得相应的块,并把
缓存
组0处的数据覆盖掉,此时会把组的标识位设置为1。d
没有
缓存
在k中,这种情况称之为
缓存
不
命中
,第k层的
缓存
从第k+1层中取出包含d的那个块,放在k层中,然后从k层读出d。
西电计组 考研笔记内容较多 建议收藏持续更新 欢迎关注
局部性原理:高速缓冲存储器Cache的
工作
建立在程序与数据的局部性原理之上,即在一段较短的时间间隔内,程序集中在某一较小的主存地址空间上执行,同样对数据的
访问
也存在局部性现象。Cache的概念:基于程序及数据的局部性原理,在CPU和主存之间(尽量靠近CPU的地方)设置一种容量较小的高速存储器,将当前正在执行的程序和正在
访问
的数据放入其中。在程序运行时,不需要从慢速的主存中取指令和数据,而是直接
访问
这种高速小容量的存储器,从而可以提高CPU的程序执行速度
在计算机系统中,CPU
高速缓存
(英语:CPU Cache,在本文中简称
缓存
)是用于减少
处理器
访问
内存
所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于
内存
,但速度却可以接近
处理器
的频率。
当
处理器
发出
内存
访问
请求时,会先查看
缓存
内是否有请求数据。如果存在(
命中
),则不经
访问
内存
直接返回该数据;如果不存在(失效),则要先把
内存
中的相应数据载入
缓存
,再将其返回
处理器
。
缓存
之所以有效,主要是因为程序运行时对
内存
的
访问
呈现局部性(Locality)特征。这种局部性既包
如果您买过计算机,那么您肯定听说过“
缓存
”这个词。现代计算机都有L1和L2
缓存
,许多计算机现在还有L3
缓存
。可能还有热心朋友在
缓存
方面给您出过主意,像“别买赛扬的芯片,它里面
没有
任何
缓存
!”。
事实表明,
高速缓存
是计算机科学所采用的一种重要方法,它以各种不同的形式存在于每台计算机上。
缓存
分为
内存
缓存
、硬件和软件磁盘
缓存
、页
缓存
等等。甚至虚拟
内存
也是一种
高速缓存
形式。在本文中,我
计算机基础:10、计算机的
高速缓存
1、
高速缓存
的
工作
原理2、
高速缓存
的替换策略
1、
高速缓存
的
工作
原理
字:存放在存储单元中的二进制代码组合,一个字可以表示一个数据,可以表示一个指令,可以表示一个字符串。字是
内存
中存储单元的最小单位
字块:连续的字,一组字(字块包含了多个字)。存储在连续的存储单元中,从而被看做是一个单元的一组字
主存与字以及字块的关系如下图
内存
寻址的过程:对于字的寻址,字的地址可以包括两个部分
字块的部分,用来指示当前寻址的字属于哪个字块的
字的部分,用来寻找字块里面哪一个字是这个

