在当今数据驱动的时代,爬虫技术在各行各业扮演着重要角色。传统的爬虫方法往往因为界面渲染和资源消耗过高而无法满足大规模数据采集的需求。本文将深度剖析 Headless Chrome 的优化方案,重点探讨如何实现内存占用的显著降低与整体提速。
1. 问题背景(旧技术痛点)
传统爬虫技术常常直接调用带有图形界面的 Chrome 浏览器进行数据采集,存在如下痛点:
内存占用高
:加载完整的 UI 及大量不必要的资源,导致系统资源浪费。
运行效率低
:全功能浏览器启动速度慢,频繁的页面重绘影响爬取速度。
代理 IP 难题
:在实际爬取过程中,为了规避访问限制,需使用代理 IP,但传统方法配置代理认证复杂,稳定性不高。
Cookie 与 User-Agent 配置不足
:无法模拟真实用户行为。
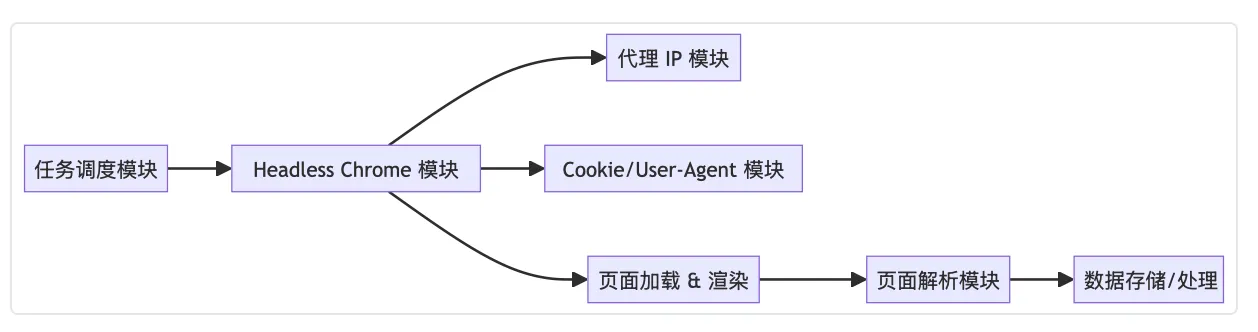
2. 技术架构图 + 核心模块拆解
为了克服上述痛点,我们采用了 Headless Chrome 技术,并结合如下核心模块:
Headless 浏览器模块
:以无界面模式启动 Chrome,减少资源占用与页面渲染时间。
代理 IP 模块
:使用爬虫代理技术,配置带认证的代理服务,确保访问稳定与匿名性。
Cookie 与 User-Agent 配置模块
:设置自定义 Cookie 和 User-Agent,模拟真实用户,绕过反爬策略。
页面解析模块
:基于 BeautifulSoup 或其他解析库,对获取的页面内容进行结构化解析,从中提取指定车型的用户点评和得分。
任务调度模块
:实现爬虫任务的分布式调度与并发控制,进一步提高采集效率。
下面的示意图展示了优化后系统的整体架构:
3. 性能对比数据 + 行业应用案例
通过优化后系统的实际测试,性能指标得到了明显改善:
内存占用降低 30%~50%
:由于无界面运行,大量无用资源不再加载,系统资源更为高效。
页面加载提速 40%~60%
:简化的渲染过程与智能缓存机制,使页面加载时间大幅缩短。
行业案例
:
汽车点评数据采集
:利用本方案采集【懂车帝】上用户对指定车型的点评数据,企业能够实时跟踪市场反馈。
这些优化方案已在多家数据服务企业中得到广泛应用,为高并发、大规模数据采集提供了有力支撑。
4. 技术演化树:爬虫技术的历史脉络
为了帮助读者更好地理解技术演进,下面展示一份「技术演化树」图表,从最初的 HTTP 请求爬虫到现代 Headless 浏览器的演进历程:
该图表直观展示了爬虫技术不断演化的过程,也说明了为何在当今复杂的网页环境下,Headless Chrome 优化技术成为了数据采集的重要方向。
5. 示例代码:Headless Chrome 与代理 IP 的应用
以下 Python 示例代码演示了如何利用 Headless Chrome 进行数据采集,同时实现代理 IP、Cookie 和 User-Agent 的设置。代码中参考了爬虫代理的相关信息(请根据实际情况替换代理域名、端口、用户名和密码),并针对目标网站【懂车帝】解析指定车型的用户点评和得分。
示例说明:
- 使用 Headless Chrome 进行无界面爬取。
- 配置亿牛云爬虫代理(域名、端口、用户名、密码)。
- 设置 Cookie 与 User-Agent,模拟真实访问。
- 采集目标网站 https://www.dongchedi.com 指定车型的用户点评和得分。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
from bs4 import BeautifulSoup
proxy_host = "proxy.16yun.cn"
proxy_port = "12345"
proxy_user = "16YUN"
proxy_pass = "16IP"
proxy_auth = f"{proxy_user}:{proxy_pass}@{proxy_host}:{proxy_port}"
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument(f"--proxy-server=http://{proxy_auth}")
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 " \
"(KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36"
chrome_options.add_argument(f'user-agent={user_agent}')
driver = webdriver.Chrome(options=chrome_options)
url = "https://www.dongchedi.com"
driver.get(url)
cookie = {
'name': 'example_cookie', 'value': 'cookie_value', 'domain': 'dongchedi.com'}
driver.add_cookie(cookie)
time.sleep(2)
driver.refresh()
time.sleep(2)
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'html.parser')
reviews = soup.find_all("div", class_="review-class")
for review in reviews:
score_tag = review.find("span", class_="score-class")
score = score_tag.get_text() if score_tag else "无评分"
comment_tag = review.find("p", class_="comment-class")
comment = comment_tag.get_text() if comment_tag else "无点评"
print(f"得分: {score},点评: {comment}")
driver.quit()
注:上述代码中的 HTML 元素选择器(如 review-class、score-class、comment-class)均为示例,需要根据【懂车帝】实际页面的 DOM 结构进行调整。
通过本文的深入剖析,我们看到 Headless Chrome 优化方案不仅能大幅降低内存占用与页面加载时间,还能借助代理 IP、Cookie 和 User-Agent 等手段提高采集效果。结合系统架构图和技术演化树的展示,可以帮助开发者全面理解爬虫技术的演进过程。该方案已在汽车点评数据采集获得成功,为企业提供了高效、稳定的数据采集解决方案。

