

Spark生产案例剖析-Spark 读取 HDFS文件时,Task数量与什么有关?

一、问题描述
话说三国,东汉末年分三国,烽火连天不休,儿女情长,被乱世左右......
收!!!,回归正题,有天安哥被同事小弟问到
小弟:你知道Spark 读取 HDFS 文件时,读取的Task数量与什么有关嘛?
安哥:Task数量不就等于HDFS 的文件数嘛?
小弟:那为什么我统计的HDFS文件数是20,但却有23个task?


安哥:我不信,让我来实践一波(哈哈,程序员对于排查BUG的好奇心啊)
二、问题探索
1.确认HDFS文件数
HDFS 命令统计,确认是20个文件
hdfs dfs -count -q -h /json/part_date=2019-10-03
1 20 2.7 G /json/part_date=2019-10-03
2.确认读取的Spark Task数
- spark-shell执行读取此目录命令
scala> spark.read.text("/json/part_date=2019-10-03").count()- Spark-UI查看
确实不一样啊,读取的时候task数是23




3.确认读取的task数是不是等于HDFS Block数
- HDFS-UI确认
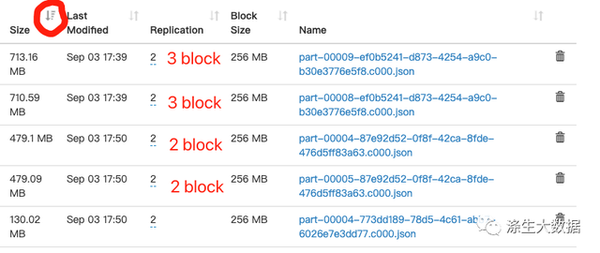
- 是不是因为有大于256M的文件,大于256M的文件在hdfs会分为拆分多个block存储(集群设置block size=256M)
- 然后我去HDFS UI界面确认一波,先按文件大小倒序排序,然后查看大于256M的文件被分为多少个block
- 按这样计算应该是 20-4+3+3+2+2=26个,还是不对



5.Spark官网+Google+百度
Spark官网+Google+百度,搜索一波资料,发现Spark Conf 有两个配置决定了单个分区,也是单个task读取的数据量
- spark.sql.files.maxPartitionBytes
- 默认值:134217728 (128 MB)
- 含义:The maximum number of bytes to pack into a single partition when reading files.(每个分区的最大的文件大小,针对大文件切分)
- spark.files.openCostInBytes
- 默认值:4194304 (4 MB)
- 含义:The estimated cost to open a file, measured by the number of bytes could be scanned at the same time. This is used when putting multiple files into a partition. It is better to overestimate, then the partitions with small files will be faster than partitions with bigger files. (小于该值的文件会被合并,针对于小文件合并)
-
6.实践才是检验真理的唯一标准,验证一波Spark 两个参数
场景1: 读取单个大文件(479.2 MB)
代码+Spark UI运行截图:
scala> spark.read.json("json/part_date=2019-10-03/1.json").count()
res0: Long = 1488583
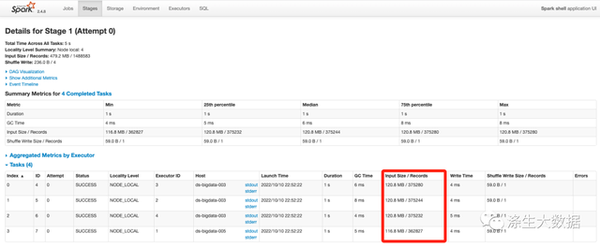

结论 :拆成了4个文件,每个文件小于128M
场景2: 读取两个小文件(1.9MB和1.9MB)
代码+Spark UI运行截图:
scala> spark.read.json("json/part_date=2019-10-03/1.json").count()
res0: Long = 1488583


结论 :发现两个小文件并没有被合并,神奇,别慌,再继续下一个场景验证
场景3:读取两个小文件和一个大文件(1.9MB、1.9MB、130M)
代码+Spark UI运行截图:
scala> spark.read.json("json/part_date=2019-10-03/2.json","json/part_date=2019-10-03/3.json","json/part_date=2019-10-03/4.json").count()
res0: Long = 588774


结论: 发现数据被打散,三个文件被两个task读取
7.看来实践不足以证明真理,只能用源码来证明了,冲啊!
- 下载Spark2.4.8源码,搜索关键参数 spark.files.openCostInBytes
- 包路径:
- org.apache.spark.sql.internal
- 类:
- object SQLConf (此对象记录了Spark SQL的参数)
- 源码方法(只是定义变量、文档注视和默认值,没啥吊用,继续搜)
private[spark] val FILES_MAX_PARTITION_BYTES = ConfigBuilder("spark.files.maxPartitionBytes")
.doc("The maximum number of bytes to pack into a single partition when reading files.")
.version("2.1.0")
.bytesConf(ByteUnit.BYTE)
.createWithDefault(128 * 1024 * 1024)
private[spark] val FILES_OPEN_COST_IN_BYTES = ConfigBuilder("spark.files.openCostInBytes")
.doc("The estimated cost to open a file, measured by the number of bytes could be scanned in" +
" the same time. This is used when putting multiple files into a partition. It's better to" +
" over estimate, then the partitions with small files will be faster than partitions with" +
" bigger files.")
.version("2.1.0")
.bytesConf(ByteUnit.BYTE)
.createWithDefault(4 * 1024 * 1024)
def filesMaxPartitionBytes: Long = getConf(FILES_MAX_PARTITION_BYTES)
- 搜索 filesMaxPartitionBytes 方法,查看方法在何处调用
- 包路径
- org.apache.spark.sql.execution
- 类
- createNonBucketedReadRDD
- 源码方法(详情请看注释哦)
/**
* Create an RDD for non-bucketed reads.
* The bucketed variant of this function is [[createBucketedReadRDD]].
* @param readFile a function to read each (part of a) file.
* @param selectedPartitions Hive-style partition that are part of the read.
* @param fsRelation [[HadoopFsRelation]] associated with the read.
private def createNonBucketedReadRDD(
readFile: (PartitionedFile) => Iterator[InternalRow],
selectedPartitions: Seq[PartitionDirectory],
fsRelation: HadoopFsRelation): RDD[InternalRow] = {
// 获取 maxPartitionBytes,默认128M
val defaultMaxSplitBytes =
fsRelation.sparkSession.sessionState.conf.filesMaxPartitionBytes
// 获取openCostInBytes,默认4M
val openCostInBytes = fsRelation.sparkSession.sessionState.conf.filesOpenCostInBytes
// 获取defaultParallelism,默认200
val defaultParallelism = fsRelation.sparkSession.sparkContext.defaultParallelism
// 获取读取文件的总字节数
val totalBytes = selectedPartitions.flatMap(_.files.map(_.getLen + openCostInBytes)).sum
// 计算平均每个分区的字节数