

Vue原理:Computed

Vue原理:Computed
什么是
computed
呢?要理解
computed
的工作原理,只需要理解下面三个问题
1、
computed
也是响应式的
2、
computed
如何控制缓存
3、依赖的 data 改变了,
computed
如何更新
白话原理:
computed的响应性
不清楚什么是响应式,什么是订阅者watcher?可以先了解Vue响应式原理。
简单的说
你给
computed
设置的
get
和
set
函数,会与
Object.defineProperty
关联起来。
所以 Vue 能监听捕捉到,读取
computed
和 赋值
computed
的操作。
在读取
computed
时,会执行设置的
get
函数,但是并没有这么简单,因为还有一层缓存的操作。如果数据没有被污染,不为脏数据,那将直接从缓存中取值,而不会去执行
get
函数。(什么是脏数据,后文中将会说到)
赋值
computed
时,会执行所设置的
set
函数。这个就比较简单,会直接把 set 赋值给 Object.defineProperty - set。
Computed 如何控制缓存
我们都知道,
computed
是有缓存的,官方已经说明。
计算属性的结果会被缓存,除非依赖的响应式 property 变化才会重新计算。注意,如果某个依赖 (比如非响应式 property) 在该实例范畴之外,则计算属性是 不会 被更新的。
我们为什么需要缓存?假设我们有一个性能开销比较大的计算属性 A,它需要遍历一个巨大的数组并做大量的计算。然后我们可能有其他的计算属性依赖于 A 。如果没有缓存,我们将不可避免的多次执行 A 的
get
函数。大量的计算将导致JS线程被占用,阻塞页面的渲染。
那么在 Vue 中,
computed
是如何判断是否使用缓存的呢?
首先
computed
计算后,会把计算得到的值保存到一个变量(watcher.value)中。读取
computed
并使用缓存时,就直接返回这个变量。当 computed 更新时,就会重新赋值更新这个变量。
TIP:computed 计算就是调用你设置的
get
函数,然后得到返回值。
computed
控制缓存的重要一点是
【脏数据标志位 dirty】
dirty
是
watcher
的一个属性。
当
dirty
为
true
时,读取
computed
会执行
get
函数,重新计算。
当
dirty
为
false
时,读取
computed
会使用缓存。
缓存机制简述
-
一开始每个
computed新建自己的watcher时,会设置 watcher.dirty = true,以便于computed被使用时,会计算得到值
-
当依赖的数据变化了,通知
computed时,会赋值 watcher.dirty = true,此时重新读取computed时,会执行get函数重新计算。
-
computed计算完成之后,会设置 watcher.dirty = false,以便于其他地方再次读取时,使用缓存,免于计算。
依赖的data变化,computed如何更新?
简述Vue响应式原理
computed的本质与data相似。当被使用时,会为其建立订阅者watcher,交给依赖项收集。如:当 A 引用 B 的时候,B 会收集 A 的watcher。
场景设置
现在 页面A 引用了 computed B,computed B 依赖了 data C。
像是这样,A->B->C 的依赖顺序。
那么,当 data C 变化,会发生什么呢?
会是这样吗?
-
通知 computed B 更新,然后 computed B 开始重新计算。
-
接着 computed B 通知 页面A更新,然后重新读取 computed。
一条链式的操作? C -> B -> A 这样的执行顺序吗?
答案是否定的。
其实真正的流程是,data C 开始变化后.......
-
通知 computed B 的 watcher 更新,只会重置 脏数据标志位 dirty =true,不会计算值。
-
通知 页面 A watcher 进行更新渲染,进而重新读取 computed B ,然后 computed B 开始重新计算。
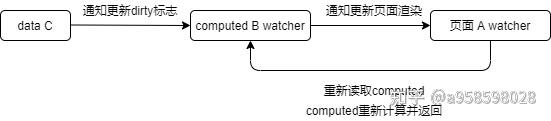
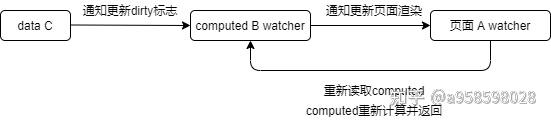
为什么 data C 能通知 页面 A?
data C 的依赖收集器会同时收集到 computed B 和 页面 A 的 watcher。
为什么 data C 能收集到 页面A 的watcher?
在 页面 A 在读取 computed B 的时候,趁机把 页面A 的watcher塞给了 data C ,于是 页面A watcher 和 data C 间接地关联在了一起,于是 data C 就会收集到 页面A watcher。
至于具体的代码是怎么实现的,将会在下文源码分析中讲解。
所以computed 如何更新?
被依赖通知更新后,重置 脏数据标志位 ,页面读取 computed 时再更新值。
白话总结
-
computed 通过 watcher.dirty 控制是否读取缓存。
-
computed 会让
【data依赖】
收集到
【依赖computed的watcher】
,从而 data 变化时,会同时通知 computed 和 依赖computed的地方。
源码分析
Computed初始化
function Vue(){
... 其他处理
initState(this)
...解析模板,生成DOM 插入页面
function initState(vm) {
var opts = vm.$options;
if (opts.computed) {
initComputed(vm, opts.computed);
.....
}在调用 Vue 创建实例过程中,会处理各种选项,其中包括处理 computed。
处理 computed 的方法是 initComputed。
initComputed
function initComputed(vm, computed) {
var watchers = vm._computedWatchers =
Object.create(null);
for (var key in computed) {
var userDef = computed[key];
var getter =
typeof userDef === 'function' ?
userDef: userDef.get;
// 每个 computed 都创建一个 watcher
// watcher 用来存储计算值,判断是否需要重新计算
watchers[key] =
new Watcher(vm, getter, {
lazy: true
// 判断是否有重名的属性
if (! (key in vm)) {
defineComputed(vm, key, userDef);
}在initComputed中,Vue做了这些事情:
- 为每一个computed建立了watcher。
2. 收集所有computed的watcher,并绑定在Vue实例的_computedWatchers 上。
3. defineComputed 处理每一个computed。
下面详细分析Vue在这三步中,具体做了些什么。
1、为每一个computed建立了watcher
computed 到底和 watcher 有什么关系呢?
- watcher保存了 computed 的 getter计算函数。
- watcher保存了 computed 的计算结果。
- 通过 dirty 标志位,控制缓存是否有效。
看下 Watcher 源码构造函数
function Watcher(vm, expOrFn, options) {
this.dirty = this.lazy = options.lazy;
this.getter = expOrFn;
this.value = this.lazy ? undefined: this.get();
};从这段源码中,我们再看 computed 传了什么参数
new Watcher(vm, getter, { lazy: true })于是,我们就具体地知道了 watcher 与 computed 是什么关系了:
- 保存设置的 getter 。
把用户设置的 computed-getter ,存放到 watcher.getter 中,用于后面的计算。
2. watcher.value 保存计算结果
computed 新建 watcher 的时候,传入 lazy: true。 因为 lazy 的原因,在新建watcher实例的时候,会将 watcher.value 赋值为 undefined,而不会立马进行计算。
这里可以算是 Vue 的一个优化,只有你再读取 computed,才会真正开始计算,而不是初始化就开始计算值了。
虽然没有一开始计算,但是计算 value 还是这个 watcher.get 这个方法,来看下源码(已省略部分代码,下面讲其他问题,会更详细展示出来)。
这个方法,其实就是执行 保存的 getter 函数,从而得到计算值。
Watcher.prototype.get = function() {
// getter 就是 watcher 回调
var value = this.getter.call(vm, vm);
return value
};3. 通过 dirty 控制缓存
我们都知道,computed的计算结果是拥有缓存的,而不是每次使用都要重新计算。
在新建 watcher 实例的时候,Vue 还把 lazy 赋值给了 dirty,为什么呢?
因为 lazy 表示一种固定描述,不可改变,表示这个 watcher 需要缓存。
而 dirty 表示缓存是否可用,如果为 true,表示缓存脏了,需要重新计算,否则不用。
dirty 默认是 false 的,而 lazy 赋值给 dirty,就是给一个初始值,表示你控制缓存的任务开始了。
所以, dirty 是真正的控制缓存的关键,而 lazy 只是起到一个开启的作用。
具体,怎么控制缓存,下文会继续说明。
2、收集所有 computed 的 watcher
从源码中,你可以看出为每个 computed 新建watcher 之后,会全部收集到一个对象中,并挂到实例的_computedWatchers 上。
在下文说明的 defineComputed 方法中,会调用 createComputedGetter 方法,使用 Object.defineProperty为每一个computed建立get、set。在 createComputedGetter 中,通过 key 值,从实例的 _computedWatchers ,获取对应的 watcher。
3、defineComputed 处理
这一部分源码,就是 computed 原理的核心所在了。
来看源码
function defineComputed(
target, key, userDef
// 设置 set 为默认值,避免 computed 并没有设置 set
var set = function(){}
// 如果用户设置了set,就使用用户的set
if (userDef.set) set = userDef.set
Object.defineProperty(target, key, {
// 包装get 函数,主要用于判断计算缓存结果是否有效
get:createComputedGetter(key),
set:set
}源码已经被精简处理,但是意思是不变的。
- 使用 Object.defineProperty 为实例上computed 属性建立get、set方法。
2. set 函数默认是空函数,如果用户设置,则使用用户设置。
3. createComputedGetter 包装返回 get 函数。
重点就在 第三点。
在这一步中, 解决了缓存控制问题,并使得 data 与 页面的watcher 关联在了一起。(data与页面watcher有什么关联?前文白话原理中已解释。)
马上呈上 createComputedGetter 源码:
function createComputedGetter(key) {
return function() {
// 获取到相应 key 的 computed-watcher
var watcher = this._computedWatchers[key];
// 如果 computed 依赖的数据变化,dirty 为ture。重新计算,然后更新缓存值 watcher.value
if (watcher.dirty) {
watcher.evaluate();
// 这里是 computed 关联页面watcher的重点,让双方建立关系
if (Dep.target) {
watcher.depend();
return watcher.value
}
缓存控制:
下面这段代码作用就是缓存控制,请往下看
if (watcher.dirty) {
watcher.evaluate()
}- watcher.evaluate() 用来重新计算,更新缓存值,并重置 dirty 为false,表示缓存已更新。
下面是源码
Watcher.prototype.evaluate = function() {
this.value = this.get();
// 执行完更新函数之后,立即重置标志位
this.dirty = false;
};2. 只有 dirty 为 true 的时候,才会执行 evaluate。
所有说通过 控制 dirty 从而控制缓存,但是怎么控制dirty 呢?
举个例子,computed数据A 引用了 data数据B,即A 依赖于 B,所以B 会收集到 A 的 watcher。
当 B 改变的时候,会通知 A 进行更新,即调用 A的watcher.update。
computed的watcher.update源码如下:
Watcher.prototype.update = function() {
if (this.lazy) this.dirty = true;
....还有其他无关操作,已被省略
};当通知 computed 更新的时候,只会把 dirty 设置为 true,不会真正重新计算。再次读取 comptued 时,才会调用 evalute 重新计算。
data数据与页面watcher关联:
data与页面的关联关系,已在前文白话原理中说明。这里再简单说一下。
现有 页面 - P,computed - C,data - D。
1、P 引用了 C,C 引用了 D
2、理论上 D 改变时, C 就会改变,C 则通知 P 更新。
3、实际上 C 让 D 和 P 建立联系,让 D 改变时同时通知 P 更新。那么,computed - C是如何让data - D和页面 - P关联在一起的呢?
没错,就是下面这段代码搞的鬼:
if (Dep.target) {
watcher.depend();
}别看这段代码短,涉及的内容很多,看源码分分钟绕不过来。
来看看 watcher.depend 的源码:
Watcher.prototype.depend = function() {
var i = this.deps.length;
while (i--) {
// this.deps[i].depend();
dep.addSub(Dep.target)
};这段的作用:
(依然使用上面的例子 PCD 代号来说明)
让 D 的依赖收集器收集到 Dep.target,而 Dep.target 当前是什么?
没错,就是 页面 的 watcher !
所以这里,D 就会收集到 页面的 watcher 了,所以就会直接通知页面 watcher。
为什么 Dep.target 是 页面 watcher?
因为在watcher的get方法中,缓存了Dep.target。
Watcher.prototype.get = function() {
// 改变 Dep.target
pushTarget()
// getter 就是 watcher 回调
var value = this.getter.call(this.vm, this.vm);
// 恢复前一个 watcher
popTarget()
return value
Dep.target = null;
var targetStack = [];
function pushTarget(_target) {
// 把上一个 Dep.target 缓存起来,便于后面恢复
if (Dep.target) {
targetStack.push(Dep.target);
Dep.target = _target;