将下载好的ggml-model-f16.bin文件考入到刚才新建的文件夹“ai”内。
新建一个扩展名为.bat的文件(直接建个记事本,将扩展名改一下就行)。
右键编辑新建的.bat文件输入下图的文本,保存运行即可。
"main.exe" --ctx_size 2048 --temp 0.7 --top_k 40 --top_p 0.5 --repeat_last_n 256 --batch_size 1024 --repeat_penalty 1.17647 --model "ggml-model-f16.bin" --n_predict 2048 --color --interactive --reverse-prompt "User:" --prompt "Text transcript of a never ending dialog, where User interacts with an AI assistant named ChatLLaMa. ChatLLaMa is helpful, kind, honest, friendly, good at writing and never fails to answer User's requests immediately and with details and precision. There are no annotations like (30 seconds passed...) or (to himself), just what User and ChatLLaMa say aloud to each other. The dialog lasts for years, the entirety of it is shared below. It's 10000 pages long. The transcript only includes text, it does not include markup like HTML and Markdown."
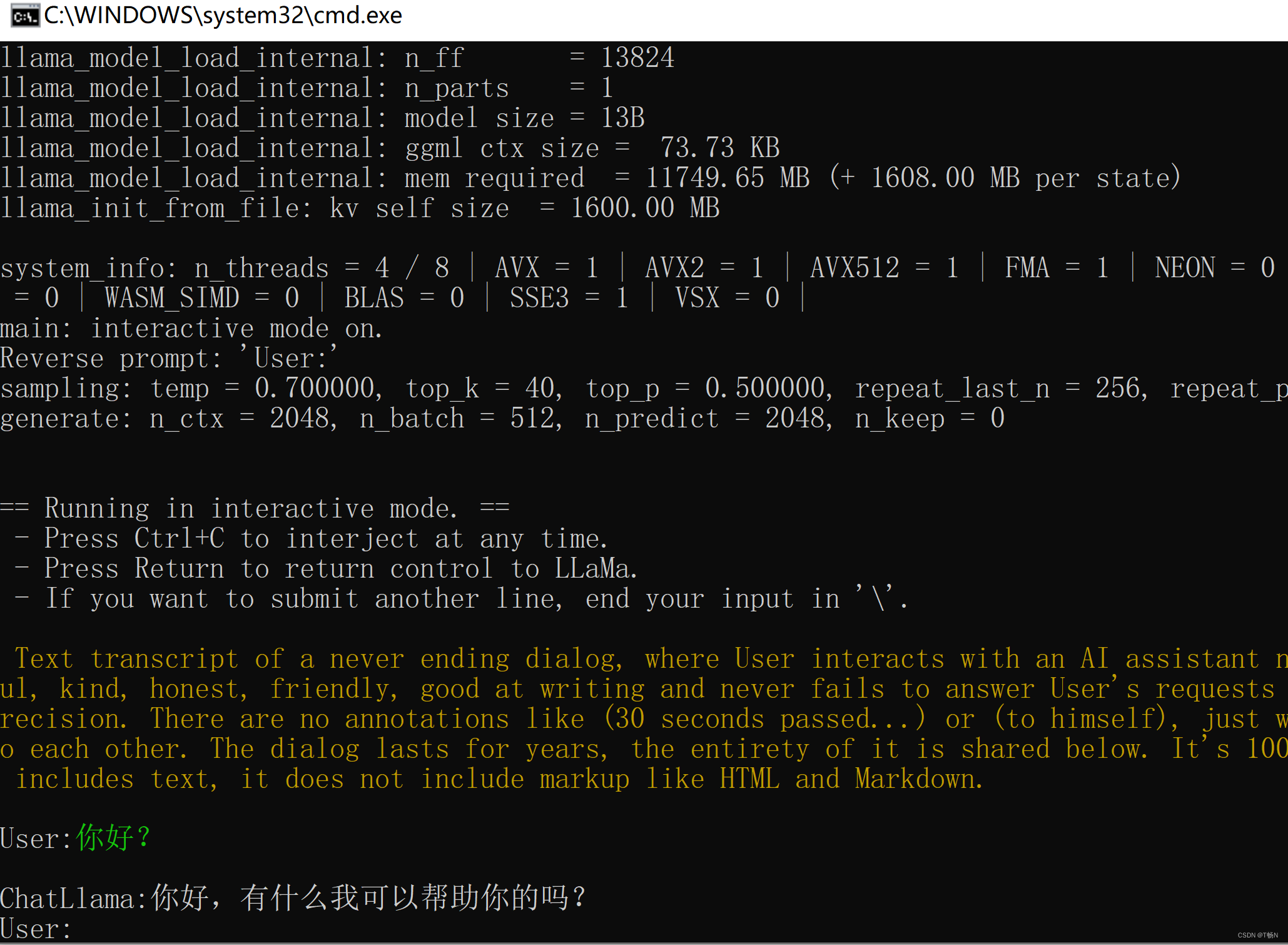
运行效果如下图
Alpaca 13b微调的模型文件较大,而且运行很占内存,一些问题回答的不是很完美。
注意:Vicuna和Alpaca都是基于LLaMa的,不能用于商用。
Vicuna号称"小羊驼",Vicuna是基于ShareGPT的7万条对话数据对LLaMA微调的模型,13b模型的效果据说可达到ChatGPT3.5 92%的效果,部分问答的评分甚至超过了ChatGPT3.5。里面vicuna-13B-1.1-GPTQ-4bit-32g.GGML.bin和vicuna-13B-1.1-GPTQ-4bit-128g.GGML.bin。下载哪个都可以,我用的是vicuna-13B-1.1-GPTQ-4bit-128g.GGML.bin。
随着ChatGPT为代表的预训练大模型带来新一轮人工智能(AI)热潮爆发,继百度、阿里、360之后,又一家大厂推出GPT大模型产品。
钛媒体App获悉,4月10日,AI 公司商汤科技正式发布全新“日日新SenseNova”大模型体系,以及自研的中文语言大模型应用平台“商量”(SenseChat),参数量达千亿,可实现文本生成、图像生成、多模态内容生成等能力与场景应用。
商汤科技董事长兼CEO徐立表示,上述这些生成式人工智能(AIGC)产品将在医疗、短视频、教育、营销以及开发等产业领域应用落地。
商汤科技联合创始人、首席科学家王晓刚表示,目前已经有一些合作伙伴和客户开始内测其产品。未来,商汤版的GPT主要面向企业端(B2B)业务。此外,商汤“日日新SenseNova”大模型体系已全面支持了智能汽车、智慧生活、智慧商业、智慧城市等业务板块,而且商汤将向客户提供涵盖图片生成、自然语言对话、视觉推理和标注服务等API接口。
事实上,自2022年12月开始,美国OpenAI公司推出的 AI 产品ChatGPT以及背后的GPT大模型,已经引发了一场 AI 新浪潮。
但 AI 技术的终极目标 通用人
高质量的数据,很多人都意识到了高质量数据对AI模型的重要性,但为什么没有中文高质量数据集呢?
(1)没人。但是清洗数据是费时费力的苦活累活,博士、研究员们可没有时间和耐心去做,有那个时间为什么不找个清洗好的公开数据集,调调参数,搞几个trick,刷刷SOTA,发几篇顶会来的惬意。所有数据标注清洗都交给数据标注公司,或者低年级的学生去做,他们对数据完成什么任务,数据和任务关系,怎样的数据能训练出好模型知之甚少,怎么能建设出高质量数据集呢?数据集建设必须由训练模型的研究员或者工程师亲自参与,反复迭代。大模型时代,好数据比好模型重要N个数量级。
(2)没利益。做科研的等着别人公开数据集,商业化公司又不愿意烧钱去build数据集。大多数科研人员连爬虫都不愿意写,反正有那么多公开数据集等着我去刷榜呢,为什么要做数据集。辛辛苦苦爬了一些数据,标了一些数据,赶紧发个文章领域内第一个XXX数据集,然后大家写文章引用起来。高质量的数据集和质量一般的数据集有差别吗?
训练大模型的能力。现在国内好多机构都在发布大模型,可真