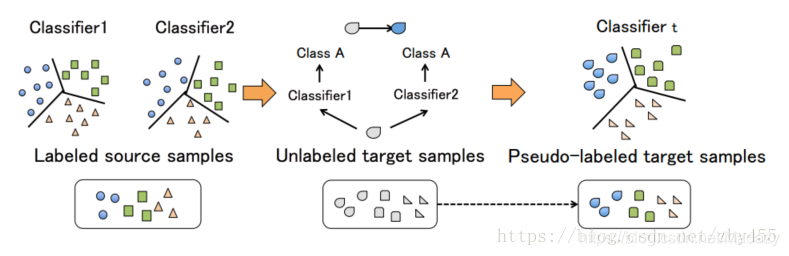
Tri-training(周志华,2005, 无监督学习领域最经典、知名度最高的做法)利用三个分类器按照“少数服从多数”的原则来为无标签的数据生成伪标签,但这种方法不适用于无标签的目标域与有标签的源数据不同的情况。
ATDA要解决的问题是:源数据有标签,目标域没有标签,目标域与源域属于不同的域,如何生成目标域的表达?
需要一个与Tri-training或者Co-training有所不同的非对称方法—>ATDA
核心: 非对称地使用三个神经网络,非对称的意思是说,与Tri-training不同,其中的两个来为无标签数据生成伪标签,还有一个来学习伪标签的特征表达。
同时这也属于迁移学习的范畴,是一种Feature Base的Transfer Learning。
迁移学习
首先讲CNN的发展,但是这些神经网络面临一个必然的共同问题:当测试数据的分布和训练数据的
分布相同
时,神经网络表现优秀,但是神经网络在测试时并不能识别来自
不同分布
的样本。(因为传统的神经网络训练的本质就是在训练集上对目标进行拟合,这种问题是难免而且必然的)
过去的那些半监督学习方法旨在通过最小化域之间的差异以及源域上的category loss来获得域不变特征(domain-invariant features)。理论上,一般不存在在目标域与源域都表现好的分类器。直接对目标域的判别特征进行学习是很困难的,所以从
伪标签学习
入手。
本文针对无监督的域适应提出了一种Tri-train的方法。
-
Method & Core
方法架构图:
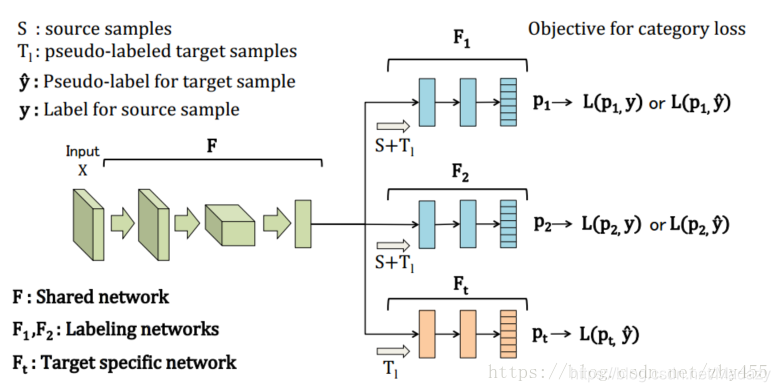
F为共享的特征抽取层,F1、F2为生成伪标签的两个分类器,Ft为学习目标域的特征表达的分类器。
Loss Function:
组成部分为(F1+F)与y的交叉熵,(F2+F)与y的交叉熵,为了保证两个分类器尽量从
不同的视角
来训练,加入正则项 W1
T
*W2,W1、W2为全链接层的权重。这个思想就是在优化Loss Function的过程中,用W1
T
*W2的大小进行约束,会让W1、W2
尽量正交
,收敛于
不同的局部最小值
。
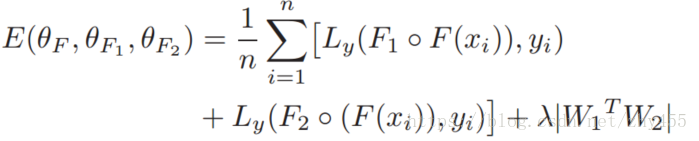
1.首先,用源数据S训练F1、F2、Ft,其中F1、F2的训练用上述的Loss Function,Ft用其与y的交叉熵(这里我的理解相当于一个初始化)。
2.训练完之后用F1、F2 为目标域生成伪标签,有两个条件,当两个分类器生成的标签一致的时候该标签成立,或者某一个分类器生成的标签的置信度大于一定的阈值如0.95时成立。其目的在于让生成的伪标签
尽量真
,分类器需要达到一定的置信度。为了缓和在伪标签上的过拟合的问题,其中用到了重采样等方法。生成伪标签的训练集。
-
用伪标签的训练集训练Ft。
整体训练过程如下:

Asymmetric Tri-training for Unsupervised Domain Adaptation (2017 ICML)论文笔记AbstractTri-training(周志华,2005, 无监督学习领域最经典、知名度最高的做法)利用三个分类器按照“少数服从多数”的原则来为无标签的数据生成伪标签,但这种方法不适用于无标签的目标域与有标签的源数据不同的情况。ATDA要解...
用USB2.0接口移动硬盘盒与一块20GB容量的笔记本硬盘(IC25N020
ATDA
04),组成了一块移动硬盘,将该移动硬盘插入电脑的USB前置口上,系统提示为“有新设备插入,但无法正常安装,可能无法正常使用”,“设备管理器”和“资源管理器”中均无法发现移动硬盘的踪迹。观察移动硬盘,发现不停出现“咔嗒”声,指示灯随着声响周期性地亮暗变化,怀疑前置USB接口供电不足,将移动硬盘转接到主板USB接口上,现象致,使用PS/2辅助取电也不行。试验多次,偶尔能在“设备管理器”中发现该移动硬盘,但无法正常使用。
硬盘及硬盘盒均在商家处检测过,没有任何问题,为什么组合起来却无法使用呢?只好先用替换法了
1、生成模型
算法
(Generate semi-supervised models)
思想如下:假设一个模型,其分布满足:p(x ,y)=p(y) p(x | y)。其中,p(x | y)是已知的条件概率分布。那么大量未经标记数据的联合分布就可以被确定。生成模型
算法
的流程图如下。
半
监督
学习
方法可以对同时含有已标记的和未标记的数据集进行聚类,然后通过聚类结果中,每一类中所含有的任何一个已标记数据...
1、
监督
学习
监督
学习
:训练样本集不仅包含样本,还包含这些样本对应的标签,即样本和样本标签成对出现。
监督
学习
的目标是从训练样本中
学习
一个从样本到标签的有效映射,使其能够预测未知样本的标签。
监督
学习
是机器
学习
中最成熟的
学习
方法,代表性的
算法
包括神经网络、支持向量机(SVM)等。
2、无
监督
学习
无
监督
学习
:只能利用训练样本的数据分布或样本间的关系将样本划分到不同的聚类簇或给出样本对应的低维结构。- 因此,无
监督
学习
常被用于对样本进行聚类或降维,典型的
算法
包括尺均值聚类和主成
Asymmetric
Tri-training
for
Unsupervised
Domain
Adaptation
深层模型需要大量的标注样本进行训练,但是收集不同领域的标注样本是代价昂贵的。
无
监督
领域自适应:利用标注的有标注的源样本和目标样本训练一个在目标域上能够很好地work的分类器。
存在的问题虽然很多的方法去对齐源域和目标域样本的分布,但是简单地匹配分布不能确保目标域上的准确率。
为了
学习
目标域的判别性的表示,假设人工标记的目标样本可以得到很好的表示。
==
Tri-training
:==
@[TOC](【论文笔记】
Asymmetric
Tri-training
for
Unsupervised
Domain
Adaptation
))
论文地址:http://cn.arxiv.org/pdf/1702.08400v3
代码地址:https://github.com/corenel/pytorch-
atda
#pytorch-
atda
ATDA
解决的问题: 源数据有类别标签,...
域自适应尝试将从源域获得的知识传送到目标域,即测试数据所在的域。主要的挑战在于源域和目标域之间的分布差异。大多数现有工作通常通过最小化分布距离来努力
学习
域不变表示,例如MMD和最近提出的生成对抗网络(GAN)中的鉴别器。
遵循GAN的类...
特征交叉是数据特征的一种处理方式,通过特征组合的方式增加特征的维度,以求得更好的训练效果。
在实际场景中,我们常常遇到这要的情况,线性分类起无法在如下样本中(无法画一条直线将下列黄点和蓝点分开),所以特征组合是一种让线性模型
学习
到非线性特征的方式:
例如在广告模型中用到了大量的特征组合,因为LR是广告推广中最常用的模型,但...

