

如何用python提取指定内容?
关注者
15
被浏览
36,106
5 个回答


这件事情既简单,又不简单。
说它简单,是因为这里面并没有涉及到太深入、太复杂的知识,都比较基础。
说它不简单,是因为这是一个系统化的问题,并不是像往常读一个表格、画一幅图这种单点的事情,对于没有太多实践经验的同学就比较有挑战。
想要解决这个问题,需要首先把这个事情拆解一些,其实就包括几个步骤:
- 读取文件
- 处理文本
- 统计分析
具体来介绍一下。
首先是 读取文件 ,这一点是不言而喻的,想要统计不同文件的相似性,首先就要把 非结构化的文本转化成结构化的数据 。这就需要把涉及到的不同文件类型罗列一下,例如,PDF、Word、Excel等等,针对不同文件类型Python都有不同的工具包和调用方式,具体的下面会详细展开介绍。
其次是 处理文本 ,通过不同的工具包把各种各样的非结构化数据读到了内存里,接下来就需要对这个粗糙的数据进行更加细致的处理,这种目前比较成熟了,可以选择一款即可,例如,jieba、SnowNLP、PkuSeg、HanLP等等。这些工具包可以把文本内容进行分词处理,处理成更加规范可理解的数据,用起来很简单,一般情况下三五行代码就可以解决,本文不多赘述。
最后是 统计分析 ,相似性问题其实非常简单,例如常用的欧式距离就是衡量相似性的一个关键指标,用通俗语言描述就是计算两个向量之间的平方差,回到文本相似性这个问题上,可以有两种方式:
第一种 :通过前面步骤分词得到的词汇,统计高频出现的TopN,然后比对不同文本之间高频词是否具有相似性,相同的有多少,不同的有多少,这种比较简单。
第二种 :自然语言向量化,把处理后的文本内容进行向量化,这样就很方便数学运算了,可以把文本相似性问题转化成计算两个向量之间欧式距离的问题。
这一种方法网络上也有很多介绍,感兴趣的可以选择合适自己的。
下面对于第一步读取文件部分详细展开阐述一下。
读取PDF
Python中用于读取PDF的工具包很多,例如, pdfminer、PyPDF2 ,以PyPDF2为例,它能够对PDF文件进行 分割 、 合并 、 裁剪 和 转换页面 。
另外,它还可以对PDF文件添加自定义数据、水印、密码,也可以从PDF文件中检索出文本和元数据。
安装
使用pip直接安装:
$ pip install PyPDF2提取PDF内容
使用非常简单,几行代码即可完成:
from PyPDF2 import PdfReader
reader = PdfReader("example.pdf")
page = reader.pages[0]
print(page.extract_text())读取Word
这里需要用到docx工具包,直接上代码:
import docx
doc = docx.Document("zen_of_python.docx")
# 逐段读取
text = [p.text for p in doc.paragraphs]
print(text)
# 逐表读取
for table in doc.tables:
for row in table
.rows:
for cell in row.cells:
print(cell.text)读取Excel
读取Excel需要用到xlrd,看一下代码:
import xlrd
wb = xlrd.open_workbook('test.xlsx')
worksheet = wb.sheet_by_index(0)
# 根据行、列读取数据
print(worksheet.cell_value(0, 0))
# 读取整行数据
print(worksheet.row_values(0))上面以PDF、Word、Excel这三种比较常用的文件介绍一下读取方式,其他的基本一样,通过调工具包几行代码即可实现,读取之后剩余的就是前面提到的剩余两步,文本处理、统计分析,前面也提供了方法和工具包,感兴趣的可以摸索一下。
推荐阅读
hello,大家好,我是Jackpop,重点大学本科毕业后保送到哈工大 计算数学 专业读研,有多年国内头部互联网、IT公司工作经验,先后从事过计算机视觉、 推荐系统 、后端、数据等相关工作。如果同学们在 升学考研、职业规划、高考志愿、简历优化、技术学习 等方面有困惑,欢迎大家前来咨询!

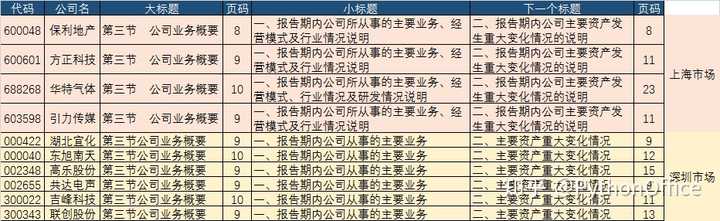
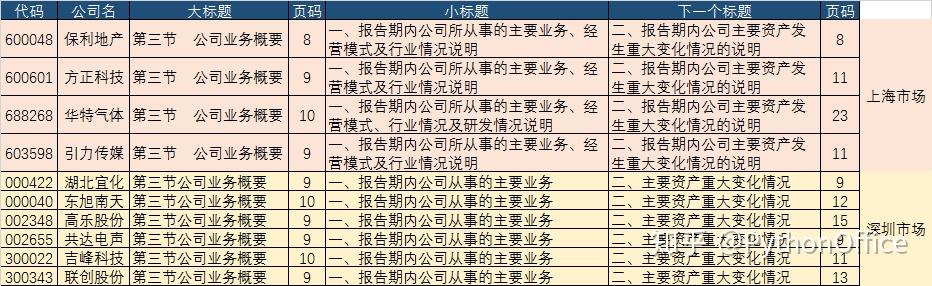
要求批量从上市公司年报中截取公司从事的主要业务信息,以便进行后续的分析。首先我们要分析一下上市公司年报的结构,及目标信息所在位置。一般上市公司的年报都是公开的,可随意下载。其格式一般是PDF。年报内容包含的板块几乎相同,只是深圳市场与上海市场略有区别。随机挑选了10家上市公司的年报(如下图)。可见,公司业务都位于“第三节公司业务概要”,只是上海市场的年报,“第三节”后有空格。其所在页基本在8,9,10页。“第三节”里的第一个小标题,两个市场也有点不同。主要业务介绍完后,接下来都是介绍“主要资产重大变化情况”,这部分及以后的内容都不是我们想要的。因此,打算确定关键词“公司业务概要”及“重大变化情况”,作为文字截取的起始关键词。当然,如果年报中还有其它内容也涉及到这两个词,就会造成干扰。保险起见,在PDF文档内搜索一下,运气不错,这两个关键词在文档中是唯一的,也就是只在这两个地方出现。那就可以放心干了。
以下,先随便找一家上市公司的年报来测试一下。先导入
pdfplumber
模块,用于提取Pdf文件中的文字(也可以用PyPDF2模块,但读取中文容易出错,因此放弃)。然后设定关键词“重大变化情况”,作为停止搜索标志(这个词后面的内容不是我们想要的)。再打开PDF文件,从第7页开始提取文字,26页终止(因为绝大部分年报的“主要业务”内容在8~15页,有个别到23页了)。将每页的文字信息存入
data
字典。再用
if
语句设定一个终止程序,即当关键词“重大变化情况”出现在当页的内容中时,就停止后续的读取了,因为后续读取到的内容已经不是我们想要的了。这样可以节省时间。打个比方,如果我们要的内容在8~9页,程序只会提取7~9页的内容,后面就不会再提取了。
#获取年报中的“主要业务”信息
import pdfplumber
file = r"年报\湖北宜化:2019年年度报告(更新后).PDF"
data = []
key_words = "重大变化情况"
with pdfplumber.open(file) as p:
for i in range(6,26): #公司主要业务主要年报的在8~23页范围内
page = p.pages[i] #选页
page_text = page.extract_text() #提取文字
data.append(page_text) #将提取的文字加入列表
if key_words in page_text: #到结束关键词即结束抓取信息,避免浪费时间
break # 终止for循环得到的结果如下。
['湖北宜化化工股份有限公司2019年年度报告全文 \n七、境内外会计准则下会计数据差异 \n1、同时按照国际会计准则与按照中国会计准则披露的财务报告中净利润和净资产差异情况 \n□ 适用 √ 不适用 \n公司报告期不存在按照国际会计准则与按照中国会计准则披露的财务报告中净利润和净资产差异情况。 \n2、同时按照境外会计准则与按照中国会计准则披露的财务报告中净利润和净资产差异情况 \n□ 适用 √ 不适用 \n公司报告期不存在按照境外会计准则与按照中国会计准则披露的财务报告中净利润和净资产差异情况。 \n八、分季度主要财务指标 \n单位:元 \n 第一季度 第二季度 第三季度 第四季度 \n营业收入 3,280,715,538.58 3,940,106,977.87 3,286,217,673.93 4,152,984,706.94 \n归属于上市公司股东的净利润 28,223,201.47 22,155,745.19 62,271,924.32 51,743,040.67 \n归属于上市公司股东的扣除非经\n-93,350,144.91 -42,100,593.21 -202,287,156.77 -329,055,365.40 \n常性损益的净利润 \n经营活动产生的现金流量净额 198,141,607.49 685,472,300.66 680,366,762.21 689,889,725.55 \n上述财务指标或其加总数是否与公司已披露季度报告、半年度报告相关财务指标存在重大差异 \n□ 是 √ 否 \n九、非经常性损益项目及金额 \n√ 适用 □ 不适用 \n单位:元 \n项目 2019年金额 2018年金额 2017年金额 说明 \n非流动资产处置损益(包括已计提资产减\n423,305,854.77 819,164,874.05 -148,176,828.59 \n值准备的冲销部分) \n计入当期损益的政府补助(与企业业务密\n切相关,按照国家统一标准定额或定量享 292,291,555.33 59,799,910.27 156,746,657.96 \n受的政府补助除外) \n计入当期损益的对非金融企业收取的资金\n211,908,304.15 0.00 4,208,625.00 \n占用费 \n企业取得子公司、联营企业及合营企业的\n投资成本小于取得投资时应享有被投资单 0.00 0.00 \n位可辨认净资产公允价值产生的收益 \n除同公司正常经营业务相关的有效套期保\n-1,443,236.14 0.00 42,586,751.93 \n值业务外,持有交易性金融资产、衍生金\n7 ',
'湖北宜化化工股份有限公司2019年年度报告全文 \n融资产、交易性金融负债、衍生金融负债\n产生的公允价值变动损益,以及处置交易\n性金融资产、衍生金融资产、交易性金融\n负债、衍生金融负债和其他债权投资取得\n的投资收益 \n对外委托贷款取得的损益 105,874,140.72 \n除上述各项之外的其他营业外收入和支出 13,671,478.12 3,044,945.90 -55,115,210.74 \n其他符合非经常性损益定义的损益项目 0.00 -392,052.00 \n减:所得税影响额 145,882,732.27 149,304,784.95 -14,917,730.28 \n 少数股东权益影响额(税后) -37,335,947.97 6,989,133.39 7,131,340.90 \n合计 831,187,171.93 831,589,952.60 7,644,332.94 -- \n对公司根据《公开发行证券的公司信息披露解释性公告第1号——非经常性损益》定义界定的非经常性损益项目,以及把《公\n开发行证券的公司信息披露解释性公告第1号——非经常性损益》中列举的非经常性损益项目界定为经常性损益的项目,应\n说明原因 \n□ 适用 √ 不适用 \n公司报告期不存在将根据《公开发行证券的公司信息披露解释性公告第1号——非经常性损益》定义、列举的非经常性损益\n项目界定为经常性损益的项目的情形。 \n8 ',
'湖北宜化化工股份有限公司2019年年度报告全文 \n第三节公司业务概要 \n一、报告期内公司从事的主要业务 \n (一)报告期内公司从事的主要业务、主要产品及用途、经营模式、业绩驱动因素 \n 公司的主营业务是化肥产品(尿素、磷酸二铵等)、化工产品(聚氯乙烯、烧碱等)的生产、销售。 \n 尿素和磷酸二铵主要用于农业肥料使用,用以提高土壤肥力,促进作物的生长,提高农业生产力。尿素也可用于工业\n和医用等领域。聚氯乙烯主要应用于生产各种型材、板材、管材、硬片、电线电缆等行业。烧碱用于造纸、肥皂、染料、人\n造丝、制铝、石油精制、煤焦油产物的提纯,以及食品加工、木材加工及机械工业等方面。 \n 公司属于制造业,拥有独立完整的生产经营系统。公司化肥、化工生产采用连续不间断方式运行;公司主要原材料招\n标外购;公司销售采用经销商结合直销并引入电子商务销售模式。报告期内公司主要经营模式无重大变化。 \n 生产装置的工艺技术状况和生产管理水平决定公司的直接生产成本,是公司业绩驱动重要因素。 \n (二)报告期内所属行业的发展阶段、周期性特点及公司所处行业地位 \n 公司所从事的化肥、化工行业已处于成熟期,市场竞争激烈。化肥产品具有明显的淡旺季,一般12月至次年2月为淡\n季,春秋季为旺季。2019年,公司主导产品磷酸二铵、烧碱、聚氯乙烯价格经历2018年的高点后回落,尿素产品全年市场价\n格较2018年有所上涨,但受冬季天然气受限停产影响,2019年公司尿素生产时间仅有9个月。公司的磷酸二铵、气头尿素的\n市场竞争力行业领先,聚氯乙烯、烧碱装置的盈利水平目前居于国内同行业中上游水平。 \n二、主要资产重大变化情况 \n1、主要资产重大变化情况 \n主要资产 重大变化说明 \n股权资产 无重大变化 \n固定资产 无重大变化 \n无形资产同比下降50%,系本期处置子公司雷波县华瑞矿业有限公司、贵州新宜矿\n无形资产 \n业(集团)有限公司控制权导致采矿权、土地使用权减少所致。 \n在建工程 无重大变化 \n其他非流动资产下降90.5%系本期执行新金融工具准则将委托贷款42.75亿元调至\n其他非流动资产 \n债权投资科目所致。 \n债权投资增长100%,系本期执行新金融工具准则将委托贷款42.75亿元调至本科目\n债权投资 \n所致 \n2、主要境外资产情况 \n√ 适用 □ 不适用 \n资产的具体 保障资产安 境外资产占 是否存在重\n形成原因 资产规模 所在地 运营模式 收益状况 \n内容 全性的控制 公司净资产 大减值风险 \n9 ']
然后,我们就用开始关键词“公司业务概要”和结束关键词“重大变化情况”来截取二者之间的文字。先定义一个文字截取函数,传入起始关键词,及待处理的字符串。通过
find()
方法确定起始关键词对应的位置索引,然后截取二者之间的字符。
#从字符串中提取指定首尾的文字
def Get_text(start_str, end_str, source_str):
start = source_str.find(start_str) #找到开始关键词对应的位置索引
if start >= 0:
start += len(start_str)
end = source_str.find(end_str, start)#找到结束关键词对应的位置索引
if end >= 0:
return source_str[start:end].strip() #截取起始位置之间的字符
#将数据列表`data`转换成一个大字符串
source_str = "".join(data)
#截取文字
start_str = "公司业务概要"
end_str = "重大变化情况"
text_wanted = Get_text(start_str, end_str, source_str)
text_wanted
'一、报告期内公司从事的主要业务 \n (一)报告期内公司从事的主要业务、主要产品及用途、经营模式、业绩驱动因素 \n 公司的主营业务是化肥产品(尿素、磷酸二铵等)、化工产品(聚氯乙烯、烧碱等)的生产、销售。 \n 尿素和磷酸二铵主要用于农业肥料使用,用以提高土壤肥力,促进作物的生长,提高农业生产力。尿素也可用于工业\n和医用等领域。聚氯乙烯主要应用于生产各种型材、板材、管材、硬片、电线电缆等行业。烧碱用于造纸、肥皂、染料、人\n造丝、制铝、石油精制、煤焦油产物的提纯,以及食品加工、木材加工及机械工业等方面。 \n 公司属于制造业,拥有独立完整的生产经营系统。公司化肥、化工生产采用连续不间断方式运行;公司主要原材料招\n标外购;公司销售采用经销商结合直销并引入电子商务销售模式。报告期内公司主要经营模式无重大变化。 \n 生产装置的工艺技术状况和生产管理水平决定公司的直接生产成本,是公司业绩驱动重要因素。 \n (二)报告期内所属行业的发展阶段、周期性特点及公司所处行业地位 \n 公司所从事的化肥、化工行业已处于成熟期,市场竞争激烈。化肥产品具有明显的淡旺季,一般12月至次年2月为淡\n季,春秋季为旺季。2019年,公司主导产品磷酸二铵、烧碱、聚氯乙烯价格经历2018年的高点后回落,尿素产品全年市场价\n格较2018年有所上涨,但受冬季天然气受限停产影响,2019年公司尿素生产时间仅有9个月。公司的磷酸二铵、气头尿素的\n市场竞争力行业领先,聚氯乙烯、烧碱装置的盈利水平目前居于国内同行业中上游水平。 \n二、主要资产'
以上,就把想要的内容基本提取出来了。但最后那个几个字“二、主要资产”不是我们要的,因此需要将其去除。先将以上字符串
text_wanted
按照换行符“\n”进行分割,在砍掉最后一个元素,即可得到最终想要的字符串。
final_text = text_wanted.split("\n")[:-1]
final_text
['一、报告期内公司从事的主要业务 ',
' (一)报告期内公司从事的主要业务、主要产品及用途、经营模式、业绩驱动因素 ',
' 公司的主营业务是化肥产品(尿素、磷酸二铵等)、化工产品(聚氯乙烯、烧碱等)的生产、销售。 ',
' 尿素和磷酸二铵主要用于农业肥料使用,用以提高土壤肥力,促进作物的生长,提高农业生产力。尿素也可用于工业',
'和医用等领域。聚氯乙烯主要应用于生产各种型材、板材、管材、硬片、电线电缆等行业。烧碱用于造纸、肥皂、染料、人',
'造丝、制铝、石油精制、煤焦油产物的提纯,以及食品加工、木材加工及机械工业等方面。 ',
' 公司属于制造业,拥有独立完整的生产经营系统。公司化肥、化工生产采用连续不间断方式运行;公司主要原材料招',
'标外购;公司销售采用经销商结合直销并引入电子商务销售模式。报告期内公司主要经营模式无重大变化。 ',
' 生产装置的工艺技术状况和生产管理水平决定公司的直接生产成本,是公司业绩驱动重要因素。 ',
' (二)报告期内所属行业的发展阶段、周期性特点及公司所处行业地位 ',
' 公司所从事的化肥、化工行业已处于成熟期,市场竞争激烈。化肥产品具有明显的淡旺季,一般12月至次年2月为淡',
'季,春秋季为旺季。2019年,公司主导产品磷酸二铵、烧碱、聚氯乙烯价格经历2018年的高点后回落,尿素产品全年市场价',
'格较2018年有所上涨,但受冬季天然气受限停产影响,2019年公司尿素生产时间仅有9个月。公司的磷酸二铵、气头尿素的',
'市场竞争力行业领先,聚氯乙烯、烧碱装置的盈利水平目前居于国内同行业中上游水平。 ']将以上字符串写入txt文件,并按公司名称命名保存。写入的txt文件结果如下。
#定义写入txt的函数
def To_txt(filename, final_text):#filename为写入文件的路径,data为要写入数据列表.
file = open(filename + '.txt','a')
file.write(filename + "\n")
for i in range(len(final_text)):
text = final_text[i]
if i != len(final_text)-1: #判断是否最后一个元素